Collaboration, coding guidelines, and workflow for Terraform projects
Update, November 17, 2016: We took this blog post series, expanded it, and turned it into a book called Terraform: Up & Running!
Update, July 8, 2019: We’ve updated this blog post series for Terraform 0.12 and released the 2nd edition of Terraform: Up & Running!
Update, Sep 28, 2022: We’ve updated this blog post series for Terraform 1.2 and released the 3rd edition of Terraform: Up & Running!
This is Part 6 of the Comprehensive Guide to Terraform series. In previous parts, you learned why we picked Terraform, the basic syntax and features of Terraform, how to manage Terraform state, how to create reusable infrastructure with Terraform modules, and Terraform tips & tricks such as loops and if-statements. In this final part of the series, you’ll learn best practices for using Terraform as a team.
As you’ve been reading this blog post series and working through the code samples, you’ve most likely been working by yourself. In the real world, you’ll most likely be working as part of a team, which introduces a number of new challenges. You may need to find a way to convince your team to use Terraform and other infrastructure-as-code (IaC) tools. You may need to deal with multiple people concurrently trying to understand, use, and modify the Terraform code you write. And you may need to figure out how to fit Terraform into the rest of your tech stack and make it a part of your company’s workflow.
In this blog post, I’ll dive into the key processes you need to put in place to make Terraform and IAC work for your team:
- A workflow for deploying application code
- A workflow for deploying infrastructure code
- Putting it all together
Let’s go through these topics one at a time.
You can find working sample code for the examples in this blog post in the Terraform: Up & Running code samples repo. This blog post corresponds to Chapter 10 of Terraform Up & Running, “How to Use Terraform as a Team,” so look for the code samples in the 10-terraform-team folders.
A workflow for deploying application code
In this section, I’ll introduce a typical workflow for taking application code (e.g., a Ruby on Rails or Java/Spring app) from development all the way to production. This workflow is reasonably well understood in the DevOps industry, so you’ll probably be familiar with parts of it. Later in this blog post, I’ll talk about a workflow for taking infrastructure code (e.g., Terraform modules) from development to production. This workflow is not nearly as well known in the industry, so it will be helpful to compare that workflow side by side with the application workflow to understand how to translate each application code step to an analogous infrastructure code step.
Here’s what the application code workflow looks like:
- Use version control
- Run the code locally
- Make code changes
- Submit changes for review
- Run automated tests
- Merge and release
- Deploy
Let’s go through these steps one at a time.
Use version control
All of your code should be in version control. No exceptions. It was the #1 item on the classic Joel Test when Joel Spolsky created it nearly 20 years ago, and the only things that have changed since then are that (a) with tools like GitHub, it’s easier than ever to use version control and (b) you can represent more and more things as code. This includes documentation (e.g., a README written in Markdown), application configuration (e.g., a config file written in YAML), specifications (e.g., test code written with RSpec), tests (e.g., automated tests written with JUnit), databases (e.g., schema migrations written in ActiveRecord), and of course, infrastructure.
As in the rest of this blog post series, I’m going to assume that you’re using Git for version control. For example, here is how you can check out the sample code repo for this blog post series and the book Terraform: Up & Running:
git clone https://github.com/brikis98/terraform-up-and-running-code.gitBy default, this checks out the main branch of your repo, but you’ll most likely do all of your work in a separate branch. Here’s how you can create a branch called example-feature and switch to it by using the git checkout command:
$ cd terraform-up-and-running-code
$ git checkout -b example-feature
Switched to a new branch 'example-feature'Run the code locally
Now that the code is on your computer, you can run it locally. For example, if you had a simple web server written in a general purpose programming language such as Ruby, you might run it as follows:
$ ruby web-server.rb[2019-06-15 15:43:17] INFO WEBrick 1.3.1
[2019-06-15 15:43:17] INFO ruby 2.3.7 (2018-03-28)
[2019-06-15 15:43:17] INFO WEBrick::HTTPServer#start: port=8000Now you can manually test it with curl:
$ curl http://localhost:8000
Hello, WorldAlternatively, you might have some automated tests you can run for the web server:
$ ruby web-server-test.rb(...)Finished in 0.633175 seconds.
--------------------------------------------
8 tests, 24 assertions, 0 failures, 0 errors
100% passed
--------------------------------------------The key thing to notice is that both manual and automated tests for application code can run completely locally on your own computer. You’ll see later in this blog post that this is not true for the same part of the workflow for infrastructure changes.
Make code changes
Now that you can run the application code, you can start making changes. This is an iterative process where you make a change, re-run you manual or automated tests to see if the change worked, make another change, re-run the tests, and so on.
For example, you can change the output of your Ruby web server to “Hello, World v2”, restart the server, and see the result:
$ curl http://localhost:8000
Hello, World v2You might also update and rerun the automated tests. The idea in this part of the workflow is to optimize the feedback loop so that the time between making a change and seeing whether it worked is minimized.
As you work, you should regularly be committing your code, with clear commit messages explaining the changes you’ve made:
$ git commit -m "Updated Hello, World text"Submit changes for review
Eventually, the code and tests will work the way you want them to, so it’s time to submit your changes for a code review. You can do this with a separate code review tool (e.g., Phabricator or ReviewBoard) or, if you’re using GitHub, you can create a pull request. There are several different ways to create a pull request. One of the easiest is to git push your example-feature branch back to origin (that is, back to GitHub itself), and GitHub will automatically print out a pull request URL in the log output:
$ git push origin example-feature
(...)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
remote:
remote: Create a pull request for 'example-feature' on GitHub:
remote: https://github.com/<OWNER>/<REPO>/pull/new/example-feature
remote:Open that URL in your browser, fill out the pull request title and description, and click create. Your team members will now be able to review your code changes:
Run automated tests
You should set up commit hooks to run automated tests for every commit you push to your version control system. The most common way to do this is to use a continuous integration (CI) server, such as Jenkins, CircleCI, or GitHub Actions. Most popular CI servers have integrations built in specifically for GitHub, so not only does every commit automatically run tests, but the output of those tests shows up in the pull request itself:
You can see in the image above that CircleCI has run unit tests, integration tests, end- to-end tests, and some static analysis checks (in the form of security vulnerability scanning using a tool called snyk) against the code in the branch, and everything passed.
