
Part 1: Network Configuration, Kubernetes, Microservices, and Load Balancing
This blog series will take you on a guided tour of a modern production-grade architecture for AWS. You’ll see what an end-to-end solution looks like, including how to combine Kubernetes, AWS VPCs, data stores, CI/CD, secrets management, and a whole lot more to deploy your applications for production use. We’ll cover both the specific choices and patterns employed in the architecture, as well as why some of those patterns make sense in the context of AWS.
Earlier we released a comprehensive checklist that lists out everything you need to go to production on AWS. This checklist is our guide to the best practices for deploying secure, scalable, and highly available infrastructure in AWS. In this series, we’ll dive into various parts of this checklist, including:
- This post: Network Configuration, Kubernetes, Microservices, and Load Balancing
- CI/CD, Multiple Accounts, Secrets Management, CDN, VPN, and Monitoring
- Bootstrap Your Production-Grade Infrastructure in a Day
Production-Grade Infrastructure
Our focus in this series is to walk through an end to end infrastructure on AWS that is production-grade. Note that this is NOT a guide for just “getting started” with AWS or for side projects. This is for companies that need reliable infrastructure for production use cases. Your company is placing a bet on you: it’s betting that your infrastructure won’t fall over if traffic goes up, or lose your data if there’s an outage, or allow that data to be compromised when hackers try to break in — and if that bet doesn’t work out, your company may go out of business. That’s what is at stake when I refer to production-grade infrastructure here.
The Architecture
Now that we have defined what it means to have production-grade infrastructure, let’s dive into how to build one!
In this series, you will build up the end-to-end architecture piece by piece, starting with:
- How to isolate environments at the network layer
- How to deploy and manage your applications
- How to expose your applications to serve traffic
- How to handle stateful data in your environment
Isolating Environments at the Network Layer
Typically in any application, you will want to support multiple environments. At a minimum, you want at least two environments:
