
Three lessons that helped us nearly triple our recurring revenue from $1M to $2.7M (with $0 in funding)
Back in October, 2018, we reached a big milestone at Gruntwork of $1M in annual recurring revenue (ARR). Today, a little over a year later, we’ve grown to roughly $2.7M ARR. And we’ve done all of this with $0 in funding. In this blog post—the second in our year-in-review series—I’d like to highlight a few of the key lessons that helped us get here:
- Listen to the data: how we used A/B testing to double conversions.
- Listen to the team: how we had to deliberately design a process to make communication work in a 100% distributed company.
- Listen to the customers: how we changed our product management process to help us prioritize features that moved the needle.
Listen to the data
Throughout most of 2018, Gruntwork was growing quickly: we doubled our revenue, tripled the size of the team, and signed some major customers. However, at the beginning of 2019, things seemed to slow down. I say “seemed” because we weren’t sure: we had a couple slower months of sales in Q1, and someone had a hunch that something was wrong (more on this hunch later), but was it just a fluke, or a sign that there was really something wrong? To answer this question, we had to turn to the data.
The sales funnel
The first step was to understand our sales funnel, which is the entire process someone goes through to become a Gruntwork customer. Here’s a rough picture of what our funnel looks like:
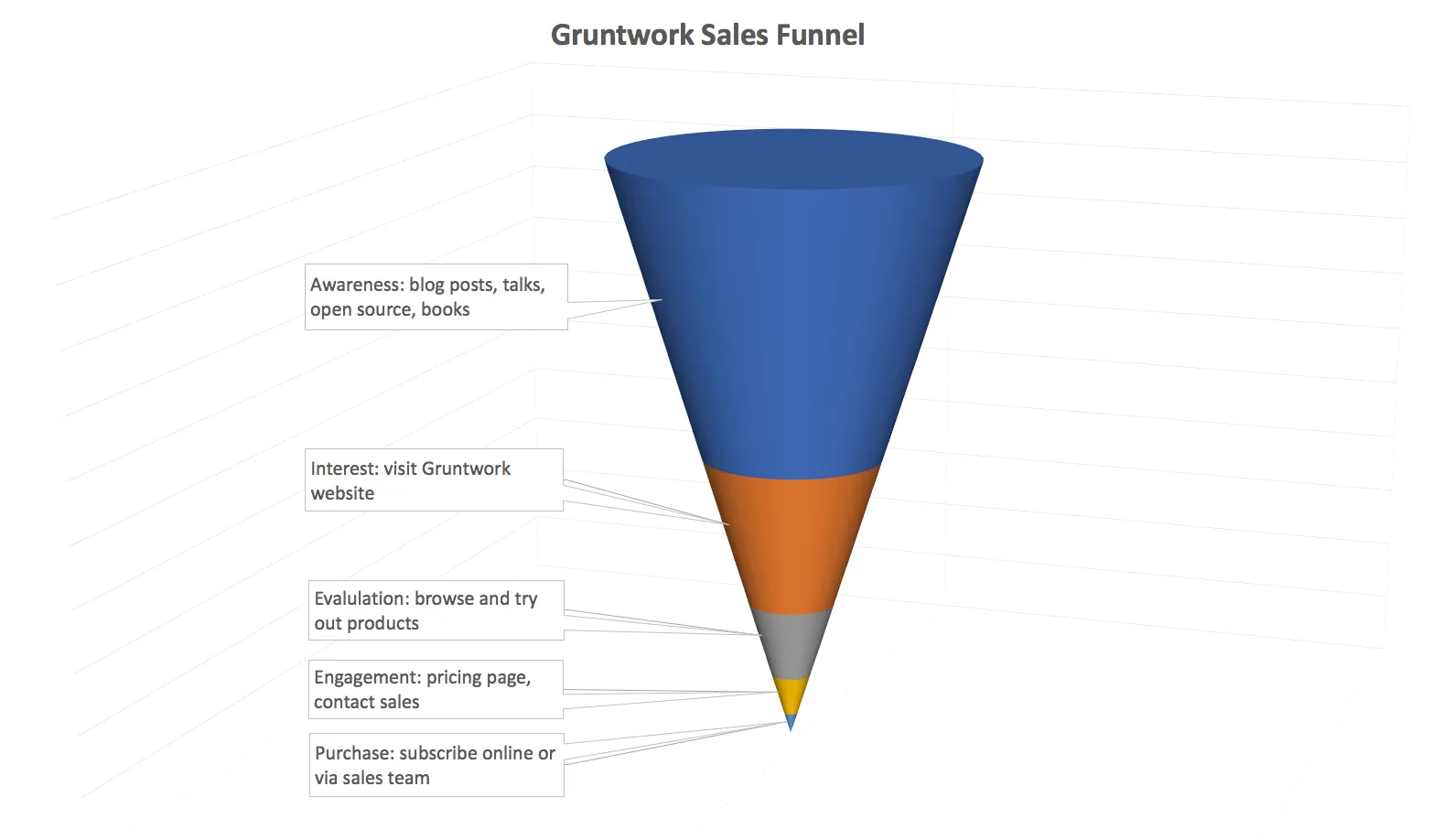
- Awareness: Most people discover Gruntwork through the content we publish, such as our blog posts, deployment guides, talks, open source, and books.
- Interest: Some percentage of the people who see that content will visit the Gruntwork Website.
- Evaluation: Some percentage of the website visitors will start learning about and trying out our products, including our library of reusable, battle-tested, production-grade infrastructure code.
- Engagement: Some percentage of those who evaluate the product will head over to our pricing page or contact sales to start thinking about if they want to make a purchase.
- Purchase: Some percentage of those engaged visitors will subscribe via our online checkout form or by working with our sales team.
Screen recordings
To try to get some hint as to where things were going wrong in this funnel, we used HotJar to record what was happening on the Gruntwork website, and ended up with hundreds of recordings that all exhibited a similar pattern:

Here’s what the recording is showing:
- A user lands on the Gruntwork home page.
- The user clicks one of the red “Get Started” call-to-action (CTA) buttons that we had all over the site (in the nav, at the end of each page, etc).
- The user ends up on the pricing page.
- The user leaves (bounces).
Did you catch the problem? There’s an entire step in the funnel missing! Our website was encouraging users to go straight from Interest (land on Gruntwork website) to Engagement (look at pricing and make a purchase decision), without any Evaluation (learn about and try the product) in between. In other words, our website visitors were being shown a price tag before they had any idea what product we were offering, so it’s no surprise that many of them bounced immediately.
As it turns out, the big red “Get Started” CTA was part of a redesign we had released recently, and we were learning the hard way that it was having some unintentional consequences. But just how bad was it? How much of an impact was this really having?
