
Once a month, we send out a newsletter to all Gruntwork customers that describes all the updates we’ve made in the last month, news in the DevOps industry, and important security updates. Note that many of the links below go to private repos in the Gruntwork Infrastructure as Code Library and Reference Architecture that are only accessible to customers.
Hello Grunts,
We’ve got lots of fun updates for you from the last month! We added a new “Infrastructure Module Cookbook” course to our DevOps Training Library, wrote two new blog post series, one on zero-downtime updates for Kuberentes clusters and one on automating HashiCorp Vault, updated our Kubernetes modules with support for securely configuring Helm/Tiller, refactored our Kubernetes modules, made a number of fixes and improvements to our ZooKeeper and Kafka modules, added out-of-the-box CloudWatch Dashboards to the Gruntwork Reference Architecture, and much more.
As always, if you have any questions or need help, email us at support@gruntwork.io!
Gruntwork Updates

New Training Course: Infrastructure Module Cookbook
Motivation: Many customers were asking us for best practices on how to write reusable, production-grade, battle-tested infrastructure code.
Solution: We’ve added a new course to called The Gruntwork Infrastructure Module Cookbook. It goes over all the lessons we’ve learned from building a library of over 300,000 lines of infrastructure code that’s used in production by hundreds of companies. Topics covered: the tools we use, how to build small, reusable modules, how to keep your infrastructure code DRY, how to write automated tests for infrastructure code, and how to version, release, and deploy infrastructure code.
What to do about it: The new course is available as part of your Gruntwork Subscription! So, if you’re a subscriber, just log into https://training.gruntwork.io/ and you should already have access (if it’s not working for some reason, email us at support@gruntwork.io). If you’re not a subscriber, sign up now, and get access to all of the courses in the DevOps Training Library plus all the battle-tested infrastructure code in the Infrastructure as Code Library.

New Blog Series: A guide to automating HashiCorp Vault
Motivation: Vault is an open source tool created by HashiCorp for securely storing secrets, such as database passwords, API keys, and TLS certs. Authenticating to Vault manually is easy, but many of our customers were struggling with figuring out how to automate Vault—especially automatically unsealing Vault (e.g., after an outage) and automatically authenticating to Vault from another server.
Solution: We’ve updated our Vault code for both AWS and GCP to make automation easier and wrote a 3-part blog post series that shows you how to implement this automation in your own deployments:
What to do about it: Start with the first part of the series, Auto-unsealing, and let us know what you think!
New Blog Series: Zero Downtime Updates for your Kubernetes Cluster
Motivation: Although Kubernetes has built-in support for rolling out updates to the Docker containers you’re running in your cluster, how do you update the cluster itself? Last month, we updated our Kubernetes modules with support for automated rolling deployment for EKS clusters, and we learned that it wasn’t enough to follow best practices in draining the instance workers to achieve a zero downtime rollout. There are many settings and considerations you have to think through on the deployed resources in Kubernetes, such as graceful shutdowns, pod shutdown lifecycle, and PodDisruptionBudgets.
Solution: We decided to share our learning in a 4 part blog post series that covers how to deploy your containers on Kubernetes to achieve zero downtime cluster updates. The 4 parts are:
- Introducing the problem
- Gracefully shutting down pods
- Delaying shutdown to wait for pod deletion propagation
- Avoiding outages with PodDisruptionBudgets
What to do about it: Head on over to part 1 and share your feedback!
Kubernetes Package Repository Split
Motivation: As we started developing the Kubernetes modules, we realized that they were reusable across different Kubernetes clusters and across different clouds (e.g AWS, GCP, Azure). In the old structure, with both the Kubernetes modules and the EKS modules in the same Github repository, the multicloud nature of the Kubernetes modules was not obvious. To make it clearer that the Kubernetes modules worked with other flavors of Kubernetes and not just EKS, we decided to split out the modules into multiple repositories.