- A staging environment for testing new versions.
- A production environment used for serving the application to end users.
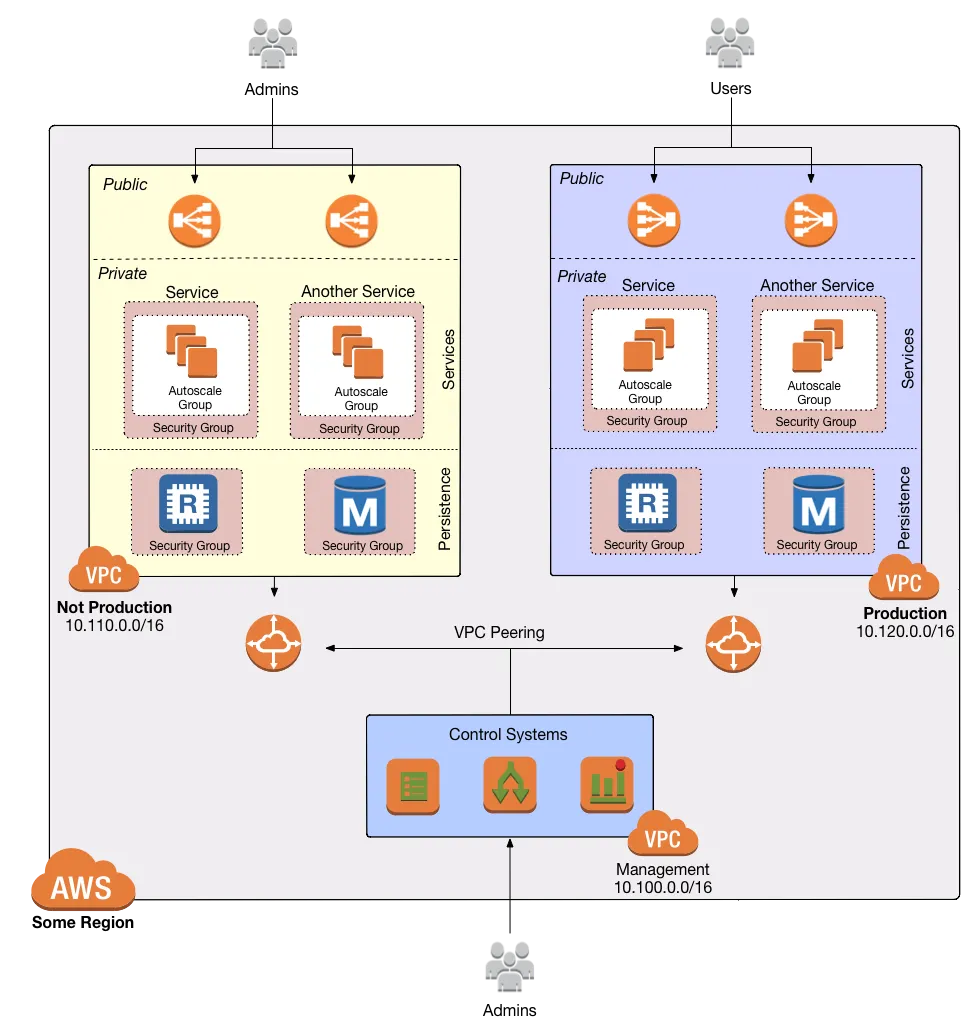
To support multiple environments, you need to figure out how to isolate the infrastructure across the environments so that failures in one environment do not propagate to others. In AWS, you can use VPCs to isolate the network across multiple environments.
We recommend deploying your VPCs to closely resemble Ben Whaley’s VPC Reference Architecture, separating the concerns between a Management VPC and an Application VPC.
The Management VPC acts as the gateway for operators to reach into the Application VPCs, and contains services such as:
- CI/CD
- Monitoring utilities
- VPN servers and Bastion hosts
The Application VPC, on the other hand, contains all your services:
- EKS, both the control plane and the worker nodes
- Lambda functions
- RDS
- ElastiCache
- Any other data stores (e.g ELK)
Each VPC is further divided into tiers by subnet:
- Public subnets: accessible from the public Internet. Used solely for highly locked down entrypoints, such as load balancers and VPN servers.
- Private app subnets: used to run apps. Only accessible from within the VPC.
- Private persistence subnets: used to run data stores. Only accessible from within the VPC. In fact, only from private app subnets.
You can then enforce the tiered access through the use of Security Group rules and Network ACLs so that you can only access deeper layers from the higher layers. This multi-layer strategy allows for Defense in Depth, providing multiple controls for protecting the network such that a failure in one will not compromise the whole system.
One thing to note is that in a multi-account deployment (see the next post for why you would want multiple accounts) you should deploy this setup in each account. By having separate Management VPCs for each account, you are able to have better control over access management of a particular environment at the network level. This setup improves your security posture, as an attacker that manages to break into the management VPC of a pre-prod environment still has 0 access to prod. It also reduces brittleness, as a dev working in a pre-prod environment has very little chance of accidentally breaking something in prod.
