
As infrastructure estates grow and more engineers concurrently contribute to the Infrastructure as Code (IaC) codebase, collaboration can become a significant challenge. State Locking, creating reusability, secrets management, etc.
Terragrunt was designed to solve all these problems. Developed by Gruntwork, Terragrunt is an open-source orchestrator for OpenTofu/Terraform that provides features to enable teams of any size to work together seamlessly, without running into common scaling issues. Its history is rooted in supporting Gruntwork customers manage infrastructure at scale, focusing on features that inherently support better collaboration and minimize the "blast radius" of changes.
Challenges we’ve helped customers overcome using Terragrunt include:
- Isolating infrastructure patterns from live infrastructure.
- Segmenting state to minimize blast radius and lock contention.
- Dynamically controlling IaC behavior at runtime.
- Error handling.
- Codifying tribal knowledge.
- Flexible authentication.
- Infrastructure self-service.
Let's explore how Terragrunt addresses each of these:
1. Isolating infrastructure patterns from live infrastructure
A core strength of Terragrunt is the way it separates the definition of an infrastructure *pattern* (like a standard VPC setup or a Kubernetes cluster configuration) from the *live instances* provisioned using that pattern.
When using OpenTofu/Terraform alone, there’s a persistent temptation to just write new infrastructure configurations by hand instead of reusing and refining existing modules. You’re authoring a `.tf` file in a root module, configuring backend configurations, provider configurations, etc. and while you *could* just directly define the resources you are going to provision, you instead remember or discover that there’s a reusable module available to you, stop what you’re doing and create a `module` reference to that instead. The usage of that module is also mixed in with the other configurations you were setting up now, so it’s not clear to external collaborators that you’re largely reusing configurations off-the-shelf.
$ tree
.
├── main.tf <-- That's where the module is referenced.
├── outputs.tf
├── README.md
└── variables.tfterraform {
required_version = ">= 1.1"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
region = var.aws_region
}
module "ecs_service" {
source = "git::git@github.com:gruntwork-io/terragrunt-infrastructure-catalog-example.git//modules/ecs-fargate-service?ref=v1.0.0"
# This is where the module is being referenced ^.
name = var.name
# Run the training/webapp Docker image from Docker Hub, a simple "Hello, World" web server
container_definitions = jsonencode([{
name = var.name
image = "training/webapp"
essential = true
memory = local.memory
portMappings = [
{
containerPort = local.container_port
}
]
# If you set the PROVIDER environment variable, docker-training/webapp will return the text "Hello, <PROVIDER>!"
Environment = [
{
name = "PROVIDER"
value = "World"
}
]
}])
desired_count = 2
cpu = 256
memory = local.memory
container_port = local.container_port
alb_port = 80
# The image used for this example only supports X86_64.
cpu_architecture = "X86_64"
}
locals {
container_port = 5000
memory = 512
}This is an exceedingly simple example, but you already have to do some significant work, potentially reading multiple OpenTofu/Terraform configuration files to establish that this module is being used, how many times it’s being used, etc. to learn from this usage and repeat this in other projects to solve similar business problems.
Terragrunt can fetch both OpenTofu/Terraform modules and Terragrunt-specific configurations (units and stacks) from remote sources just-in-time, and doing so is actually the easiest way to provision new infrastructure with Terragrunt.
$ tree
.
├── README.md
├── scripts
│ └── wait.sh
└── terragrunt.hcl <-- This is the only place the module _can_ be referenced.include "root" {
path = find_in_parent_folders("root.hcl")
}
terraform {
source = "git::git@github.com:acme/terragrunt-infrastructure-modules-example.git//modules/ecs-fargate-service?ref=v1.0.0"
# This is where the module is being referenced ^.
after_hook "wait" {
commands = ["apply"]
execute = ["${get_terragrunt_dir()}/scripts/wait.sh"]
}
}
locals {
container_port = 5000
memory = 512
name = "ecs-fargate-service-unit"
}
inputs = {
name = local.name
container_definitions = jsonencode([{
name = local.name
image = "training/webapp"
essential = true
memory = local.memory
portMappings = [
{
containerPort = local.container_port
}
]
Environment = [
{
name = "PROVIDER"
value = "World"
}
]
}])
desired_count = 2
cpu = 256
memory = local.memory
container_port = local.container_port
alb_port = 80
cpu_architecture = "X86_64"
}This file defines *nothing* except:
- How to reference reusable configurations for necessary boilerplate like state configurations, provider configurations, etc. with the first three lines.
- Configurations for provisioning one OpenTofu/Terraform module.