Solution: We have split the repo that used to be called package-k8s into the following repositories:
terraform-aws-eks: This repo now holds the modules related to EKS (eks-cluster-control-plane,eks-cluster-workers,eks-k8s-role-mapping,eks-vpc-tags).terraform-kubernetes-helm: This repo now holds the modules related to setting up Helm on a Kubernetes cluster (k8s-namespace,k8s-service-account,k8s-helm-server).helm-k8s-services: This repo will hold all the helm charts that can be used to package your application to be deployed on Kubernetes via Helm (k8s-job,k8s-daemon-set,k8s-service).kubergrunt: This repo now holds thekubergrunttoolbox, which includes support for configuringkubectlto authenticate to an EKS cluster, securely configuring the Helm server (Tiller) and its TLS certificates, and securely configuring Helm clients and their TLS certificates.
What to do about it: If you are part of the Gruntwork Kubernetes beta, take a look at the migration notes in package-k8s. If you’re a Gruntwork Subscriber and would like to join the Kubernetes beta, email us at support@gruntwork.io and we’ll grant you access (and if you’re not a subscriber, sign up now)!
Tiller (Helm Server) Deployments Now Use Security Best Practices
Motivation: We found that deploying Tiller (the server component of Helm) while following all the security best practices can be challenging. By default, Tiller does not apply any security configurations, requiring you to navigate RBAC authorization, TLS, and overriding configs to make use of Secrets in order to follow the best practices for deploying Tiller.
Solution: We implemented a deployment tool in kubergrunt that will enforce the recommended security best practices when deploying Tiller. This entails:
- Using RBAC authorizations to lock down what Tiller can do.
- Deploying Tiller into its own namespace.
- Using TLS authentication for clients.
- Using TLS verification of servers.
We also wrote a guide to Helm, describing its security model and how kubergrunt helps with following the best practices.
Finally, we implemented a full terraform example in terraform-kubernetes-helm that wraps kubergrunt in terraform to deploy Tiller on your Kubernetes cluster. This includes an example of how to create a Namespace and ServiceAccount with the minimal set of permissions for Tiller to operate.
What to do about it: If you are a beta participant, check out v0.3.0 of kubergrunt and v0.2.1 of terraform-kubernetes-helm. Be sure to read the background guide on Helm, the command README for information on all the features of managing Tiller in kubergrunt, and our quickstart guide on deploying to minikube. The repos are currently in private beta, which is open to any Gruntwork subscriber. If you are interested in participating, email us at support@gruntwork.io and we’ll grant you access (and if you’re not a subscriber, sign up now)!
Improvements in ZooKeeper and Kafka Packages
Motivation: In our Kafka and ZooKeeper packages, we use the server-group module’s support for zero-downtime rolling deployment and an Elastic Load Balancer (ELB) for health checks. In the previous versions, the ZooKeeper health check was done by attempting to establish a TCP connection to the ZooKeeper client port. During cluster launch and rolling deployment, even when the TCP connection was successful, one of the ZooKeeper nodes sometimes failed to re-join the cluster, leaving the cluster in an unstable state.
Solution: We introduced an improved way to perform health checks on the ZooKeeper nodes. By using our simple, open source health-checker library with a custom health check script target, we’re now able to monitor the ZooKeeper cluster status much more precisely — especially during cluster launch and rolling upgrades.
We also rewrote big parts of the test suites for both packages, greatly increasing test coverage and reliability. Both suites now run the module and cluster tests using multiple Linux distributions — Amazon Linux, Ubuntu, and CentOS.
Additionally, we fixed a number of smaller issues, including adding num_* variables for security-group rules to avoid terraform issues with count.
What to do about it: We recommend updating to package-zookeeper, v0.5.0 (update: see v0.5.0 for the upgrade instructions, but use v0.5.2 to pick up a couple important bug fixes) and package-kafka, v0.5.0. Also, check out the examples to see how you can make use of the improved health checking for ZooKeeper.