Merge and release
Your team members should review your code changes, looking for potential bugs, enforcing coding guidelines (more on this later), checking that the existing tests passed, and ensuring that you’ve added tests for any new behavior. If everything looks good, your code can be merged into the main branch.
The next step is to release the code. If you’re using immutable infrastructure practices, releasing application code means packaging that code into a new, immutable, versioned artifact. Depending on how you want to package and deploy your application, the artifact can be a new Docker image, a new virtual machine image (e.g., new AMI), a new .jar file, a new .tar file, etc. Whatever format you pick, make sure the artifact is immutable (i.e., you never change it) and that it has a unique version number (so you can distinguish this artifact from all of the others).
For example, if you are packaging your application using Docker, you can store the version number in a Docker tag. You could use the ID of the commit (the sha1 hash) as the tag so that you can map the Docker image you’re deploying back to the exact code it contains:
$ commit_id=$(git rev-parse HEAD)
$ docker build -t brikis98/ruby-web-server:$commit_id .The preceding code will build a new Docker image called brikis98/ruby-web-server and tag it with the ID of the most recent commit, which will look something like 92e3c6380ba6d1e8c9134452ab6e26154e6ad849. Later on, if you’re debugging an issue in a Docker image, you can see the exact code it contains by checking out the commit ID the Docker image has as a tag:
$ git checkout 92e3c6380ba6d1e8c9134452ab6e26154e6ad849
HEAD is now at 92e3c63 Updated Hello, World textOne downside to commit IDs is that they aren’t very readable or memorable. An alternative is to create a Git tag:
$ git tag -a "v0.0.4" -m "Update Hello, World text"
$ git push --follow-tagsA tag is a pointer to a specific Git commit but with a friendlier name. You can use this Git tag on your Docker images:
$ git_tag=$(git describe --tags)
$ docker build -t brikis98/ruby-web-server:$git_tag .Thus, when you’re debugging, check out the code at a specific tag:
$ git checkout v0.0.4
Note: checking out 'v0.0.4'.
(...)
HEAD is now at 92e3c63 Updated Hello, World textDeploy
Now that you have a versioned artifact, it’s time to deploy it. There are many different ways to deploy application code, depending on the type of application, how you package it, how you wish to run it, your architecture, what tools you’re using, and so on. Here are a few of the key considerations:
- Deployment tooling
- Deployment strategies
- Deployment server
- Promote artifacts across environments
Deployment tooling
There are many different tools that you can use to deploy your application, depending on how you package it and how you want to run it. Here are a few examples:
- Terraform. As you’ve seen in this blog post series, you can use Terraform to deploy certain types of applications. For example, in earlier parts of the series, you created a module that could deploy an Auto Scaling Group (ASG). If you package your application as an AMI (e.g., using Packer), you could deploy new AMI versions with the ASG module by updating the
amiparameter in your Terraform code and runningterraform apply. - Orchestration tools. There are a number of orchestration tools designed to deploy and manage applications, such as Kubernetes (arguably the most popular Docker orchestration tool), Amazon ECS, HashiCorp Nomad, and Apache Mesos.
- Scripts. Terraform and most orchestration tools support only a limited set of deployment strategies (discussed in the next section). If you have more complicated requirements, you may have to write custom scripts to implement these requirements.
Deployment strategies
There are a number of different strategies that you can use for application deployment, depending on your requirements. Suppose that you have five copies of the old version of your app running, and you want to roll out a new version. Here are a few of the most common strategies you can use:
- Rolling deployment with replacement. Take down one of the old copies of the app, deploy a new copy to replace it, wait for the new copy to come up and pass health checks, start sending the new copy live traffic, and then repeat the process until all of the old copies have been replaced. Rolling deployment with replacement ensures that you never have more than five copies of the app running, which can be useful if you have limited capacity (e.g., if each copy of the app runs on a physical server) or if you’re dealing with a stateful system where each app has a unique identity (e.g., this is often the case with consensus systems, such as Apache ZooKeeper). Note that this deployment strategy can work with larger batch sizes (you can replace more than one copy of the app at a time if you can handle the load and won’t lose data with fewer apps running) and that during deployment, you will have both the old and new versions of the app running at the same time.
- Rolling deployment without replacement. Deploy one new copy of the app, wait for the new copy to come up and pass health checks, start sending the new copy live traffic, undeploy an old copy of the app, and then repeat the process until all the old copies have been replaced. Rolling deployment without replacement works only if you have flexible capacity (e.g., your apps run in the cloud, where you can spin up new virtual servers any time you want) and if your application can tolerate more than five copies of it running at the same time. The advantage is that you never have less than five copies of the app running, so you’re not running at a reduced capacity during deployment. Note that this deployment strategy can also work with larger batch sizes (if you have the capacity for it, you can deploy five new copies all at once) and that during deployment, you will have both the old and new versions of the app running at the same time.
- Blue-green deployment. Deploy five new copies of the app, wait for all of them to come up and pass health checks, shift all live traffic to the new copies at the same time, and then undeploy the old copies. Blue-green deployment works only if you have flexible capacity (e.g., your apps run in the cloud, where you can spin up new virtual servers any time you want) and if your application can tolerate more than five copies of it running at the same time. The advantage is that only one version of your app is visible to users at any given time and that you never have less than five copies of the app running, so you’re not running at a reduced capacity during deployment.
- Canary deployment. Deploy one new copy of the app, wait for it to come up and pass health checks, start sending live traffic to it, and then pause the deployment. During the pause, compare the new copy of the app, called the “canary,” to one of the old copies, called the “control.” You can compare the canary and control across a variety of dimensions: CPU usage, memory usage, latency, throughput, error rates in the logs, HTTP response codes, and so on. Ideally, there’s no way to tell the two servers apart, which should give you confidence that the new code works just fine. In that case, you unpause the deployment and use one of the rolling deployment strategies to complete it. On the other hand, if you spot any differences, then that may be a sign of problems in the new code, and you can cancel the deployment and undeploy the canary before the problem becomes worse. The name comes from the “canary in a coal mine” concept, where miners would take canary birds with them down into the tunnels, and if the tunnels filled with dangerous gases (e.g., carbon monoxide), those gases would affect the canary before the miners, thus providing an early warning to the miners that something was wrong and that they needed to exit immediately, before more damage was done. The canary deployment offers similar benefits, giving you a systematic way to test new code in production in a way that, if something goes wrong, you get a warning early on, when it has affected only a small portion of your users and you still have enough time to react and prevent further damage. Canary deployments are often combined with feature toggles, in which you wrap all new features in an if-statement. By default, the if-statement defaults to false, so the new feature is toggled off when you initially deploy the code. Because all new functionality is off, when you deploy the canary server, it should behave identically to the control, and any differences can be automatically flagged as a problem and trigger a rollback. If there were no problems, later on you can enable the feature toggle for a portion of your users via an internal web interface. For example, you might initially enable the new feature only for employees; if that works well, you can enable it for 1% of users; if that’s still working well, you can ramp it up to 10%; and so on. If at any point there’s a problem, you can use the feature toggle to ramp the feature back down. This process allows you to separate deployment of new code from release of new features.