Deploying and Managing Your Applications
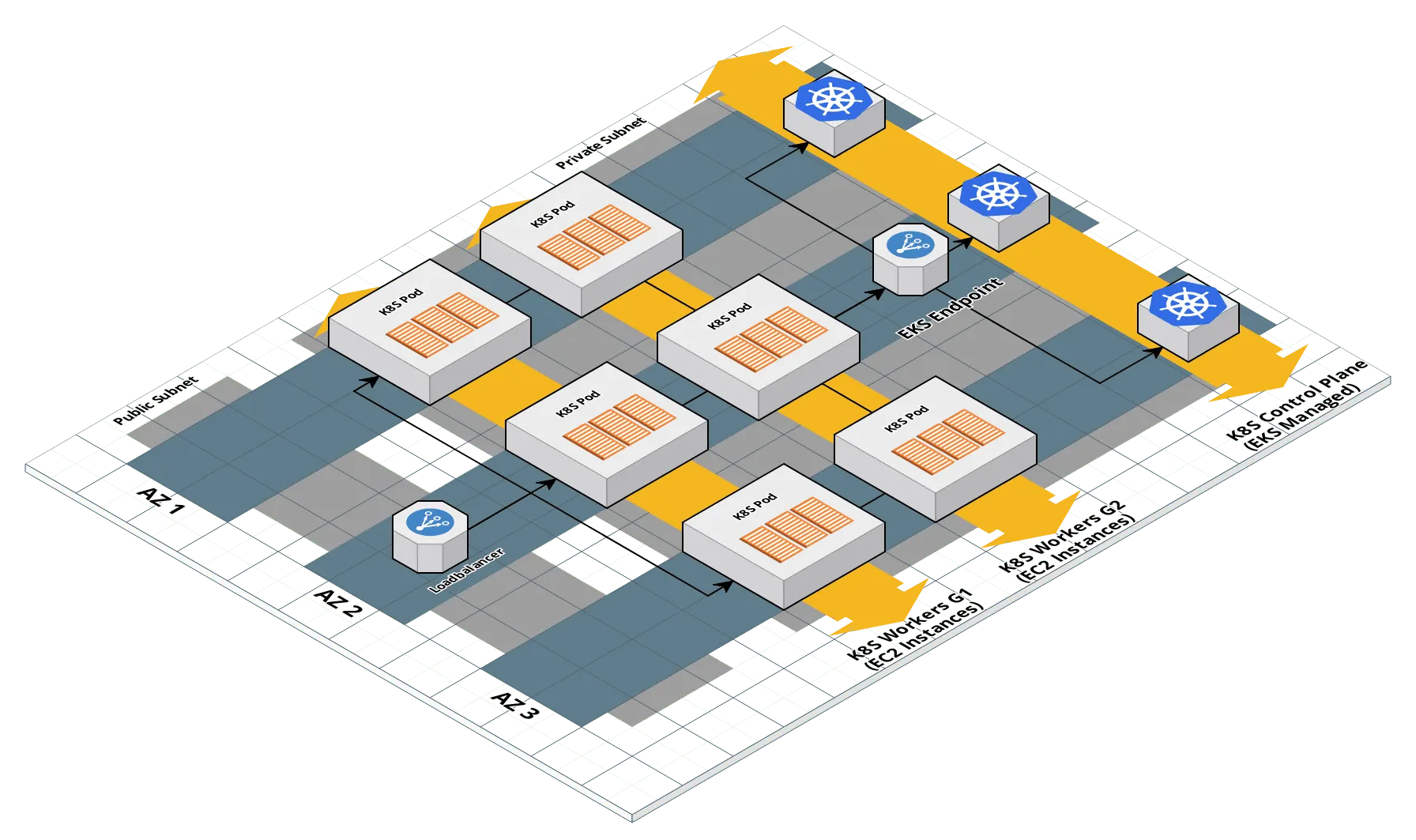
For any environment, you will need a place to run your applications. In this series, we will assume that all your applications are containerized. The best way to run containerized applications is to use a container orchestration system.
A popular option for container orchestration is Kubernetes. In AWS, we recommend using EKS to run Kubernetes, primarily because it reduces the overhead of running Kubernetes in production. EKS (or Elastic Container Service for Kubernetes) is a managed service offered by AWS, where AWS takes care of running the Kubernetes control plane for you so that you don’t have to explicitly handle all the concerns such as fault tolerance and backups. The Kubernetes control plane relies on multiple distributed systems each with its own set of challenges. You can save a lot of time and stress by letting AWS handle all the infrastructure related to the most complex components of running Kubernetes.
We recommend setting up each EKS cluster in the architecture to follow industry best practices. This means:
- Centralized access logs for the Kubernetes Control Plane.
- Locking down the API endpoint so you can only access it from within the VPC (e.g., over VPN).
- Highly available and scalable worker nodes using Auto Scaling Groups.
- Access Control and Authorization, managed through carefully selected default permission sets (via RBAC) and authentication credentials.
- fluentd to centralize container and Kubernetes logging, configured to stream to CloudWatch logs.