You can’t use this file to provision *two* OpenTofu/Terraform modules (unless they are children of that one module), and you can’t sneak bonus resources into this file that aren’t defined as part of the module (without significantly more work). As a consequence, what you’ll typically see with teams using Terragrunt is that they’ll put *all* of their code for provisioning resources in reusable modules that are versioned, and maintained independent of consumption to provision live infrastructure.
This encourages platform teams to continuously refine and test infrastructure patterns (perhaps using tools like Terratest) independently. Updates to the underlying module don't immediately force changes across all live environments. Management of live infrastructure via Terragrunt units and stacks remains a separate, versioned, controlled process, promoting stability and higher-quality patterns without blocking day-to-day operations.
Conversely, note that the only file in this directory was the `wait.sh` script referenced by the `wait` `after_hook` of the `terragrunt.hcl` file. By separating the parts of infrastructure that are reusable from those that are bespoke, Terragrunt units (directories like this that instantiate a single OpenTofu/Terraform module using a `terragrunt.hcl` file) can add logic before or after a module is provisioned, fetch data in a manner that isn’t likely to be useful elsewhere, and more, as we’ll discuss below. This pattern encourages separation of the logic for generic, reusable infrastructure and the logic for implementation details to get that infrastructure provisioned correctly.
2. Segmenting state to minimize blast radius and lock contention
When using OpenTofu/Terraform alone, every top-level directory with a `.tf` file in it where a user is expected to run `tofu` / `terraform` is what’s called a “root module”. This root module is the entry point for controlling infrastructure using OpenTofu/Terraform, and OpenTofu/Terraform enforces usage of a single state file to represent the sum total of the infrastructure managed in this root module.
This in itself is not a bad thing. It allows OpenTofu/Terraform to have a consistent view of all the infrastructure it is managing at a given time, and allows it to perform a wholistic computation of infrastructure changes.
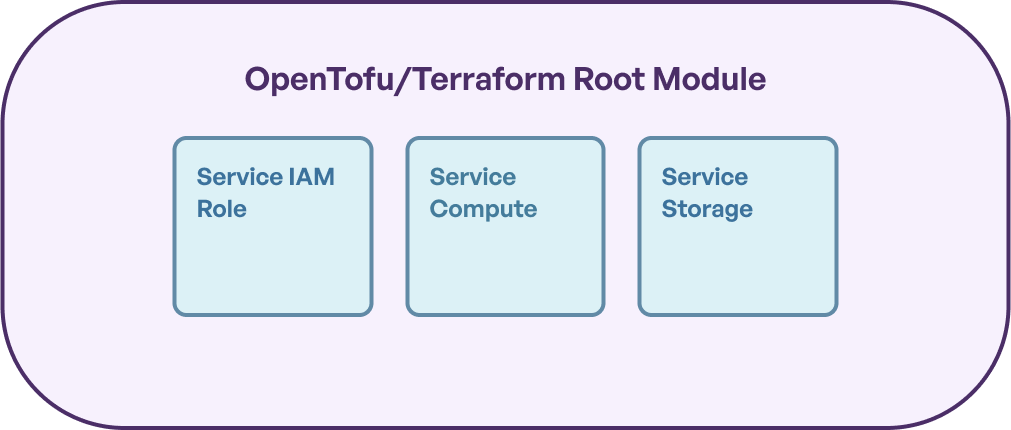
In this example, it can be a good thing that OpenTofu/Terraform is managing these different pieces of infrastructure in the same infrastructure state. It allows OpenTofu/Terraform to schedule updates to the appropriate resource in response to changing configurations, and ensuring that updates proceed in the right order.
This *becomes* a bad thing when users start to increase the volume of infrastructure they are managing with OpenTofu/Terraform. If the size of the state file starts to balloon, users encounter increased risk that *any* operation in a root module intended to impact particular infrastructure could negatively impact unrelated infrastructure.