The data
To answer that question, we dug into our Google Analytics data to understand the website metrics, plus our Salesforce data to understand the sales metrics, and when we compared the data from Q1 2019 to the last several quarters of 2018, here’s what we found:
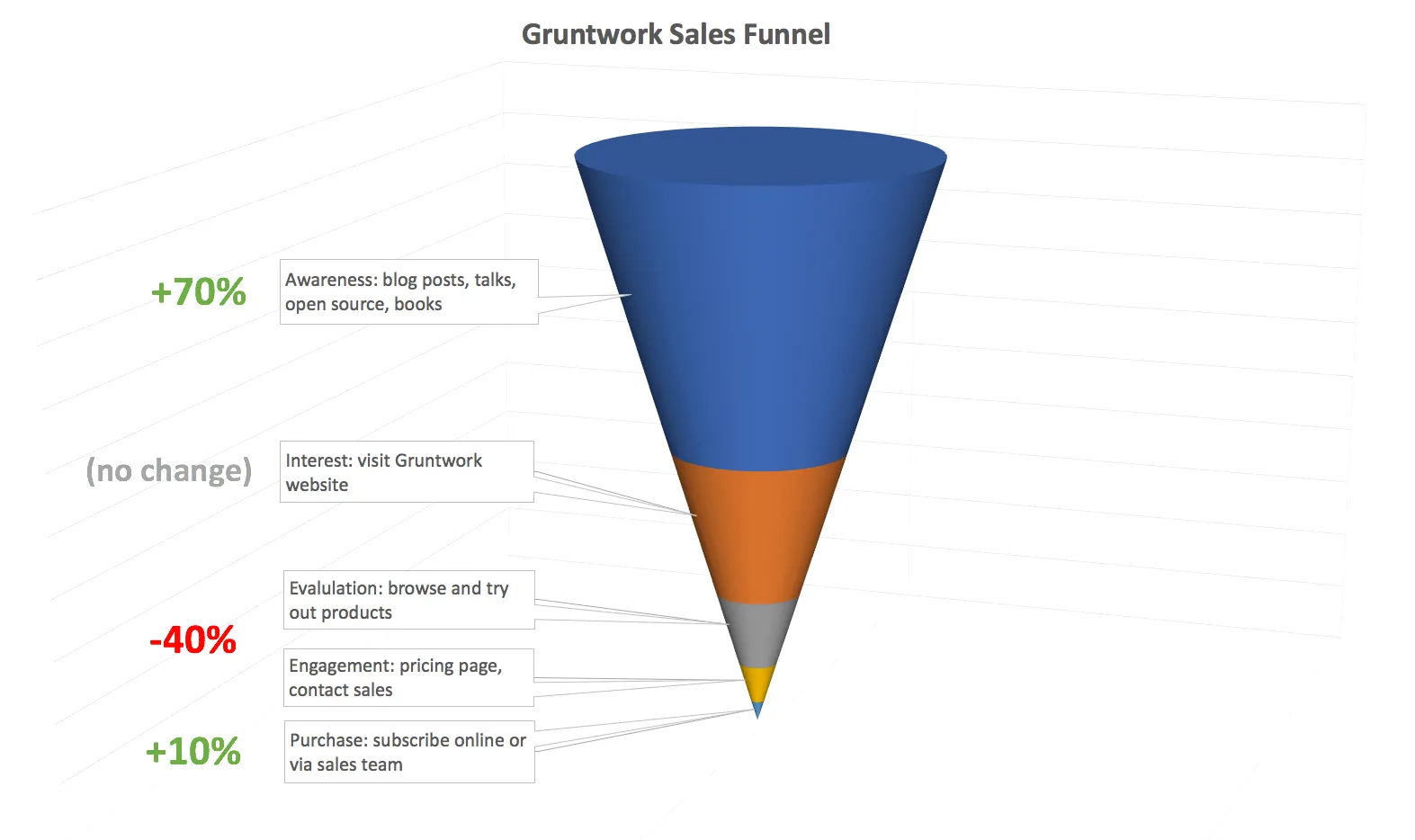
Visits to our content were up 70%; roughly the same percentage of those visitors ended up going to the Gruntwork website; and our sales team was converting about 10% more deals than before. But the step in between, where visitors would evaluate the product and go to the pricing page or contact sales, was down by around 40%! Worse yet, this had been a consistent trend for several months since we launched the redesign, and the only reason we hadn’t noticed was because the overall number of visitors had gone up. Yikes.
The solution
Now that we knew what was going on, it was time to fix the problem. We came up with a new design which replaced the confusing “Get Started” CTAs:

With clearer and more explicit “Buy Now” and “Contact Sales” CTAs:

If we had just blindly launched this change, it would have been hard to tell if it had the impact we wanted. Even if our website conversion metrics changed after launching this new design, we wouldn’t know if the change was due to the new design, or something else (e.g., other product launches, new blog posts, a change in search ranking, etc). To be able to separate causation from correlation, we needed to do a scientific experiment—or, if you prefer the marketing terminology for it, an A/B test.
We used Optimizely to show the new design to a
randomly selected 50% of our website visitors and the old design to the other 50% of visitors, and
we tracked our conversion metrics across each of these groups. The results were fairly clear. For
example, here is how the old design (original_nav) compares to the new design
(beta_nav) in terms of getting users to contact sales:
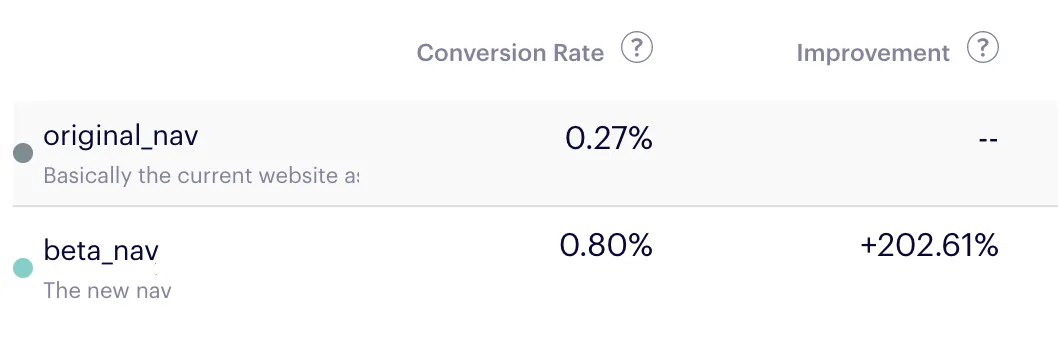
The new design increased the conversion rate dramatically in almost every metric we measured in the A/B test, including roughly tripling the number of visitors who contacted sales (+202.61%, as shown in the image above)! It also got far more users to browse the rest of the website and actually learn about and evaluate the product before going to the pricing / checkout page. The result, as I can see now with all the metrics for the year in front of me, was that we more than doubled conversions on our website with that simple design tweak.
Lessons learned
While this story had a happy ending, it exposed a dark reality: we had been flying blind. Our website conversions had dropped by ~40% and we didn’t even notice! Here’s what we’ve learned as a result of this experience:
- Proactively track leading indicators: Although we had done a good job of tracking metrics like revenue and number of customers signed, these were all lagging indicators that only showed us the results of work in the past; what we were missing was regularly looking at leading indictors, such as website visitors and conversion rate, which could give us an early warning about possible future results. We’re now setting up a dashboard in Klipfolio that has all of our Key Performance Indicators (KPIs), both leading and lagging, and will be reviewing these numbers every month.
- Test your products using SCIENCE: The reason conversions had dropped by ~40% was due to a redesign we had launched several months before. The problem is not that we got something wrong in the design—mistakes are inevitable and happen all the time—but that we didn’t know that we had gotten it wrong. Therefore, we will try to avoid launching any more major changes “blindly.” Instead, we’ll use science, in the form of A/B testing, to measure the impact of each new launch. Note: Optimizely turned out to be too expensive for a small company like Gruntwork, so for future experiments, we will most likely use Google Optimize.
Listen to the team
The reason we noticed that sales were down was because one member of our team had a hunch. As it turns out, she happened to be the newest and most junior member of the team, but something about the numbers looked odd, and she decided to speak up. And fortunately, the rest of us decided to listen. In fact, this entire year was a lesson in how to listen to the team.
“Listen to the team” may sound like an obvious piece of advice, but for a 100% distributed company like Gruntwork, with employees all over the US, Canada, the UK, Ireland, Germany, Finland, and Nigeria, the thousands of miles and multiple time zones separating team members makes communication harder than you might expect. While there are many advantages to distributed companies, there are some things you get “for free” when everyone works in the same office—things you probably take completely for granted—that become much trickier:
- Serendipitous discussions are more rare. You don’t get to chat with your colleagues when you pass them in the hallway or at their desk, or go to lunch with your team, or go on walks with them, or play sports together, or do volunteer activities together, or almost anything else outside of scheduled calls.
- Celebrating wins is harder. Giving someone a high-five over a video call just isn’t the same as doing it in person. Sending a “good job team” with a thumbs-up emoji on Slack is not the same as taking the team out for celebratory lunch.
- Staying motivated is harder. When you walk into an office, and see your whole team excited and working hard on something, it’s infectious, and you can’t help but join in. When you’re at a distributed company, it’s just you, at home, all alone, day after day.
- Knowing what’s going on is harder. In an office, merely as the result of everyone being in the same physical space, where it’s easy to see and chat with everyone, you typically have a good idea of the status of the team: what everyone is up to, how a project is moving along, if someone hit a roadblock, what mood people are in, and so on. In a distributed company, by default, you have no idea what’s happening with anyone else: you can’t see them, hear them, know if they are happy, frustrated, or even if they are working at all. It’s amazing how much value there is in a simple “good morning” when you come into the office and “good night” when you leave—what’s the equivalent for remote work?
- Making decisions is harder. In an office, most decisions are done live, in minutes or hours: you gather everyone in a room, or just chat at someone’s desk or in the hallway, talk through the various arguments, and make a decision. In a distributed company, where everyone is in different locations and time zones, this same decision process is harder, and it can take days or weeks to go through the much slower back-and-forth cycle of gathering all the information and arguments asynchronously (e.g., in Slack or Google Docs), making a decision, communicating the decision to others, etc.
- Even something as simple as asking a question is harder. In an office, you just lean over and tap someone on the shoulder. In a distributed company, you have to (a) think about who to ask, (b) wonder what time it is in their time zone, (c) write everything up in a series of Slack messages, (d) wait for a response, (e) get pulled away to work on something else, (f) eventually come back to find a dozen messages asking for more info, (g) try to fill in all the missing context with another barrage of messages, (h) and so on.