- AWS ALB Ingress Controller for managing ALBs using Kubernetes Ingress resources.
- external-dns for managing Route 53 domains using annotations on the Ingress resources.
We also recommend setting up a package manager for reusable Kubernetes deployments. One popular option you can use is Helm, which has a wide range of existing Charts for common applications. If you are using Helm v2, you will need to deploy Tiller, the server component of Helm. We recommend setting up your Tiller deployments in the following way:
- An admin Tiller deployment in the
kube-systemNamespace that is locked down using all the security features including: Service Accounts with scoped permissions, TLS authentication, and Secrets for metadata storage, (see our comprehensive guide to Helm for an overview). - A dedicated Namespace for your applications, with a separate Tiller deployment that is only configured to access the application namespace.
You should also setup each environment with its own EKS cluster, instead of relying on Kubernetes Namespaces. Similar to VPCs, avoiding shared pools of resources between environments ensures that a misconfiguration in one environment will not lead to a denial of service in the others.
If you do wish to share clusters for cost optimization, we recommend that at the very least you isolate your non-production environments into a separate cluster from your production environment. You do not want one runaway deployment in pre-prod to take up all the available workers from your cluster such that you can’t scale your production deployment.
Exposing Your Applications to Serve Traffic
Once you have an EKS cluster, you can use Kubernetes to run and manage your applications. You can use Kubernetes Deployments, which will manage the containerized applications as Pods. Deployments provide a declarative way to run many instances of your containers as a set, ignoring the details of how to run them. For example, if you specify in the Deployment that there should be 3 instances of your application, Kubernetes will handle the details of scheduling those Pods such that there will always be 3 instances running at a time. This includes auto launching new Pods if they start failing and shutdown on the cluster.
Deployments provide a clean interface to manage your containers on the cluster, but you also need a way to expose them so that they can be used by your end users. You can use Services and Ingress resources for this purpose.
The Service resource in Kubernetes provides a stable endpoint for accessing Pods managed by a Deployment. Since Pods are designed to come and go, the number of available endpoints for your application constantly changes. Services acts as a registry of endpoints that are known to serve your application at a given point in time. Note that Services are usually only accessible within your Kubernetes cluster. To expose them externally, you can either use special Services that map to external load balancers on the cloud platform, or Ingress resources if you have web based HTTP applications.
Ingress resources provide a way to configure HTTP based load balancers that can perform things like:
- SSL/TLS termination
- Path based routing
- Host based routing
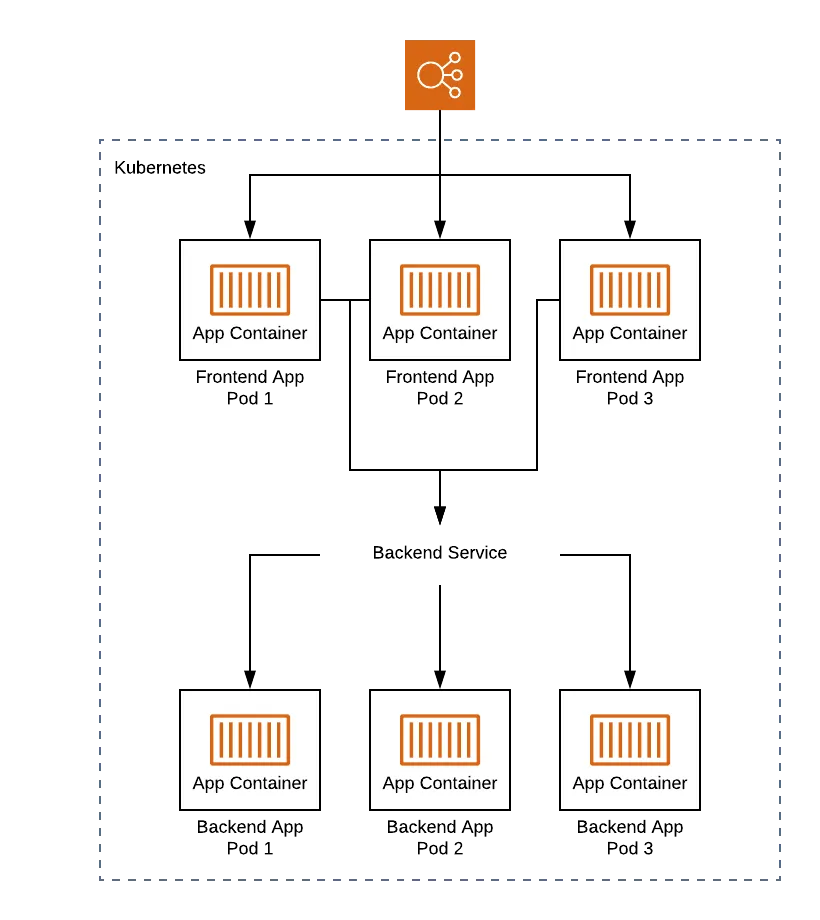
To put all these concerns into context, let’s consider a pair of microservices: a frontend service, and a backend service, designed to communicate with each other.