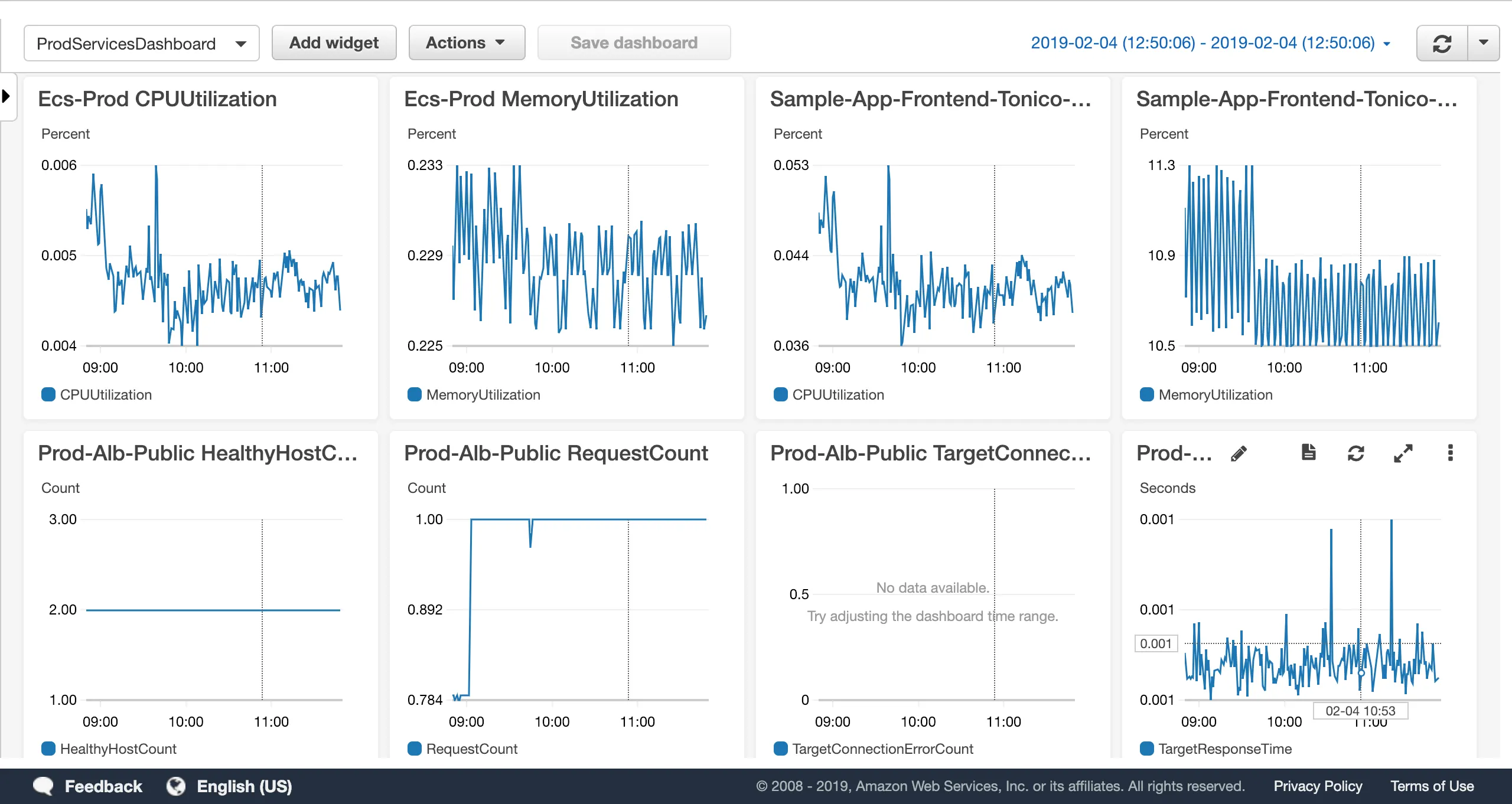
CloudWatch Dashboard now part of the Reference Architecture
Motivation: We’ve always thought that it’ll be great to have an easy way to get out-of-the-box dashboards for the CloudWatch metrics that are published as part of the standard Reference Architecture deployment.