To overcome these challenges, we’ve had to put in extra processes and techniques to help us hear what the team is saying, even across thousands of miles, including:
- Regular status updates
- Regular 1:1s
- Written & transparent communication by default
- Clear, explicit decision making
- Regular in-person meetings
Regular status updates
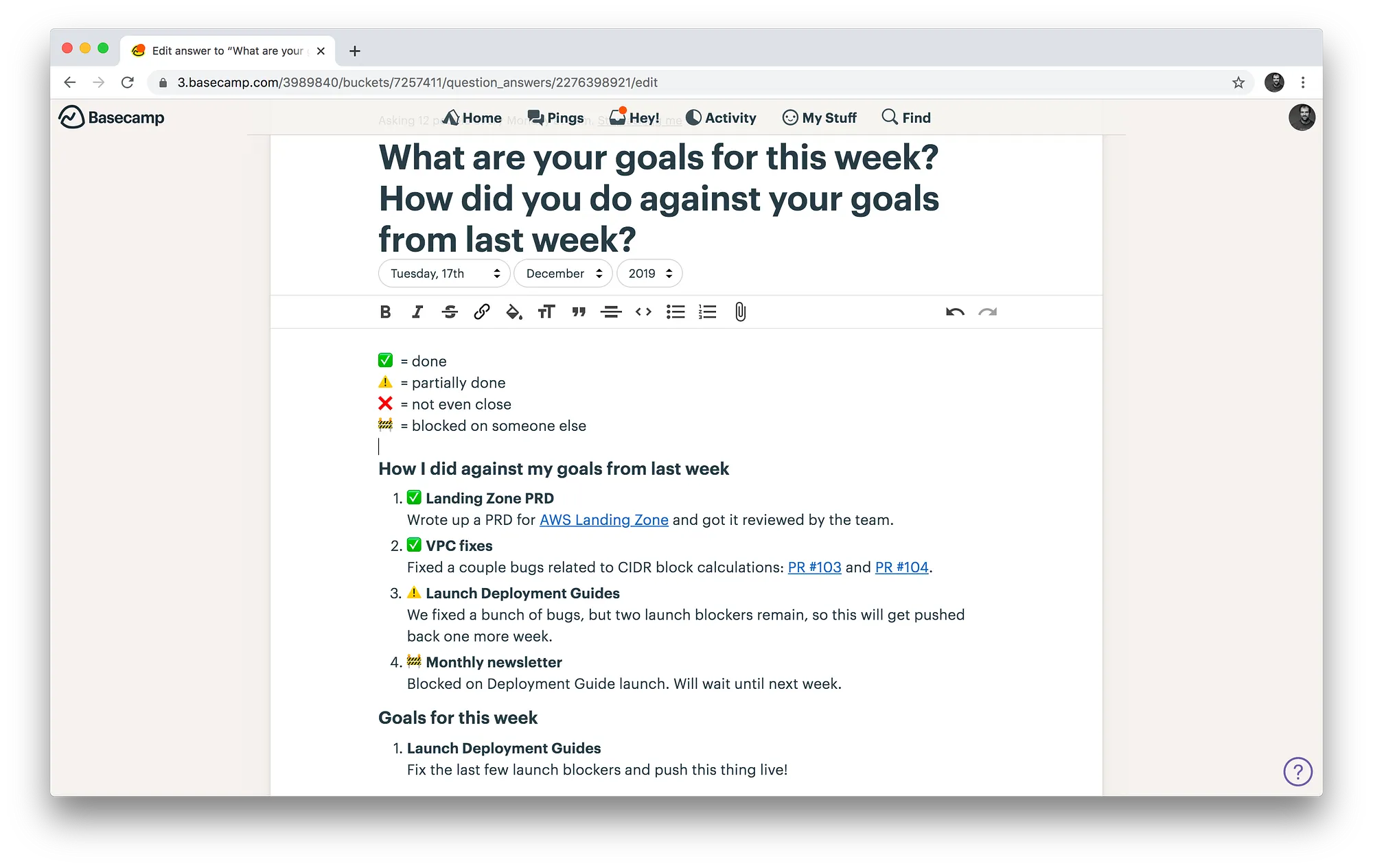
Since you can’t see or hear each other in a distributed company, you have to go out of your way to regularly let everyone know what you’re up to. We use a number of tools and techniques for this. For example, we’ve configured Basecamp check-ins to prompt each person once a week to ask (a) what you accomplished last week and (b) what you’ve got planned for this week. Your response is stored on Basecamp and shared with the entire team:
We also use Basecamp check-ins for daily status updates (“What did you do yesterday and what do you have planned for today?”) and monthly check-ins (e.g., “What interesting books did you read last month?”). Other tools we’ve found helpful for keeping the team up-to-date include GitHub pull requests (submitting small, frequent pull requests not only helps update the team as to what you’re working on, but these smaller changes are also easier to review), Jira (breaking work down into small tasks that you update regularly helps the team better understand what’s happening with a project), and Slack (it can be helpful to post occasional status updates in the Slack channels for the relevant project/team).
Regular 1:1 meetings
Each employee chats with their manager on a regular basis. Each 1:1 is about an hour long, and the focus is explicitly on the items that don’t make it into status updates. That is, instead of talking about what you did (which we should already know, as per the previous section), you talk about how you did it, what worked well, what could’ve been done better, what concerns you have, how you’re getting along with the team, what the company could do differently, what your manager could do differently, and so on.
We take notes during the 1:1 in a shared Google Doc:
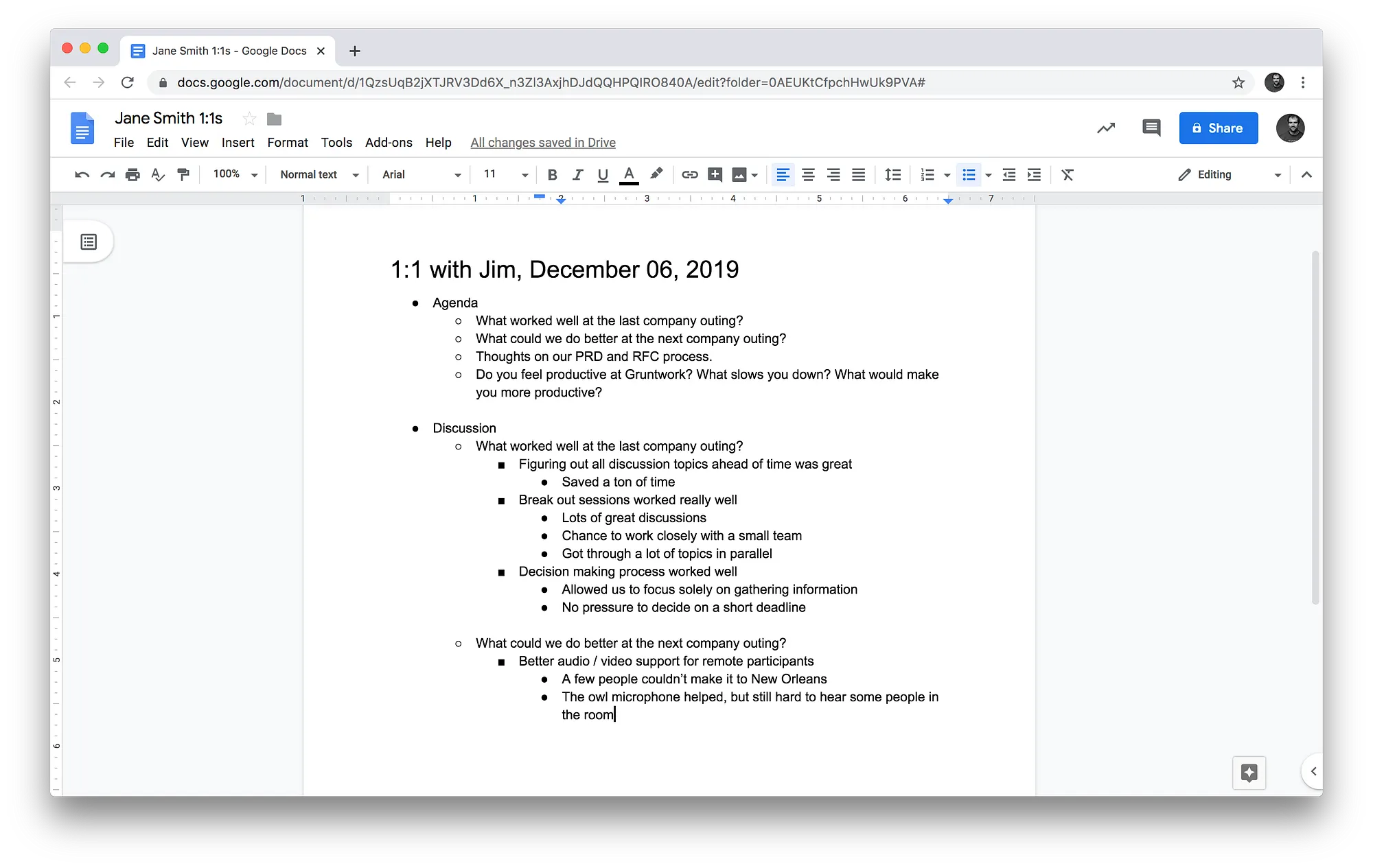
In between 1:1s, both the employee and the manager can add items to discuss to this Google Doc. That way, you have an agenda ready to go for the next time you meet.