Deployment server
You should run the deployment from a CI server and not from a developer’s computer. This has the following benefits:
- Fully automated. To run deployments from a CI server, you’ll be forced to fully automate all deployment steps. This ensures that your deployment process is captured as code, that you don’t miss any steps accidentally due to manual error, and that the deployment is fast and repeatable.
- Consistent environment. If developers run deployments from their own computers, you’ll run into bugs due to differences in how their computer is configured: for example, different operating systems, different dependency versions (different versions of Terraform), different configurations, and differences in what’s actually being deployed (e.g., the developer accidentally deploys a change that wasn’t committed to version control). You can eliminate all of these issues by deploying everything from the same CI server.
- Better permissions management. Instead of giving every developer permissions to deploy, you can give solely the CI server those permissions (especially for the production environment). It’s a lot easier to enforce good security practices for a single server than it is to do for numerous developers with production access.
Promote artifacts across environments
If you’re using immutable infrastructure practices, the way to roll out new changes is to promote the exact same versioned artifact from one environment to another. For example, if you have dev, staging, and production environments, to roll out v0.0.4 of your app, you would do the following:
- Deploy
v0.0.4of the app todev. - Run your manual and automated tests in
dev. - If
v0.0.4works well indev, repeat steps 1 and 2 to deployv0.0.4tostage(this is known as promoting the artifact). - If
v0.0.4works well instage, repeat steps 1 and 2 again to promotev0.0.4toprod.
Because you’re running the exact same artifact everywhere, there’s a good chance that if it works in one environment, it will work in another. And if you do hit any issues, you can roll back anytime by deploying an older artifact version.
A workflow for deploying infrastructure code
Now that you’ve seen the workflow for deploying application code, it’s time to dive into the workflow for deploying infrastructure code. In this section, when I say “infrastructure code,” I mean code written with any IaC tool (including, of course, Terraform) that you can use to deploy arbitrary infrastructure changes beyond a single application: for example, deploying databases, load balancers, network configurations, DNS settings, and so on.
Here’s what the infrastructure code workflow looks like:
- Use version control
- Run the code locally
- Make code changes
- Submit changes for review
- Run automated tests
- Merge and release
- Deploy
On the surface, it looks identical to the application workflow, but under the hood, there are important differences. Deploying infrastructure code changes is more complicated, and the techniques are not as well understood, so being able to relate each step back to the analogous step from the application code workflow should make it easier to follow along. Let’s dive in.
Use version control
Just as with your application code, all of your infrastructure code should be in version control. This means that you’ll use git clone to check out your code, just as before. However, version control for infrastructure code has a few extra requirements:
- Live repo and modules repo
- Golden rule of Terraform
- The trouble with branches
Live repo and modules repo
As discussed in How to create reusable infrastructure with Terraform modules, you will typically want at least two separate version control repositories for your Terraform code: one repo for modules and one repo for live infrastructure. The repository for modules is where you create your reusable, versioned modules, such as all the modules you built in the previous parts of this blog post series (the ASG module, the RDS module, etc). The repository for live infrastructure defines the live infrastructure you’ve deployed in each environment (dev, stage, prod, etc.).
One pattern that works well is to have one infrastructure team in your company that specializes in creating reusable, robust, production-grade modules. This team can create remarkable leverage for your company by building a library of production-grade infrastructure modules; that is, each module has a composable API, is thoroughly documented (including executable documentation in the examples folder), has a comprehensive suite of automated tests, is versioned, and implements all of your company’s requirements from the production-grade infrastructure checklist (i.e., security, compliance, scalability, high availability, monitoring, and so on).
If you build such a library (or you buy one off the shelf), all the other teams at your company will be able to consume these modules, a bit like a service catalog, to deploy and manage their own infrastructure, without (a) each team having to spend months assembling that infrastructure from scratch or (b) the Ops team becoming a bottleneck because it must deploy and manage the infrastructure for every team. Instead, the Ops team can spend most of its time writing infrastructure code, and all of the other teams will be able to work independently, using these modules to get themselves up and running. And because every team is using the same canonical modules under the hood, as the company grows and requirements change, the Ops team can push out new versions of the modules to all teams, ensuring everything stays consistent and maintainable.
Or it will be maintainable, as long as you follow the Golden Rule of Terraform.
The Golden Rule of Terraform
Here’s a quick way to check the health of your Terraform code: go into your live repository, pick several folders at random, and run terraform plan in each one. If the output is always “no changes,” that’s great, because it means that your infrastructure code matches what’s actually deployed. If the output sometimes shows a small diff, and you hear the occasional excuse from your team members (“Oh, right, I tweaked that one thing by hand and forgot to update the code”), your code doesn’t match reality, and you might soon be in trouble. If terraform plan fails completely with weird errors, or every plan shows a gigantic diff, your Terraform code has no relation at all to reality and is likely useless.
The gold standard, or what you’re really aiming for, is what I call The Golden Rule of Terraform:
The main branch of the live repository should be a 1:1 representation of what’s actually deployed in production.
Let’s break this sentence down, starting at the end and working our way back:
- “…what’s actually deployed”: The only way to ensure that the Terraform code in the live repository is an up-to-date representation of what’s actually deployed is to never make out-of-band changes. After you begin using Terraform, do not make changes via a web UI, or manual API calls, or any other mechanism. As you saw in Terraform tips & tricks: loops, if-statements, and pitfalls, out-of-band changes not only lead to complicated bugs, but they also void many of the benefits you get from using IaC in the first place.