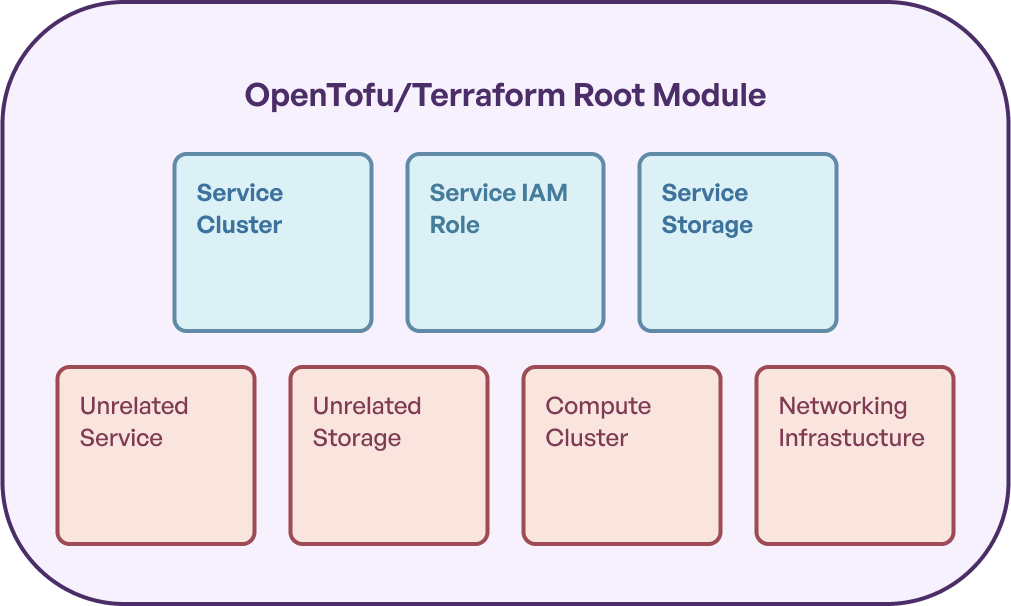
Now that more infrastructure is under management in this single piece of OpenTofu/Terraform state, any `tofu` / `terraform` command might accidentally impact infrastructure unintentionally. OpenTofu/Terraform also end up running slower the more infrastructure you are managing this way, as there’s more infrastructure to evaluate for changes.
In addition, if you are leveraging state locking, you run into the problem that locks are state specific, so any operation attempting to make any modification to state ends up blocking all updates to infrastructure by colleagues.
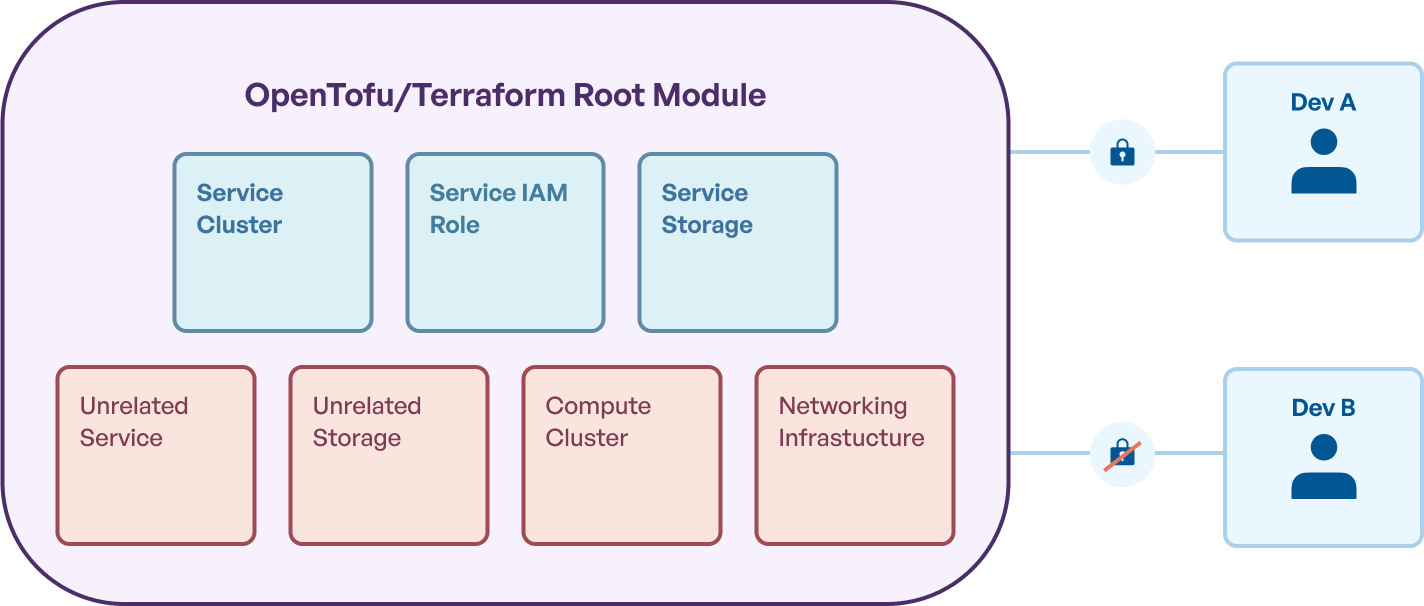
Terragrunt addresses this problem by offering tooling to make it easier to segment state, and operate across different pieces of infrastructure. Each Terragrunt unit has its own state file, and Terragrunt tooling makes it trivial to decide how many units to operate on at once.