Written and transparent communication by default
Inspired by blog posts from Stripe and GitHub, we do the following:
- Written by default: By default, every discussion should be done in a written format (e.g., Slack, email, Google Docs, GitHub pull requests, and wiki pages). And if a discussion does happen live (e.g., sometimes, it’s easier to talk things out rather than write them), you should take notes (e.g., in Google Docs), and share a summary afterwords. This allows everyone to see what was discussed, even if they weren’t part of the original discussion (e.g., due to time zone differences), and helps us remember and revisit discussions months and years later, long after they have faded from human memory.
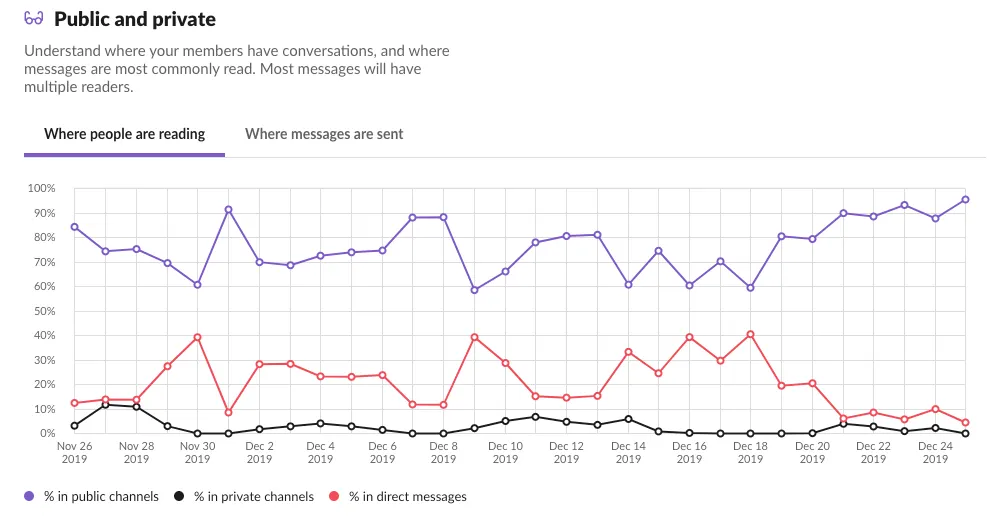
- Transparent by default: By default, all conversations happen out in the open. This way, everyone can better understand what’s happening with the company, what decisions we’ve made, and why we made those decisions. Hopefully, it also reduces bias, discrimination, and any temptation to do anything evil or questionable (“sunlight is said to be the best of disinfectants”). The only discussions that should happen privately are those that are sensitive in nature: e.g., private family matters, or negative feedback (“praise publicly, criticize privately”). Other than that, almost all emails should BCC a company mailing list (e.g., sales discussions CC our sales email group) and almost all Slack conversations should happen in public channels rather than private channels or direct messages. In fact, according to Slack Analytics, roughly 80% of our conversations happen in public channels, which I suspect is an unusual ratio for a typical company:
Clear, explicit decision making
To improve our ability to make decisions as a distributed company, while still defaulting to written and transparent communication, we use a Slack app called Conclude that allows us to systematically raise and conclude discussions. To raise a new discussion, you run the following command:
/c basicThis pops up a form to fill out (this uses a Slack Blueprint under the hood):
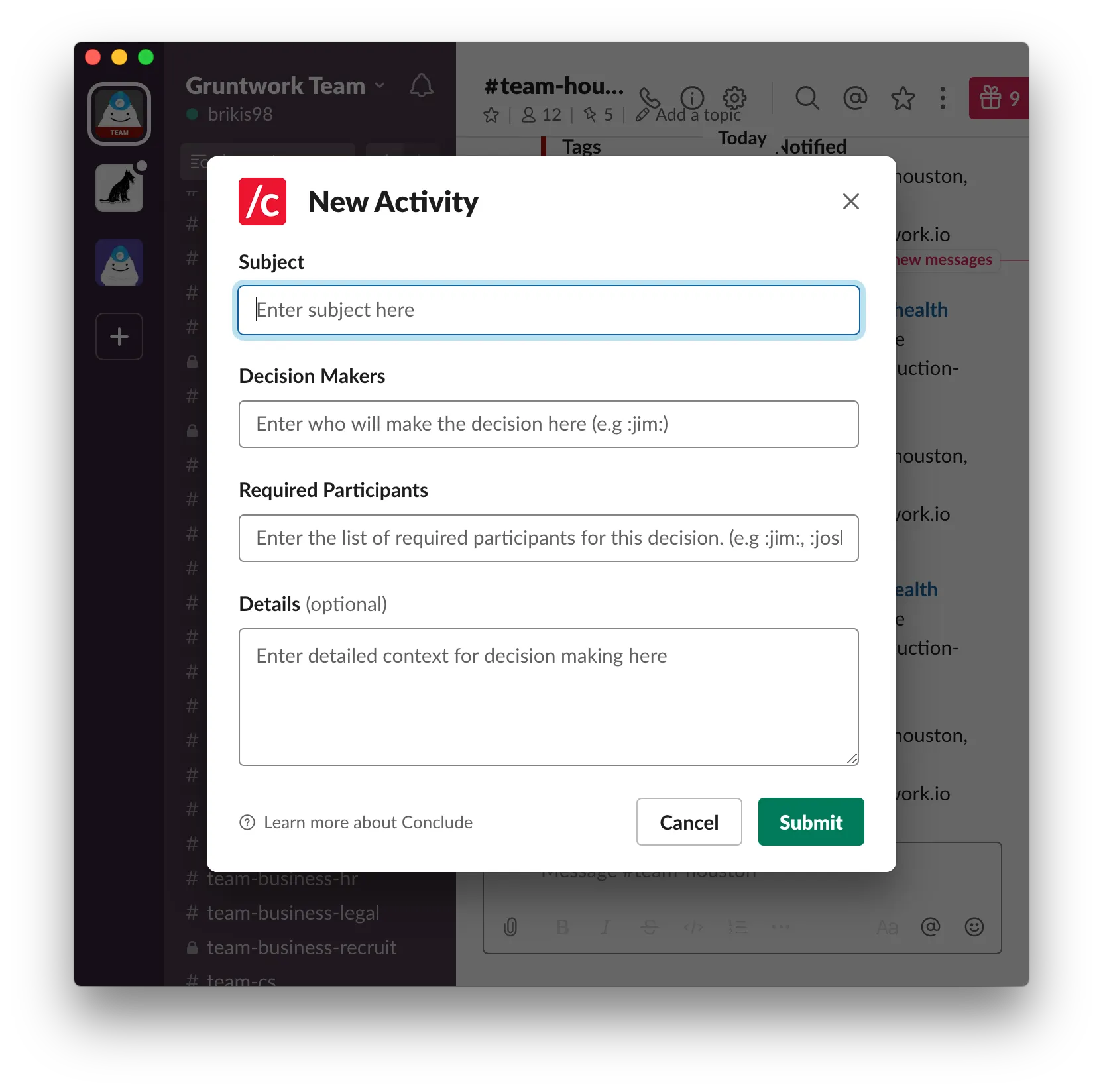
Here’s the information you need to fill out in the form:
- Subject: A brief sentence explaining what the discussion is about.
- Decision makers: Who is going to make the decision? Will it be you? The lead of some team? Will we all vote on it? This must be defined up-front.
- Required participants: While most discussions happen publicly, and everyone can see them, not everyone is required to participate. Identify up front who is required to participate in a discussion: e.g., the subject matter expert for some topic we’re discussing or a key decision maker. Everyone else can then choose to follow along or skip the discussion.
- Details: More details on what we’ll be discussing.
- Deadline: This is actually something you fill in after submitting the form. Every decision should have a deadline. Set this up front so everyone knows how much time they have to get their input in.
Once you hit “Submit,” this creates a new Slack channel for the discussion. Once everyone has had a chance to have their say, the decision makers will make a decision, and announce it to the team and capture it for the future by running the following command in that Slack channel:
/conclude We decided to ...Regular in-person meetings
Roughly three times per year, we fly everyone in the company out to an interesting location for a week, and spend 3–4 days doing work and 1–2 days having fun together. The company outings for 2019 have included Arizona:

Portugal:

And New Orleans:

Each of these outings has proven to to be hugely productive (and fun!). They have given us a chance to make up for some of the things you lose as a distributed company: we get to have more serendipitous discussions; we get to celebrate wins in person; we get to have everyone working in the same room, getting motivated and excited for the future; and, everyone gets to ask important questions and be heard.