- “…a 1:1 representation…”: If I browse your live repository, I should be able to see, from a quick scan, what resources have been deployed in what environments. That is, every resource should have a 1:1 match with some line of code checked into the live repo. This seems obvious at first glance, but it’s surprisingly easy to get it wrong. One way to get it wrong, as I just mentioned, is to make out-of-band changes so that the code is there, but the live infrastructure is different. A more subtle way to get it wrong is to use Terraform workspaces to manage environments so that the live infrastructure is there, but the code isn’t. That is, if you use workspaces, your live repo will have only one copy of the code, even though you may have 3 or 30 environments deployed with it. From merely looking at the code, there will be no way to know what’s actually deployed, which will lead to mistakes and make maintenance complicated. Therefore, instead of using workspaces to manage environments, you want each environment defined in a separate folder, using separate files, so that you can see exactly what environments have been deployed just by browsing the live repository. Later in this blog post, you’ll see how to do this with minimal copying and pasting.
- “The main branch…”: You should have to look at only a single branch to understand what’s actually deployed in production. Typically, that branch will be
main. This means that all changes that affect the production environment should go directly intomain(you can create a separate branch but only to create a pull request with the intention of merging that branch intomain), and you should runterraform applyonly for the production environment against themainbranch. In the next section, I’ll explain why.
The trouble with branches
In How to manage Terraform state, you saw that you can use the locking mechanisms built into Terraform backends to ensure that if two team members are running terraform apply at the same time on the same set of Terraform configurations, their changes do not overwrite each other. Unfortunately, this only solves part of the problem. Even though Terraform backends provide locking for Terraform state, they cannot help you with locking at the level of the Terraform code itself. In particular, if two team members are deploying the same code to the same environment but from different branches, you’ll run into conflicts that locking can’t prevent.
For example, suppose that one of your team members, Anna, makes some changes to the Terraform configurations for an app called “foo” that consists of a single EC2 Instance:
resource "aws_instance" "foo" {
ami = data.aws_ami.ubuntu.id
instance_type = "t2.micro"
}The app is getting a lot of traffic, so Anna decides to change the instance_type from t2.micro to t2.medium:
resource "aws_instance" "foo" {
ami = data.aws_ami.ubuntu.id
instance_type = "t2.medium"
}Here’s what Anna sees when she runs terraform plan:
$ terraform plan
(...)
Terraform will perform the following actions:
# aws_instance.foo will be updated in-place
~ resource "aws_instance" "foo" {
ami = "ami-0fb653ca2d3203ac1"
id = "i-096430d595c80cb53"
instance_state = "running"
~ instance_type = "t2.micro" -> "t2.medium"
(...)
}
Plan: 0 to add, 1 to change, 0 to destroy.Those changes look good, so she deploys them to staging.
In the meantime, Bill comes along and also starts making changes to the Terraform configurations for the same app but on a different branch. All Bill wants to do is to add a tag to the app:
resource "aws_instance" "foo" {
ami = data.aws_ami.ubuntu.id
instance_type = "t2.micro"
tags = {
Name = "foo"
}
}Note that Anna’s changes are already deployed in staging, but because they are on a different branch, Bill’s code still has the instance_type set to the old value of t2.micro. Here’s what Bill sees when he runs the plan command (the following log output is truncated for readability):
$ terraform plan
(...)
Terraform will perform the following actions:
# aws_instance.foo will be updated in-place
~ resource "aws_instance" "foo" {
ami = "ami-0fb653ca2d3203ac1"
id = "i-096430d595c80cb53"
instance_state = "running"
~ instance_type = "t2.medium" -> "t2.micro"
+ tags = {
+ "Name" = "foo"
}
(...)
}
Plan: 0 to add, 1 to change, 0 to destroy.Uh oh, he’s about to undo Anna’s instance_type change! If Anna is still testing in staging, she’ll be very confused when the server suddenly redeploys and starts behaving differently. The good news is that if Bill diligently reads the plan output, he can spot the error before it affects Anna. Nevertheless, the point of the example is to highlight what happens when you deploy changes to a shared environment from different branches.
The locking from Terraform backends doesn’t help here, because the conflict has nothing to do with concurrent modifications to the state file; Bill and Anna might be applying their changes weeks apart, and the problem would be the same. The underlying cause is that branching and Terraform are a bad combination. Terraform is implicitly a mapping from Terraform code to infrastructure deployed in the real world. Because there’s only one real world, it doesn’t make much sense to have multiple branches of your Terraform code. So for any shared environment (e.g., stage, prod), always deploy from a single branch.
Run the code locally
Now that you’ve got the code checked out onto your computer, the next step is to run it. The gotcha with Terraform is that, unlike application code, you don’t have “localhost”; for example, you can’t deploy an AWS ASG onto your own laptop. The only way to manually test Terraform code is to run it in a sandbox environment, such as an AWS account dedicated for developers (or better yet, one AWS account for each developer).
Once you have a sandbox environment, to test manually, you run terraform apply:
$ terraform apply
(...)
Apply complete! Resources: 5 added, 0 changed, 0 destroyed.
Outputs:
alb_dns_name = "hello-world-stage-xxx.us-east-2.elb.amazonaws.com"And you verify the deployed infrastructure works by using tools such as curl:
$ curl hello-world-stage-xxx.us-east-2.elb.amazonaws.com
Hello, WorldYou can write automated tests for your Terraform code using Terratest and Go, executing those tests by runninggo test in a sandbox account dedicated to testing:
$ go test -v -timeout 30m
(...)
PASS
ok terraform-up-and-running 229.492sMake code changes
Now that you can run your Terraform code, you can iteratively begin to make changes, just as with application code. Every time you make a change, you can rerun terraform apply to deploy those changes and rerun curl to see whether those changes worked:
$ curl hello-world-stage-xxx.us-east-2.elb.amazonaws.com
Hello, World v2Or you can rerun go test to make sure the tests are still passing:
$ go test -v -timeout 30m
(...)
PASS
ok terraform-up-and-running 229.492sThe only difference from application code is that infrastructure code tests typically take longer, so you’ll want to put more thought into how you can shorten the test cycle so that you can get feedback on your changes as quickly as possible. Check out Terratest’s test stages to see how to only re-run specific parts of your tests to dramatically shorten the feedback loop.