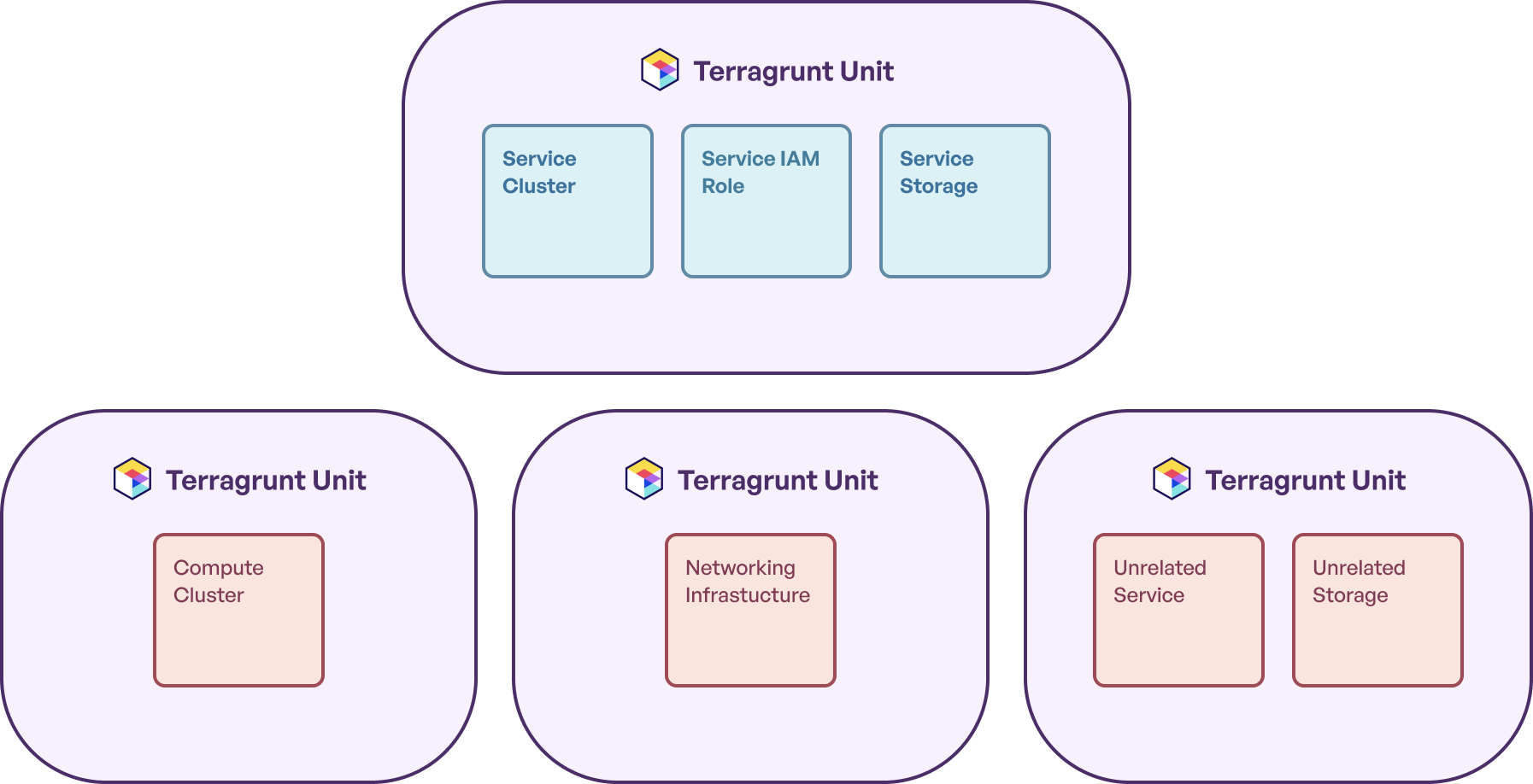
Splitting up state into multiple Terragrunt units like this allows you to decide how much infrastructure you *could possibly* update at once. If the unit isn’t in the Run Queue, the resource managed by the unit won’t get updated. Additionally, if the unit isn’t being run, the lock won’t be acquired for the backend OpenTofu/Terraform state the unit interacts with.
This can be an incredible efficiency boost for teams working on large infrastructure estates, as it allows updates that won’t conflict with each other to run without causing lock contention. In practice, this means that two engineers working on the example infrastructure estate above can concurrently make updates to those two services without interfering with each other. Each engineer gets their own lock, as the state they’re updating is completely independent.