Lessons learned
- Design your distributed company to make communication easier. If you’re building a distributed company, you need to be aware that communication doesn’t “just happen.” You have to deliberately design the company to make it work: status updates, 1:1s, written communication, decision making process, etc.
- Expect to over-communicate. If you work at a distributed company, you should expect to have to make a deliberate, extra effort to communicate with others. In fact, it’ll often feel like over-communicating or over-sharing. But don’t worry about it: just when you start to get sick of repeating the same message over and over is when others will hear it for the first time.
- Nothing beats working in-person. Distributed companies have many advantages, but nothing replaces in-person work, at least a few times per year. It was at our company outings where we realized that the hunch our new hire had about sales being down was spot on, as discussed in the previous section. And it was at one of these outings that we figured out that we needed to overhaul our product management process, as I’ll discuss in the next section.
Listen to the customers
One of the topics that always comes up in Gruntwork company outings is, “what should we work on next?” We’re in the DevOps space, where there seems to be an endless list of possibilities. Everything feels broken, underdeveloped, poorly designed, or entirely missing. Should we work on improving our Kubernetes offering? Serverless? CI / CD? Microservices? Service mesh? Edge computing? Distributed tracing? Observability? Big data? Data lakes? Machine learning? IoT? GitOps? ChatOps? DevSecOps? NoOps?
The list is endless, and while having lots of opportunities can be a good thing, it’s also a risk, as more startups die of indigestion than starvation. One of the realizations we had from discussions at our company outings was that we were being pulled in all directions, and taking on too many projects for too few people. Our roadmap was not well defined, the individual projects were not well defined, and the team was spending lots of time on the overhead of jumping from one project to another.
Improving our product management process
We decided to solve this problem by changing our product management process, and rebuilding it around (a) listening to our customers and (b) doing fewer things better. The first step we took was to start gathering all customer feedback and requests in ProductBoard:
We also started to test out a portal where customers could submit and vote on ideas directly:
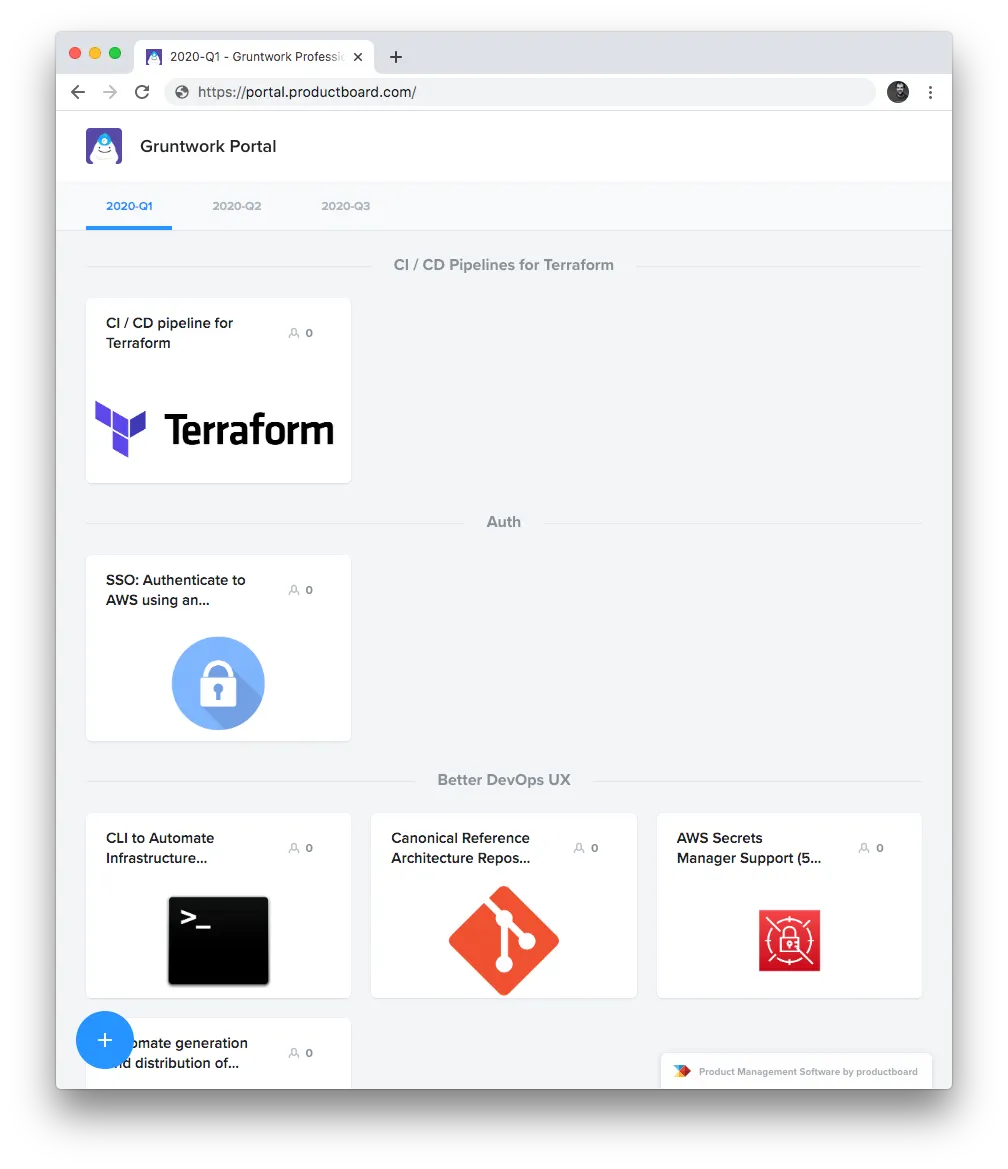
The second step was to take all of this customer data, plus our own ideas, and organize it all into a list of potential top-level product objectives: e.g., streamline our EKS experience, add support for AWS Landing Zone, make it easy to set up SSO on AWS, and so on.
Now that we had our list of objectives, step three was to prioritize them. We used an approach similar to RICE, prioritizing objectives based on their reach (i.e., how many customers would be affected), impact (how much each customer would be affected), confidence (how sure we were the product would have the reach and impact we defined), and effort (how much time it would take to accomplish the objective).
Step four was to go into ProductBoard and enter all the possible features we could work on for any given objective (again, based on customer feedback, plus our own ideas), and to score each feature against that objective:
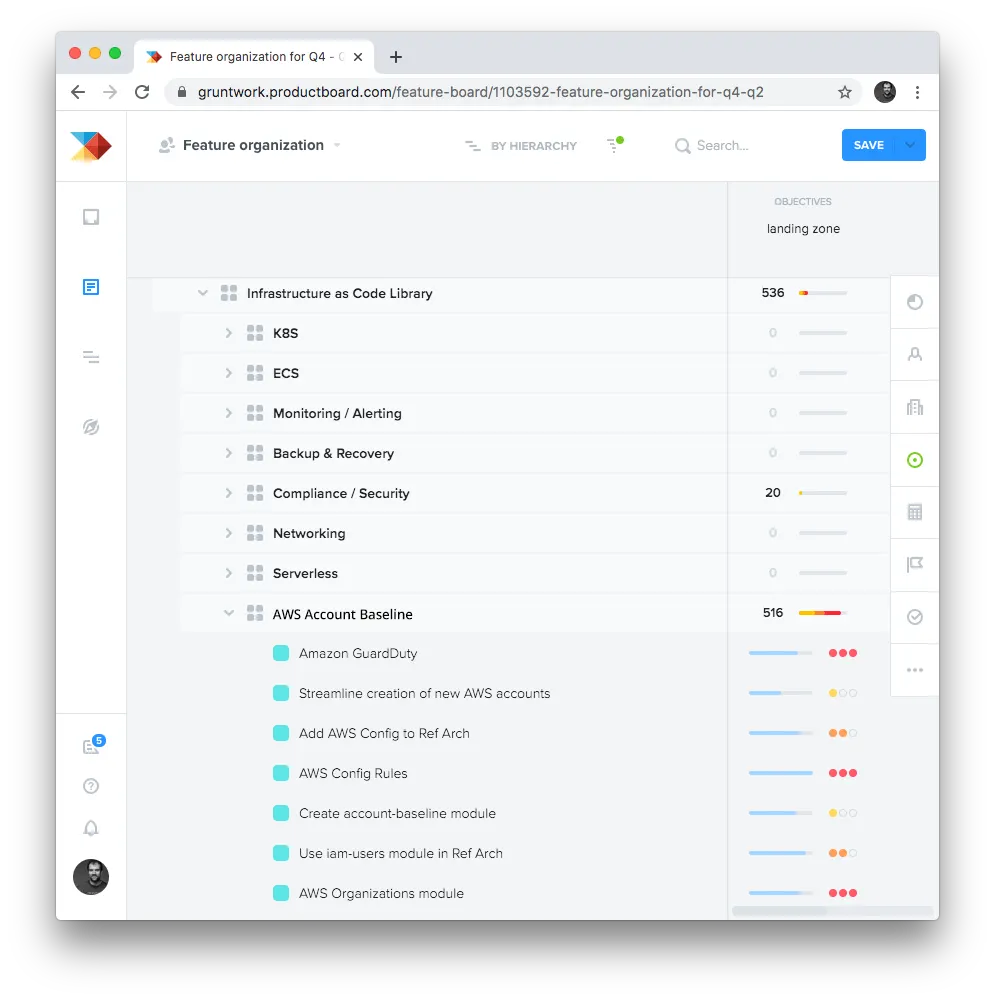
For example, in the image above, you can see on the right side that one of the objectives we were considering was to add first-class support for AWS Landing Zone. On the left side, you can see the list of all possible features we could build, and in particular, how we are scoring the features under “AWS Account Baseline” against the “landing zone” objective. For each feature, we specify its value, whether it’s a nice-to-have or must-have, and an estimate of how much that feature costs: e.g., Amazon GuardDuty is a high-value, low-cost must-have feature for landing zone, whereas “streamline creation of new AWS accounts” is a lower-value, high-cost, nice-to-have feature.