As you make changes, be sure to regularly commit your work:
$ git commit -m "Updated Hello, World text"Submit changes for review
After your code is working the way you expect, you can create a pull request to get your code reviewed, just as you would with application code. Your team will review your code changes, looking for bugs as well as enforcing coding guidelines. Whenever you’re writing code as a team, regardless of what type of code you’re writing, you should define guidelines for everyone to follow. One of my favorite definitions of “clean code” comes from an interview I did with Nick Dellamaggiore for my earlier book Hello, Startup:
If I look at a single file and it’s written by 10 different engineers, it should be almost indistinguishable which part was written by which person. To me, that is clean code. The way you do that is through code reviews and publishing your style guide, your patterns, and your language idioms. Once you learn them, everybody is way more productive because you all know how to write code the same way. At that point, it’s more about what you’re writing and not how you write it. — Nick Dellamaggiore, Infrastructure Lead at Coursera
The Terraform coding guidelines that make sense for each team will be different, so here, I’ll list a few of the common ones that are useful for most teams:
- Documentation
- Automated tests
- File layout
- Style guide
Documentation
In some sense, Terraform code is, in and of itself, a form of documentation. It describes in a simple language exactly what infrastructure you deployed and how that infrastructure is configured. However, there is no such thing as self-documenting code. Although well-written code can tell you what it does, no programming language that I’m aware of (including Terraform) can tell you why it does it.
This is why all software, including IaC, needs documentation beyond the code itself. There are several types of documentation that you can consider and have your team members require as part of code reviews:
- Written documentation. Most Terraform modules should have a README that explains what the module does, why it exists, how to use it, and how to modify it. In fact, you may want to write the README first, before any of the actual Terraform code, because that will force you to consider what you’re building and why you’re building it before you dive into the code and get lost in the details of how to build it (this is often called Readme Driven Development). Spending 20 minutes writing a README can often save you hours of writing code that solves the wrong problem. Beyond the basic README, you might also want to have tutorials, API documentation, wiki pages, and design documents that go deeper into how the code works and why it was built this way.
- Code documentation. Within the code itself, you can use comments as a form of documentation. Terraform treats any text that begins with a hash (
#) as a comment. Don’t use comments to explain what the code does; the code should do that itself. Only include comments to offer information that can’t be expressed in code, such as how the code is meant to be used or why the code uses a particular design choice. Terraform also allows every input and output variable to declare adescriptionparameter, which is a great place to describe how that variable should be used. - Example code. Every Terraform module should include example code that shows how that module is meant to be used. This is a great way to highlight the intended usage patterns and give your users a way to try your module without having to write any code, and it’s the main way to add automated tests for the module.
Automated Tests
Chapter 9 of Terraform: Up & Running is entirely focused on testing Terraform code (see also the talk Automated Testing for Terraform, Docker, Packer, Kubernetes, and More), so I won’t repeat any of that here, other than to say that infrastructure code without tests is broken. Therefore, one of the most important comments you can make in any code review is “How did you test this?”
File Layout
Your team should define conventions for where Terraform code is stored and the file layout you use. Because the file layout for Terraform also determines the way Terraform state is stored, you should be especially mindful of how file layout affects your ability to provide isolation guarantees, such as ensuring that changes in a staging environment cannot accidentally cause problems in production. In a code review, you might want to enforce the file layout described in How to manage Terraform state, which provides isolation between different environments (e.g., stage and prod) and different components (e.g., a network topology for the entire environment and a single app within that environment).
Style Guide
Every team should enforce a set of conventions about code style, including the use of whitespace, newlines, indentation, curly braces, variable naming, and so on. Although programmers love to debate spaces versus tabs and where the curly brace should go, the more important thing is that you are consistent throughout your codebase.
Terraform has a built-in fmt command that can reformat code to a consistent style automatically:
$ terraform fmtI recommend running this command as part of a commit hook to ensure that all code committed to version control uses a consistent style.
Run automated tests
Just as with application code, your infrastructure code should have commit hooks that kick off automated tests in a CI server after every commit and show the results of those tests in the pull request. Chapter 9 of Terraform: Up & Running and the talk Automated Testing for Terraform, Docker, Packer, Kubernetes, and More cover how to write automated tests for infrastructure code. There’s one other critical type of test you should run: terraform plan. The rule here is simple:
Always run plan before apply.Terraform shows the plan output automatically when you run apply, so what this rule really means is that you should always pause and read the plan output! You’d be amazed at the type of errors you can catch by taking 30 seconds to scan the “diff ” you get as an output. A great way to encourage this behavior is by integrating plan into your code review flow. For example, Atlantis is an open source tool that automatically runs terraform plan on commits and adds the plan output to pull requests as a comment:
Terraform Cloud and Terraform Enterprise, HashiCorp’s paid tools, both support running plan automatically on pull requests as well.
Merge and release
After your team members have had a chance to review the code changes and plan output and all the tests have passed, you can merge your changes into the main branch and release the code. Similar to application code, you can use Git tags to create a versioned release:
$ git tag -a "v0.0.6" -m "Updated hello-world-example text"
$ git push --follow-tagsWhereas with application code, you often have a separate artifact to deploy, such as a Docker image or VM image, since Terraform natively supports downloading code from Git, the repository at a specific tag is the immutable, versioned artifact you will be deploying.
Deploy
Now that you have an immutable, versioned artifact, it’s time to deploy it. Here are a few of the key considerations for deploying Terraform code:
- Deployment tooling
- Deployment strategies
- Deployment server
- Promote artifacts across environments
Deployment tooling
When deploying Terraform code, Terraform itself is the main tool that you use. However, there are a few other tools that you might find useful:
- **Atlantis.** The open source tool you saw earlier can not only add the
planoutput to your pull requests but also allows you to trigger aterraform applywhen you add a special comment to your pull request. Although this provides a convenient web interface for Terraform deployments, be aware that it doesn’t support versioning, which can make maintenance and debugging for larger projects more difficult. - **Terraform Cloud and Terraform Enterprise.** HashiCorp’s paid products provide a web UI that you can use to run
terraform planandterraform applyas well as manage variables, secrets, and access permissions. - **Terragrunt.** This is an open source wrapper for Terraform that fills in some gaps in Terraform. You’ll see how to use it a bit later in this blog postto deploy versioned Terraform code across multiple environments with minimal copying and pasting.
- Scripts. As always, you can write scripts in a general-purpose programming language such as Python or Ruby or Bash to customize how you use Terraform.