Solution: We now automatically create a CloudWatch Dashboard in each environment (i.e. dev, stage, prod). A dashboard contains a basic set of graphs that allow you to monitor, in real-time, some of the key metrics for services in the Reference Architecture, including ECS Clusters, ECS Services, Application Load Balancers, and RDS databases. We will add support for more resources in the future.
What to do about it: All future deployments of the Reference Architecture will have this feature automatically included. However, if you’d like to add this to your existing deployment, here is a pull request that adds metric widgets and a dashboard module to the Acme Reference Architecture that you can use as a guide: https://github.com/gruntwork-io/infrastructure-modules-multi-account-acme/pull/11.
Open source updates
- terraform-aws-couchbase, v0.1.3: Fixed typo in the
swappinesssetting where we were missing a “p” and therefore weren’t setting the value correctly. Fix alibtinfosymlink issue that prevented Couchbase from starting on Amazon Linux 2. - terraform-aws-consul, v0.4.5:
consul-clusternow allows you to make the iam setup optional and receive a role created externally.run-consulnow configuresautorestartwithunexpectedso attempts to shutdown gracefully won't automatically reboot Consul. - terraform-aws-consul, v0.5.0: Work around for a Terraform limitation that would cause errors if the
allowed_ssh_security_group_countparameter referenced any resources, as theconsul-clustermodule was using that variable in acountparameter. The only available option is that you now MUST pass in a redundant variable calledallowed_ssh_security_group_countthat specifies the number of security group IDs inallowed_ssh_security_group_count. - health-checker, v0.0.3: Added support for running health checks via script execution using a
--scriptargument. - terratest, v0.13.21: Added new functions for retrieving pods from the Kubernetes cluster (
GetPodandGetPodE) as well as waiting for pods to become available (WaitUntilPodAvailableandWaitUntilPodAvailableE). - terratest, v0.13.22:
test_structure.CopyTerraformFolderToTempwill now log the new temporary directory, so you can see which directory it used for the test. Also added new functions for retrieving Kubernetes Secrets (GetSecret,GetSecretE), ServiceAccounts (GetServiceAccount,GetServiceAccountE), and creating ServiceAccounts (CreateServiceAccount,CreateServiceAccountE). - terratest, v0.13.23: Added support to the
k8smodule for authenticating against GKE clusters. - terratest, v0.13.24: Added support for testing RBAC roles in Kubernetes. Checkout our new top level example highlighting all the new functionality to see how to use the new functions.
Other updates
- module-ecs, v0.11.0: The
ecs-service-with-discoverymodule now sets the default family name for the ECS Task Definition to${var.service_name}rather than"${var.service_name}-task-definition"to be consistent with the other ECS modules. - module-ecs, v0.11.1: The
ecs-service-with-discoverymodule now includes a newdomain_nameoutput variable that will be set to the fully-qualified domain name configured for the module (if any). - module-ecs, v0.11.2: The
ecs-daemon-servicemodule now exposes adeployment_minimum_healthy_percentparameter you can use to set the lower limit (as a percentage of the service'sdesiredCount) of the number of running tasks that must remain running and healthy in a service during a deployment. - module-ecs, v0.11.3: The
ecs-daemon-servicemodule now exposes settingpid_modevia a new variable:ecs_task_definition_pid_mode. This allow setting the process namespace to use for the containers in the task. The valid values arehostandtask. - module-security, v0.15.7: Add
DEBIAN_FRONTEND=noninteractiveto calls toapt-getin thefail2banmodule so that the install doesn't hang during automated builds. Usesystemctlinstead ofupdate-rc.dto bootfail2banon Ubuntu. - module-ci, v0.13.8: You can now use the
--java-argsflag with theinstall-jenkinsmodule to configure additional JVM args for Jenkins. - module-vpc, v0.5.4: The Network ACLs in the
vpc-app-network-aclsmodule now all outbound DNS (UDP, port 53) traffic, by default. Most services need DNS, so it seems like a bug to not have exposed this properly before. Note that internal AWS DNS seems to work without this, but for other DNS systems, such as the one used by Kubernetes, this is an important fix. - module-vpc, v0.5.5: Increased the