With all objectives prioritized, and all features scored against objectives, we can finally go to
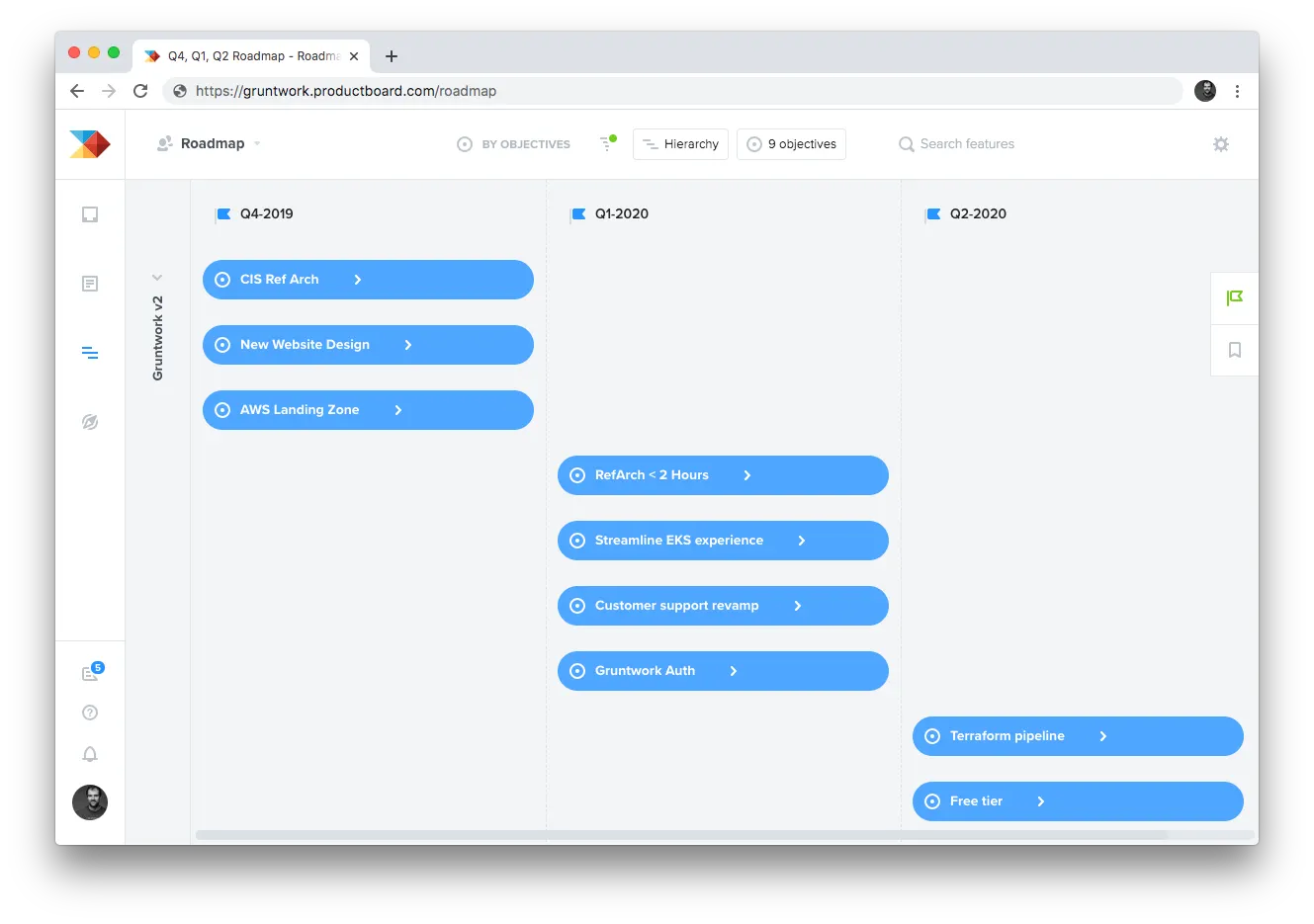
step five, which is to produce a roadmap. Our basic strategy is to swarm on the
highest priority objectives, optimizing for (a) shipping as quickly as possible and (b) team
efficiency. For example, let’s say some objective foo would take the following
amount of time to complete:
- With 1 person working on it: 6 months
- With 2 people working on it: 4 months
- With 3 people working on it: 3 months
- With 4 people working on it: 2.8 months
- With 5 people working on it: 2.6 months
- With 6 people working on it: 2.5 months
- Etc
It looks like the work in foo is parallelizable up to about 3 people, after
which you get diminishing returns. We’d most likely assign 3 people to this objective. On the
other hand, consider objective bar:
- With 1 person working on it: 6 months
- With 2 people working on it: 3 months
- With 3 people working on it: 1.5 months
- With 4 people working on it: 3 weeks
- With 5 people working on it: 1.5 weeks
- With 6 people working on it: 6 days
- Etc
For project bar, it would make sense to assign as many people as we had
available to it, as that would mean we could ship it in a matter of days, rather than months, and
start gathering all the value from it right away, while we moved on to other work. Of course, in
the real world, few projects are that parallelizable, and you also typically need to take into
account other overheads, such as the time it would take for someone to ramp up on a totally new
project.
Putting this all together, to create our roadmap, we start with the current quarter, add the highest priority objective, assign as many people as is reasonable to ship that objective quickly (swarm), then add the next highest priority objective, have people swarm on that, and repeat the process until there are no people left to assign. We’d then move to the next quarter and repeat the process.
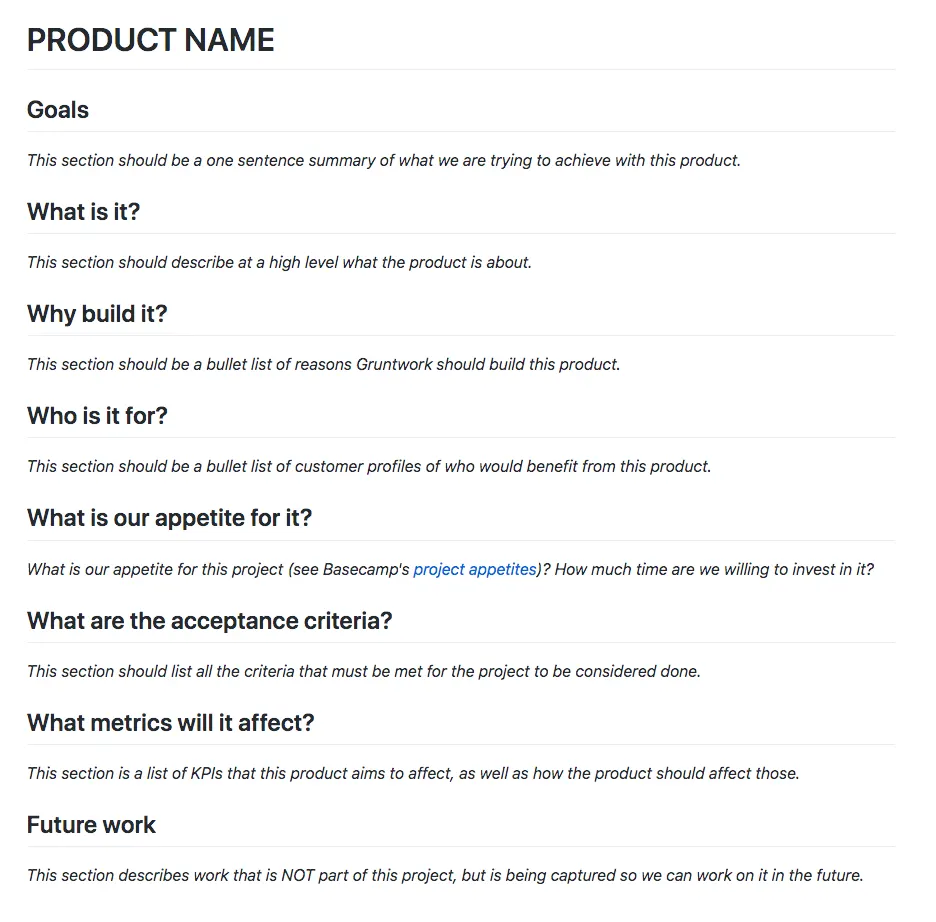
For each item that made it into our roadmap, step six is to put together a Product Requirements Document (PRD) that briefly outlines what we want to do: the problem, why it’s important, who it affects, our appetite for solving it, what metrics we think it’ll move, and the requirements for the solution. Each PRD is written in Markdown, submitted as a pull request in GitHub, and reviewed by the team. Here’s the template we use for it:
The members of the relevant team can then submit a Request for Comments (RFC) that outlines ideas for how to meet the requirements in the PRD. This may include mock-ups and wire frames, technical designs, a description of the user workflow, and so on. Each RFC is written in Markdown, submitted as a pull request, and reviewed by the team. Once merged, the engineering work can begin!