Deployment strategies
For most types of infrastructure changes, Terraform doesn’t offer any built-in deployment strategies: for example, there’s no way to do a blue-green deployment for a VPC change, and there’s no way to feature toggle a database change. You’re essentially limited to terraform apply, which either works or it doesn’t. A small subset of changes do support deployment strategies, such as the zero-downtime rolling deployment with ASGs using Instance Refresh, but these are the exceptions and not the norm.
Due to these limitations, it’s critical to take into account what happens when a deployment goes wrong. With an application deployment, many types of errors are caught by the deployment strategy; for example, if the app fails to pass health checks, the load balancer will never send it live traffic, so users won’t be affected. Moreover, the rolling deployment or blue-green deployment strategy can automatically roll back to the previous version of the app in case of errors.
Terraform, on the other hand, does not roll back automatically in case of errors. In part, that’s because there is no reasonable way to roll back many types of infrastructure changes: for example, if an app deployment failed, it’s almost always safe to roll back to an older version of the app, but if the Terraform change you were deploying failed, and that change was to delete a database or terminate a server, you can’t easily roll that back!
Therefore, you should expect errors to happen and ensure you have a first-class way to deal with them:
- Retries. Certain types of Terraform errors are transient and go away if you rerun
terraform apply. The deployment tooling you use with Terraform should detect these known errors and automatically retry after a brief pause. Terragrunt has automatic retries on known errors as a built-in feature. - Terraform state errors. Occasionally, Terraform will fail to save state after running
terraform apply. For example, if you lose internet connectivity partway through anapply, not only will theapplyfail, but Terraform won’t be able to write the updated state file to your remote backend (e.g., to Amazon S3). In these cases, Terraform will save the state file on disk in a file called errored.tfstate. Make sure that your CI server does not delete these files (e.g., as part of cleaning up the workspace after a build)! If you can still access this file after a failed deployment, as soon as internet connectivity is restored, you can push this file to your remote backend (e.g., to S3) using thestate pushcommand so that the state information isn’t lost:terraform state push errored.tfstate. - Errors releasing locks. Occasionally, Terraform will fail to release a lock. For example, if your CI server crashes in the middle of a
terraform apply, the state will remain permanently locked. Anyone else who tries to runapplyon the same module will get an error message saying the state is locked and showing the ID of the lock. If you’re absolutely sure this is an accidentally leftover lock, you can forcibly release it using theforce-unlockcommand, passing it the ID of the lock from that error message:terraform force-unlock <LOCK_ID>.
Deployment server
Just as with your application code, all of your infrastructure code changes should be applied from a CI server and not from a developer’s computer. You can run terraform from Jenkins, CircleCI, GitHub Actions, Terraform Cloud, Terraform Enterprise, Atlantis, or any other reasonably secure automated platform. This gives you the same benefits as with application code: it forces you to fully automate your deployment process, it ensures deployment always happens from a consistent environment, and it gives you better control over who has permissions to access production environments.
That said, permissions to deploy infrastructure code are quite a bit trickier than for application code. With application code, you can usually give your CI server a minimal, fixed set of permissions to deploy your apps; for example, to deploy to an ASG, the CI server typically needs only a few specific ec2 and autoscaling permissions. However, to be able to deploy arbitrary infrastructure code changes (e.g., your Terraform code might try to deploy a database or a VPC or an entirely new AWS account), the CI server needs arbitrary permissions — that is, admin permissions. And that’s a problem.
The reason it’s a problem is that CI servers are (a) notoriously hard to secure, (b) accessible to all the developers at your company, and (c) used to execute arbitrary code. Adding permanent admin permissions to this mix is just asking for trouble! You’d effectively be giving every single person on your team admin permissions and turning your CI server into a very high-value target for attackers.
There are a few things you can do to minimize this risk:
- Lock the CI server down. Make it accessible solely over HTTPs, require all users to be authenticated, and follow server-hardening practices (e.g., lock down the firewall, install fail2ban, enable audit logging, etc.).
- Don’t expose your CI server on the public internet. That is, run the CI server in private subnets, without any public IP, so that it’s accessible only over a VPN connection. That way, only users with valid network access (e.g., via a VPN certificate) can access your CI server at all. Note that this does have a drawback: webhooks from external systems won’t work. For example, GitHub won’t automatically be able to trigger builds in your CI server; instead, you’ll need to configure your CI server to poll your version control system for updates. This is a small price to pay for a significantly more secure CI server.
- Enforce an approval workflow. Configure your CI/CD pipeline to require that every deployment be approved by at least one person (other than the person who requested the deployment in the first place). During this approval step, the reviewer should be able to see both the code changes and the
planoutput, as one final check that things look OK beforeapplyruns. This ensures that every deployment, code change, and plan output has had at least two sets of eyes on it. - Don’t give the CI server permanent credentials. Instead of manually managed, permanent credentials (e.g., AWS access keys copy/pasted into your CI server), you should prefer to use authentication mechanisms that use temporary credentials, such as IAM roles and OIDC.
- Don’t give the CI server admin credentials.** Instead, isolate the admin credentials to a totally separate, isolated worker: e.g., a separate server, a separate container, etc. That worker should be extremely locked down, so no developers have access to it at all, and the only thing it allows is for the CI server to trigger that worker via an extremely limited remote API. For example, that worker’s API may only allow you to run specific commands (e.g.,
terraform planandterraform apply), in specific repos (e.g., your live repo), in specific branches (e.g., themainbranch), and so on. This way, even if an attacker gets access to your CI server, they still won’t have access to the admin credentials, and all they can do is request a deployment on some code that’s already in your version control system, which isn’t nearly as much of a catastrophe as leaking the admin credentials fully. Check out Gruntwork Pipelines for a real-world example of this worker pattern.
Promote artifacts across environments
Just as with application artifacts, you’ll want to promote your immutable, versioned infrastructure artifacts from environment to environment: for example, promote v0.0.6 from dev to stage to prod. The rule here is also simple:
Always test Terraform changes in pre-prod before prod.
Because everything is automated with Terraform anyway, it doesn’t cost you much extra effort to try a change in staging before production, but it will catch a huge number of errors. Testing in pre-prod is especially important because, as mentioned earlier in this post, Terraform does not roll back changes in case of errors. If you run terraform apply and something goes wrong, you must fix it yourself. This is easier and less stressful to do if you catch the error in a pre-prod environment rather than prod.