The frontend service (also known as an “edge service”) is designed to be the entrypoint for your consumers. This means that the service is publicly exposed with an endpoint that is accessible by end users. To do this, you can use an Ingress resource that maps to an ALB with a DNS record that routes end user traffic to our Pods to expose the service outside of the cluster.
The backend service, on the other hand, is only accessible from within the environment. Consumers indirectly access it via the frontend service by hitting specific routes that proxy the requests. To ensure the frontend service can find the backend, you will need a Service resource that exposes the backend Pods internally within the Kubernetes cluster. Once you have a Service, the frontend application can route to it via the internal Service DNS system.
Handling Stateful Data in Your Environment
For handling stateful data in your environment, we recommend using cloud managed services where possible. For example, in AWS, you can use RDS for your relational databases and Elasticache for your caching systems. While these services are less flexible (for example, RDS locks down access to the underlying VM machine, limiting the plugins you can use), you can reduce a lot of stress by offloading the hard data concerns such as backups, restore, auto patch upgrades, logging and monitoring, etc to AWS.
For those data stores that do not have managed equivalents, you have the option to run them in your Kubernetes cluster using PersistentVolumes and StatefulSets, or on dedicated EC2 instance groups. Which one to use depends on your infrastructure needs. Using Kubernetes has the advantage of unifying the interface between your volumes, applications, and data stores, but at the cost of dockerizing stateful applications. On the other hand, it is significantly easier to handle backups, restores, instance failures, etc using EC2 instances for your stateful data.
What else?
Here we covered all the concerns specifically about running a basic application in a production capacity. Head over to the next post in the series, which will cover how to isolate access to your environments, how to manage secrets for your application, how to access the internal network, deploying static websites on a CDN, and how to monitor your components.
Your entire infrastructure. Defined as code. In about a day. Gruntwork.io.
Appendix: Defense in Depth

People make mistakes all the time: forgetting to remove accounts, keeping ports open, including test credentials in production code, etc. Rather than living in an idealized model where we assume people won’t make mistakes, you can employ a Defense in Depth strategy of setting up multiple layers of protection so that a failure in any single layer doesn’t immediately lead to disaster. You never want to be one typo away from a security incident.
In the middle ages, castles were built with multiple layers of defense to ward off attackers: moat, outer wall, inner wall, keep, defenders on the walls, and so on.
Similarly, a production-grade infrastructure should include multiple layers of defense against hackers:
- Multiple AWS accounts
- Multiple VPCs
- Tiers of Subnets layered on top of each other
- Layering Security Groups with network ACLS
- Redundant clusters
- Load Balancers
- Etc.
By providing redundant controls throughout the infrastructure, you are able to minimize the chance of catastrophic failure caused by a single operator error, both in the context of system reliability and system security.



- No-nonsense DevOps insights
- Expert guidance
- Latest trends on IaC, automation, and DevOps
- Real-world best practices