timeoutsoncreateon theaws_routeresources to 5 minutes to work around a Terraform bug. - module-asg, v0.6.23: The
server-groupmodule now allows you to configure IOPS for your EBS volumes by specifying theiopsattribute for each EBS volume you configure via theebs_volumesparameter. - module-asg, v0.6.24: The
asg-rolling-deploymodule now allows you to configure enhanced monitoring on the instances by specifying theenabled_metricsparameter. - module-aws-monitoring, v0.11.1: The alarms in
alb-alarms,alb-target-group-alarms, andrds-alarmsnow support directly setting thedatapoints_to_alarmsetting. You can read more aboutdatapoints_to_alarmin the official AWS documentation. - module-aws-monitoring, v0.10.3: Fixes a bug in
alarms/alb-target-group-alarmswhere the wrong variable was used for treating missing data on the high request count alarm. - module-server, v0.6.0:
mount-ebs-volumenow uses the UUID instead of the device name to mount volumes. With some OS and volume configurations, the device name can change after a reboot, so using the UUID ensures that the volume is always identified the same way. - module-data-storage, v0.8.6: The
auroramodule now exposes theskip_final_snapshotparameter to allow you to skip a final snapshot when deleting a database. - module-data-storage, v0.8.7: The RDS module now lets you set the option group name and monitoring IAM Role path with two new optional variables,
option_group_nameandmonitoring_role_arn_path, respectively. - package-sam, v0.1.8:
gruntsamnow supports passing through timeout configurations. - package-sam, v0.1.9: Fix bug where the generated terraform code from
gruntsamfrequently fails withConflictException. - module-load-balancer, v0.13.0: The ALB requires all listeners to have a “default action” that defines what to do for a request that doesn’t match any listener rule. In the past, the only supported action was to forward requests to a target group, so we used to forward to an empty “black hole” target group, resulting in a 503. The ALB now supports fixed responses, so we’ve updated the default action of the
albmodule to return a blank 404 page, which is a more appropriate status code.
DevOps News
Amazon launches AWS Backup
What happened: Amazon has launched a new service called AWS Backup that allows you to centrally configure backup policies for EBS volumes, RDS databases, DynamoDB tables, EFS file systems, and so on.
Why it matters: Before, you had to create separate, custom solutions to backup your data for each AWS service (e.g., through cron jobs). Moreover, you had to build your own solutions for monitoring these backups and make sure they never failed. Now, you have a single, centralized service where you can configure all your backup policies that will take care of doing the backups on a schedule and alerting you if anything goes wrong.
What to do about it: Check out the AWS Backup product page for more info. Note that Terraform support for configuring AWS Backup is not yet available. Monitor this issue for progress.
The NLB now supports TLS Termination
What happened: Amazon’s Network Load Balancer (NLB) now supports TLS Termination.
Why it matters: Before, if you were using the NLB, the services you had behind the NLB had to manage their own TLS certificates. Now, you can let the NLB handle it for you, including the built-in integration with the AWS Certificate Manager, which can provision free, auto-renewing TLS certs instantly.
What to do about it: Check out the announcement blog post for details. Note that Terraform does not yet support specifying TLS certs for the NLB. Watch this issue for progress.
Amazon EKS Achieves ISO and PCI Compliance
What happened: Amazon has announced that it’s managed Kubernetes service, EKS, now meets the criteria for ISO and PCI DSS Level 1 compliance in AMER, EMEA, and APAC.
Why it matters: Companies subject to ISO and PCI compliance requirements can now run all their workloads on EKS! Our support for EKS is in beta, and if you’re interested in getting access, email us at support@gruntwork.io!
What to do about it: Check out the announcement post for more info.



- No-nonsense DevOps insights
- Expert guidance
- Latest trends on IaC, automation, and DevOps
- Real-world best practices