The results
This new process has significantly improved how we communicate product decisions and designs within the company, and, we believe that we’re now doing a much better job of focusing on the most critical features and products for customers. Here’s just a glimpse at some of the items we’ve delivered in 2019:
- Infrastructure as Code Library Improvements
- Google Cloud Support
- CIS Compliance Support
- Production Deployment Guides
- New Blog Posts
- New Videos
- And More
Infrastructure as Code Library Improvements
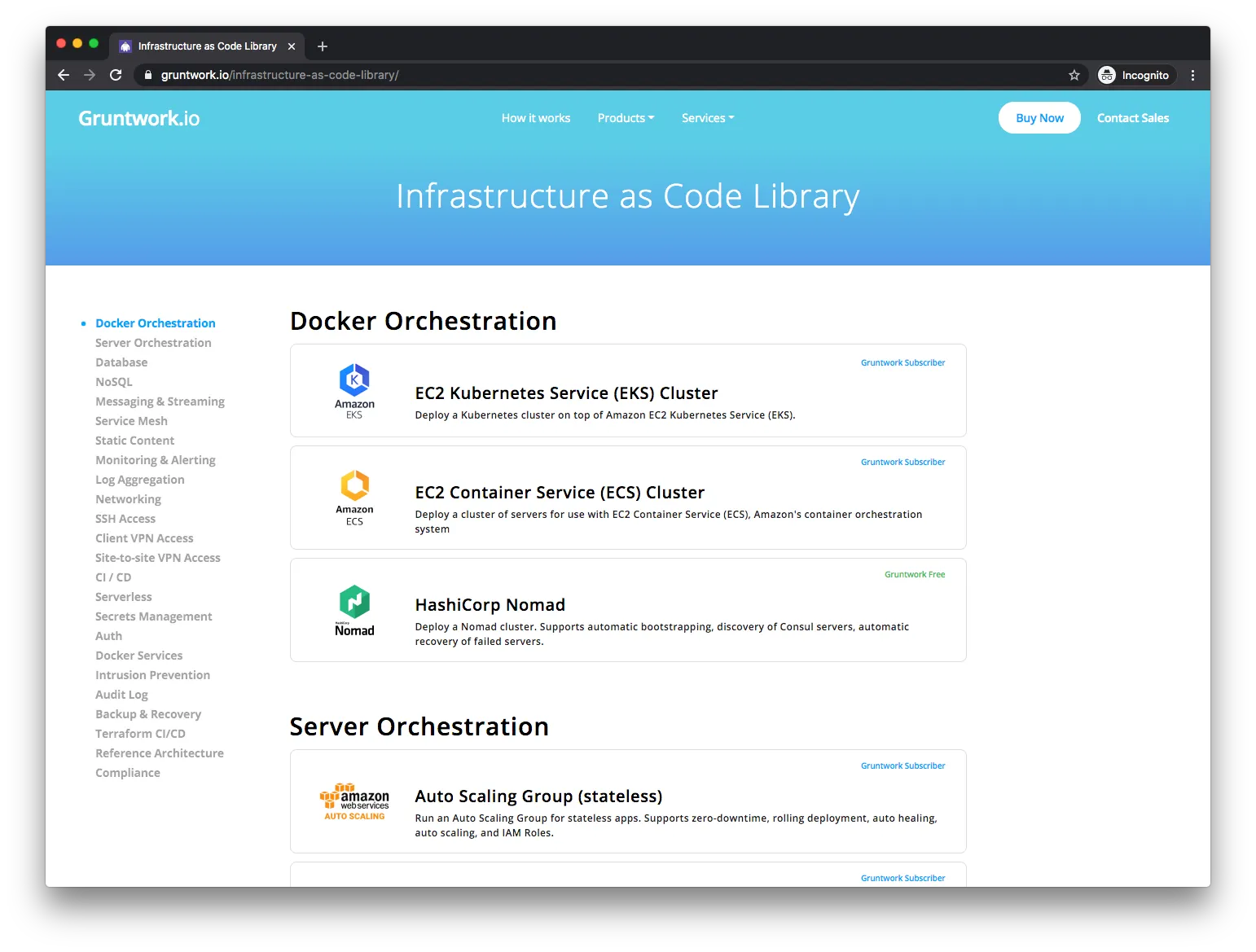
We’ve made major improvements to the Infrastructure as Code (IaC) Library, including:
- Upgraded the entire library (all 300,000+ lines of code) multiple times, including adding support for Terraform 0.12, Ubuntu 18.04, and AWS Provider 2.x.
- Major new features for EKS, including integrating it into the Reference Architecture, and adding support for zero-downtime cluster upgrades, cluster auto-scaling, fine-grained IAM roles, private endpoints, and more.
- Major improvements to our Vault modules, including auto-unsealing, authenticating with instance metadata, and authenticating with IAM users or roles.
-
Lots of new features in our tooling, including Terragrunt (support for
dependencyblocks, support for all Terraform built-in functions, move to HCL2, support for encryption and access logging) and Terratest (switch to Go Modules, support for Helm Chart testing, support for testing Kubernetes). - Updates to many other modules, including more robust zero-downtime deployment for Kafka and ZooKeeper, a new module to create and manage IAM users as code, support for defining CloudWatch Dashboards as code, support for the entire TICK stack on AWS and on GCP, new module for issuing and validating TLS certs, and hundreds of other fixes and improvements.
Google Cloud Support

In partnership with Google, we added first-class support for Google Cloud Platform (GCP), including:
- A set of open source modules for going to prod on GCP, including modules for GKE, VPCs, Cloud SQL, Cloud Load Balancer, and much more.
- A Reference Architecture for GCP that gives you an end-to-end, production-grade tech stack in about 1 day.
CIS Compliance Support

In partnership with the Center for Internet Security, we’ve released:
- A set of reusable CIS modules that are certified to be compliant with the CIS AWS Foundations Benchmark.
- A CIS Reference Architecture that gives you an end-to-end, production-grade tech stack that is certified to be compliant with the CIS AWS Foundations Benchmark, in about 1 day.
- A step by step guide that walks you through How to achieve compliance with the CIS AWS Foundations Benchmark.