The process for promoting Terraform code across environments is similar to the process of promoting application artifacts, except there is an extra approval step, as mentioned in the previous section, where you run terraform plan and have someone manually review the output and approve the deployment. This step isn’t usually necessary for application deployments, as most application deployments are similar and relatively low risk. However, every infrastructure deployment can be completely different, and mistakes can be very costly (e.g., deleting a database), so having one last chance to look at the plan output and review it is well worth the time.
Here’s what the process looks like for promoting, for instance, v0.0.6 of a Terraform module across the dev, stage, and prod environments:
- Update the dev environment to
v0.0.6, and run terraformplan. - Prompt someone to review and approve the
plan; for example, send an automated message via Slack. - If the
planis approved, deployv0.0.6to dev by runningterraform apply. - Run your manual and automated tests in dev.
- If
v0.0.6works well in dev, repeat steps 1–4 to promotev0.0.6to staging. - If
v0.0.6works well in staging, repeat steps 1–4 again to promotev0.0.6to production.
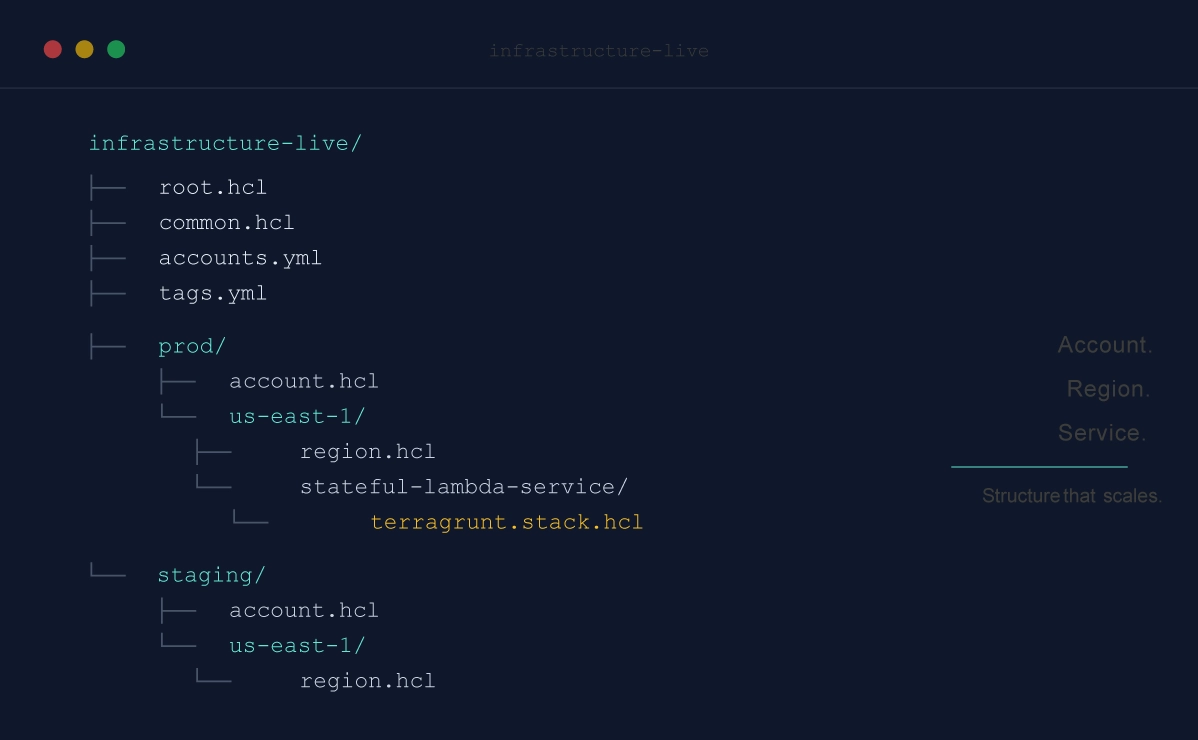
One important issue to deal with is all the code duplication between environments in the live repo. For example, consider this live repo:
This live repo has a large number of regions, and within each region, a large number of modules, most of which are copied and pasted. Sure, each module has a main.tf that references a module in your modules repo, so it’s not as much copying and pasting as it could be, but even if all you’re doing is instantiating a single module, there is still a large amount of boilerplate that needs to be duplicated between each environment:
- The
providerconfiguration - The
backendconfiguration - The input variables to pass to the module
- The output variables to proxy from the module
This can add up to dozens or hundreds of lines of mostly identical code in each module, copied and pasted into each environment. To make this code more DRY, and to make it easier to promote Terraform code across environments, you can use the open source tool I’ve mentioned earlier called Terragrunt. Terragrunt is a thin wrapper for Terraform, which means that you run all of the standard terraform commands, except you use terragrunt as the binary:
$ terragrunt plan
$ terragrunt apply
$ terragrunt outputTerragrunt will run Terraform with the command you specify, but based on configuration you specify in a terragrunt.hcl file, you can get some extra behavior. In particular, Terragrunt allows you to define all of your Terraform code exactly once in the modules repo, whereas in the live repo, you will have solely terragrunt.hcl files that provide a DRY way to configure and deploy each module in each environment. This will result in a live repo with far fewer files and lines of code:
To get started, install Terragrunt by following the instructions on the Terragrunt website. Next, add a provider configuration to modules/data-stores/mysql/main.tf and modules/services/hello-world-app/main.tf:
provider "aws" {
region = "us-east-2"
}Commit these changes and release a new version of your modules repo:
$ git add modules/data-stores/mysql/main.tf
$ git add modules/services/hello-world-app/main.tf
$ git commit -m "Update mysql and hello-world-app for Terragrunt"
$ git tag -a "v0.0.7" -m "Update Hello, World text"
$ git push --follow-tagsNow, head over to the live repo, and delete all the .tf files. You’re going to replace all that copied and pasted Terraform code with a single terragrunt.hcl file for each module. For example, here’s terragrunt.hcl for live/stage/data-stores/mysql/terragrunt.hcl:
terraform {
source = "github.com/<ORG>/modules//data-stores/mysql?ref=v0.0.7"
}inputs = {
db_name = "example_stage"
# Set the username using the TF_VAR_db_username env var
# Set the password using the TF_VAR_db_password env var
}As you can see, terragrunt.hcl files use the same HashiCorp Configuration Language (HCL) syntax as Terraform itself. When you run terragrunt apply and it finds the source parameter in a terragrunt.hcl file, Terragrunt will do the following:
- Check out the URL specified in
sourceto a temporary folder. This supports the same URL syntax as thesourceparameter of Terraform modules, so you can use local file paths, Git URLs, versioned Git URLs (with arefparameter, as in the preceding example), and so on. - Run
terraform applyin the temporary folder, passing it the input variables that you’ve specified in theinputs = { … }block.
The benefit of this approach is that the code in the live repo is reduced to just a single terragrunt.hcl file per module, which contains only a pointer to the module to use (at a specific version), plus the input variables to set for that specific environment. That’s about as DRY as you can get.
Terragrunt also helps you keep your backend configuration DRY. Instead of having to define the bucket, key, dynamodb_table, and so on in every single module, you can define it in a single terragrunt.hcl file per environment. For example, create the following in live/stage/terragrunt.hcl:
remote_state {
backend = "s3"
generate = {
path = "backend.tf"
if_exists = "overwrite"
}
config = {
bucket = "<YOUR BUCKET>"
key = "${path_relative_to_include()}/terraform.tfstate"
region = "us-east-2"encrypt = true
dynamodb_table = "<YOUR_TABLE>"
}
}From this one remote_state block, Terragrunt can generate the backend configuration dynamically for each of your modules, writing the configuration in config to the file specified via the generate param. Note that the key value in config uses a Terragrunt built-in function called path_relative_to_include(), which will return the relative path between this root terragrunt.hcl file and any child module that includes it. For example, to include this root file in live/stage/data-stores/mysql/terragrunt.hcl, add an include block:
terraform {
source = "github.com/<ORG>/modules//data-stores/mysql?ref=v0.0.7"
}include {
path = find_in_parent_folders()
}inputs = {
db_name = "example_stage"
# Set the username using the TF_VAR_db_username env var
# Set the password using the TF_VAR_db_password env var
}The include block finds the root terragrunt.hcl using the Terragrunt built-in function find_in_parent_folders(), automatically inheriting all the settings from that parent file, including the remote_state configuration. The result is that this mysql module will use all the same backend settings as the root file, and the key value will automatically resolve to data-stores/mysql/terraform.tfstate. This means that your Terraform state will be stored in the same folder structure as your live repo, which will make it easy to know which module produced which state files.
To deploy this module, run terragrunt apply:
$ terragrunt apply --terragrunt-log-level debug
DEBU[0001] Reading Terragrunt config file at terragrunt.hcl
DEBU[0001] Included config live/stage/terragrunt.hcl
DEBU[0001] Downloading configurations into .terragrunt-cache
DEBU[0001] Generated file backend.tf
DEBU[0013] Running command: terraform init
(...)
Initializing the backend...
Successfully configured the backend "s3"! Terraform will automatically use this backend unless the backend configuration changes.
(...)
DEBU[0024] Running command: terraform apply
(...)
Terraform will perform the following actions:
(...)
Plan: 5 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
(...)
Apply complete! Resources: 5 added, 0 changed, 0 destroyed.Normally, Terragrunt only shows the log output from Terraform itself, but as I included--terragrunt-log-level debug, the preceding output shows what Terragrunt does under the hood:
- Read the terragrunt.hcl file in the mysql folder where you ran
apply. - Pull in all the settings from the included root terragrunt.hcl file.
- Download the Terraform code specified in the
sourceURL into the .terragrunt- cache scratch folder. - Generate a backend.tf file with your
backendconfiguration. - Detect that
inithas not been run and run it automatically (Terragrunt will even create your S3 bucket and DynamoDB table automatically if they don’t already exist). - Run
applyto deploy changes.
Not bad for a couple of tiny terragrunt.hcl files!
You can now deploy the hello-world-app module in staging by adding live/stage/ services/hello-world-app/terragrunt.hcl and running terragrunt apply:
terraform {
source = "github.com/<ORG>/modules//services/hello-world-app?ref=v0.0.7"
}include {
path = find_in_parent_folders()
}dependency "mysql" {
config_path = "../../data-stores/mysql"
}inputs = {
environment = "stage"
ami = "ami-0fb653ca2d3203ac1"
min_size = 2
max_size = 2
enable_autoscaling = falsemysql_config = dependency.mysql.outputs
}This terragrunt.hcl file uses the source URL and inputs just as you saw before and uses include to pull in the settings from the root terragrunt.hcl file, so it will inherit the same backend settings, except for the key, which will be automatically set to services/hello-world-app/terraform.tfstate, just as you’d expect. The one new thing in this terragrunt.hcl file is the dependency block:
dependency "mysql" {
config_path = "../../data-stores/mysql"
}This is a Terragrunt feature that can be used to automatically read the output variables of another Terragrunt module, so you can pass them as input variables to the current module, as follows:
mysql_config = dependency.mysql.outputsIn other words, dependency blocks are an alternative to using terraform_remote_state data sources to pass data between modules. While terraform_remote_state data sources have the advantage of being native to Terraform, the drawback is that they make your modules more tightly coupled together, as each module needs to know how other modules store state. Using Terragrunt dependency blocks allows your modules to expose generic inputs like mysql_config and vpc_id, instead of using data sources, which makes the modules less tightly coupled and easier to test and reuse.
Once you’ve got hello-world-app working in staging, create analogous terragrunt.hcl files in live/prod and promote the exact same v0.0.7 artifact to production by running terragrunt apply in each module.
Putting it all together
You’ve now seen how to take both application code and infrastructure code from development all the way through to production. The following table shows an overview of the two workflows side-by-side:
If you follow this process, you will be able to run application and infrastructure code in dev, test it, review it, package it into versioned, immutable artifacts, and promote those artifacts from environment to environment:
Conclusion
If you’ve made it to this point in the Comprehensive Guide to Terraform series, you now know just about everything you need to use Terraform in the real world:
- Why we use Terraform and not Chef, Puppet, Ansible, Pulumi, or CloudFormation
- An introduction to Terraform
- How to manage Terraform state
- How to create reusable infrastructure with Terraform modules
- Terraform tips & tricks: loops, if-statements, and pitfalls
- How to use Terraform as a team
Thank you for reading!
For an expanded version of this blog post series, pick up a copy of the book Terraform: Up & Running (3rd edition available now!). If you need help with Terraform, DevOps practices, or AWS at your company, feel free to reach out to us at Gruntwork.



- No-nonsense DevOps insights
- Expert guidance
- Latest trends on IaC, automation, and DevOps
- Real-world best practices