Production Deployment Guides
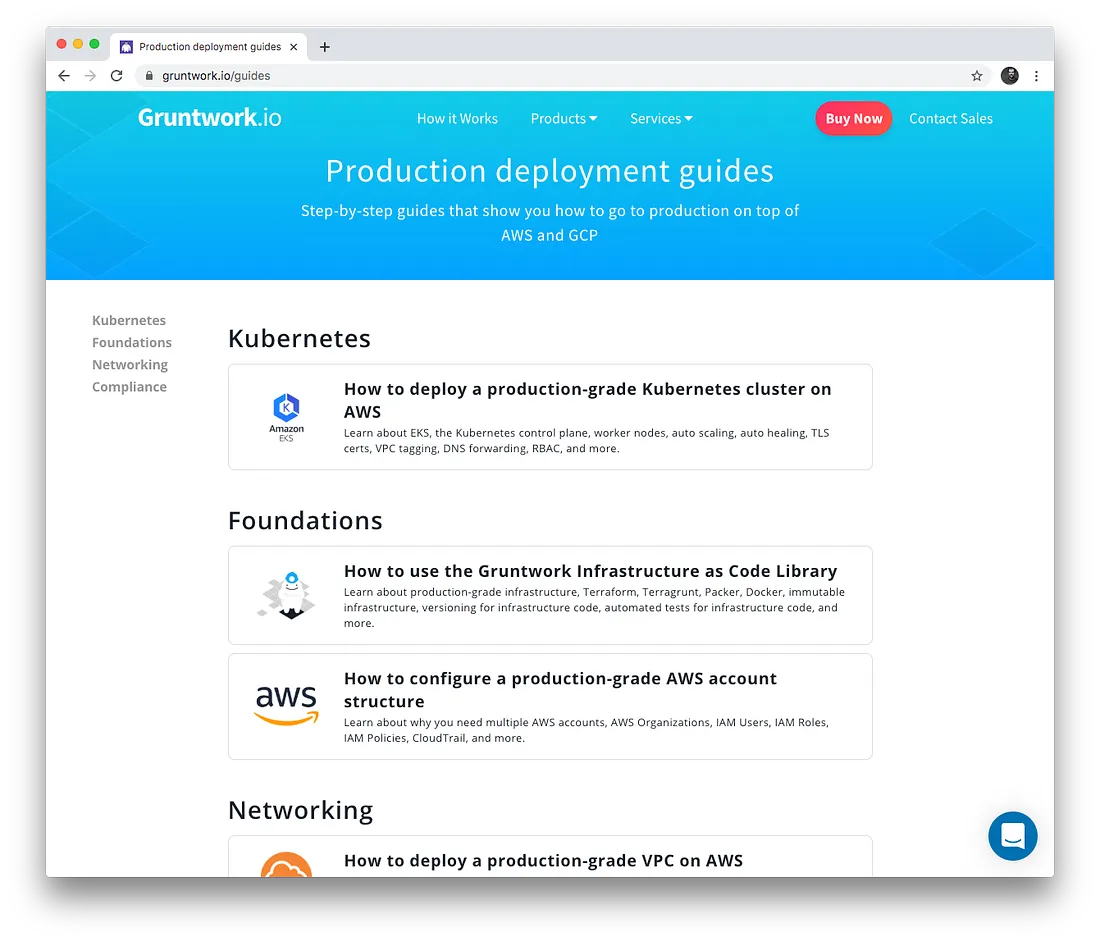
We released a series of Production Deployment Guides, which contain step-by-step instructions for how go to production on top of AWS and GCP, including:
- How to deploy a production-grade Kubernetes cluster on AWS
- How to deploy a production-grade VPC on AWS
- How to configure a production-grade AWS account structure
New blog posts
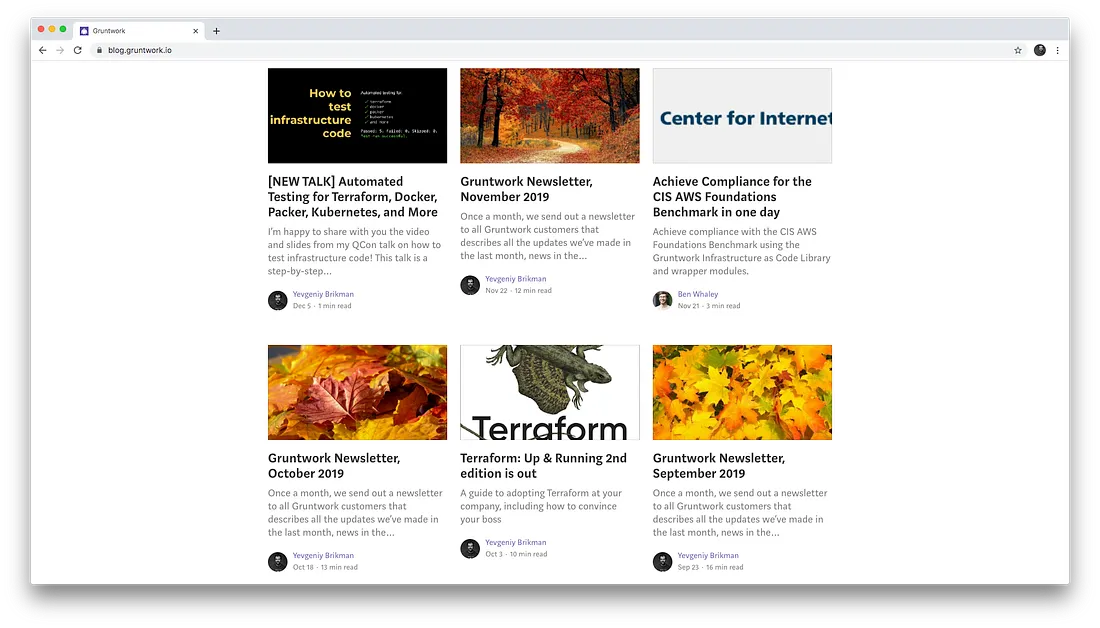
We published blog posts on:
- How to Build an End to End Production-Grade Architecture on AWS
- How to Achieve Zero Downtime Server Updates For A Kubernetes Cluster
- How to Automate HashiCorp Vault
- How to manage multiple versions of Terragrunt and Terraform
- Automated Testing for Kubernetes and Helm Charts
New videos
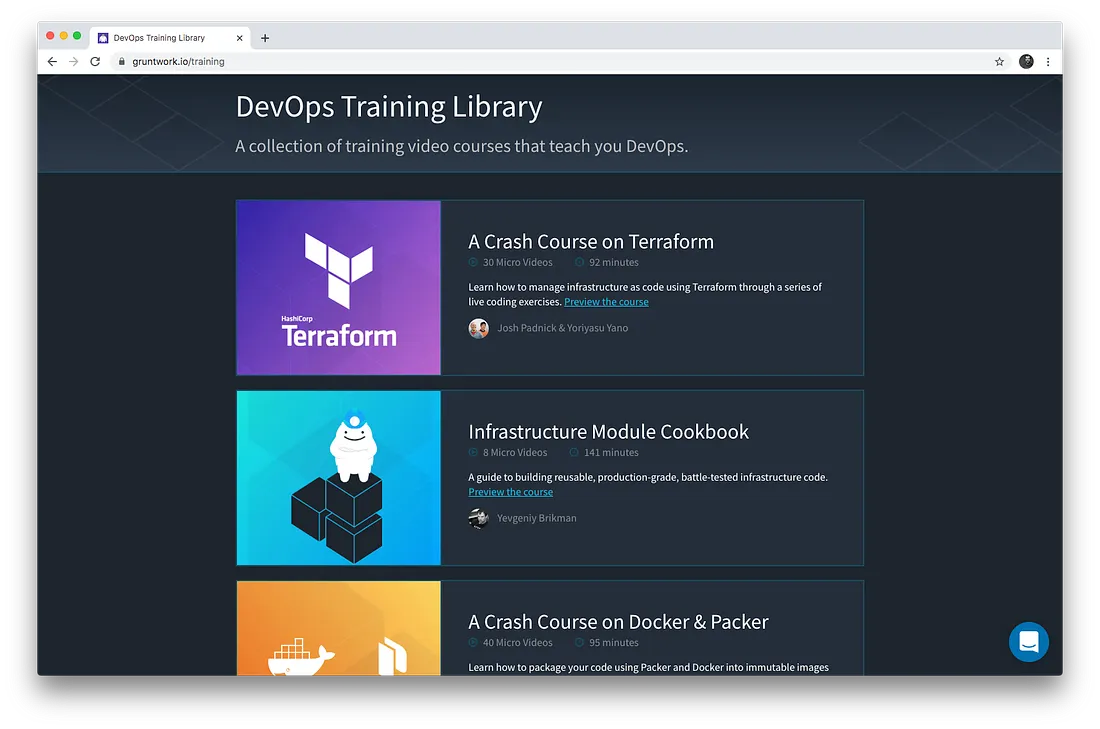
We updated the DevOps Training Library:
- Added a new Infrastructure Module Cookbook Course
- Updated the Terraform Crash Course for Terraform 0.12
- Released Automated Testing for Terraform, Docker, Kubernetes, & more
And much more!

We also:
- Published the second edition of Terraform: Up & Running
- Created a standalone documentation website for Terragrunt
- Made hundreds of other new releases, improvements, and fixes
Lessons learned
- Your product management process must evolve with the company. The product management process we used when Gruntwork had 3 people does not work now that we have 15; the process we used to develop reusable infrastructure modules does not work for developing web UIs. Adapt and evolve your processes regularly.
- Less is more. The more we focused on a small number of high valuable products and features, the more successful we became. The more we listened to customers, the better we could determine which products and features were the most valuable.
Conclusion
We learned a lot in 2019, especially about listening to the data, our team, and our customers. We hope you’ve found some of these lessons valuable too. Happy holidays and see you in 2020!



- No-nonsense DevOps insights
- Expert guidance
- Latest trends on IaC, automation, and DevOps
- Real-world best practices