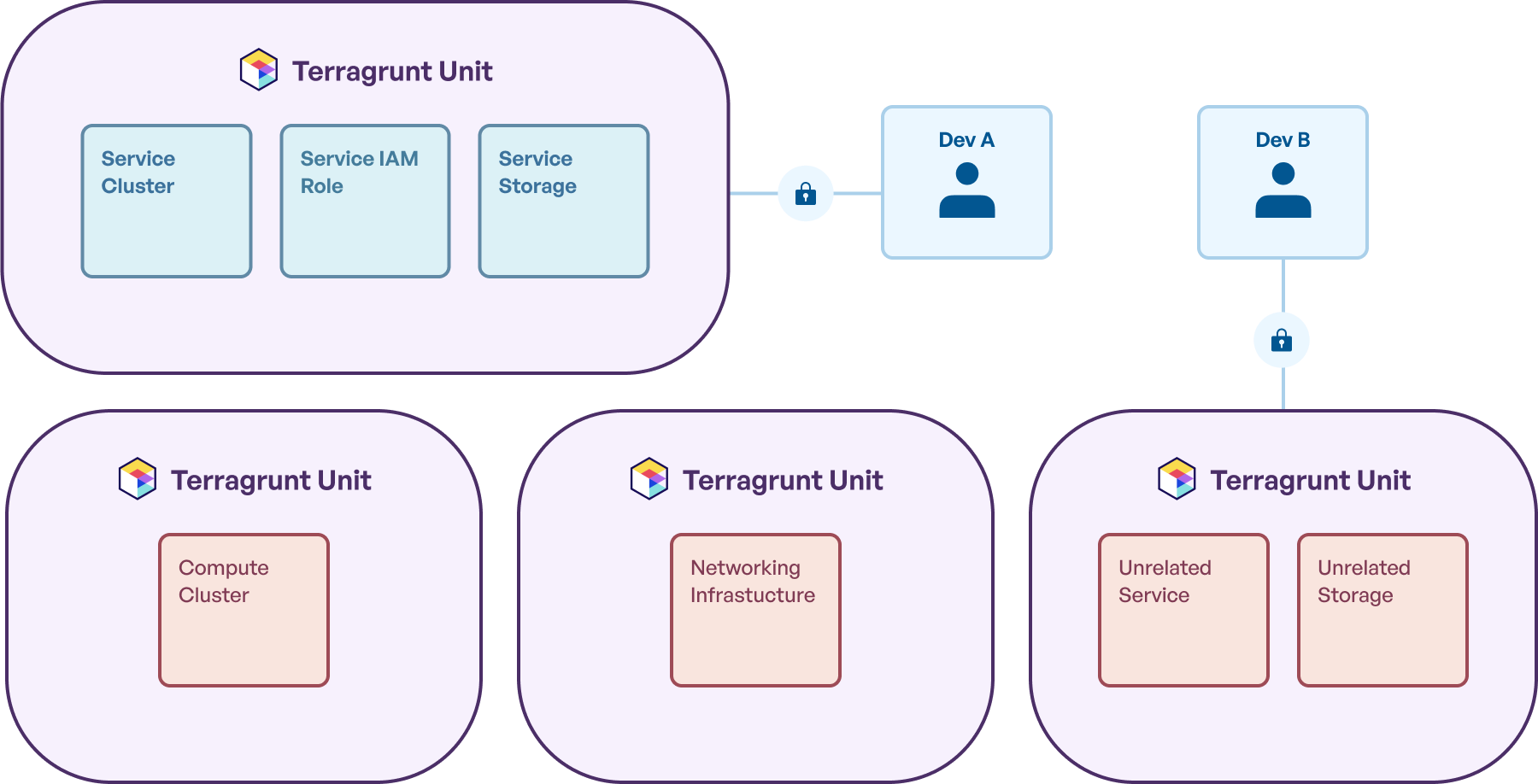
Gruntwork Pipelines, intelligently leverages this segmented state. It identifies exactly which Terragrunt configurations are affected by a pull/merge request and only plans/applies/destroys changes for those specific units, minimizing the scope (and risk) of each deployment.
3. Feature Flags for Dynamic Behavior
Continuous integration is great, but merging potentially unstable code can be risky, especially when it comes to infrastructure code.
You might have new infrastructure code that you want to introduce to try an updated OpenTofu/Terraform module, or adjust configurations like selecting different instance type for a service to save money or improve performance. You might also have multiple infrastructure changes in a new project that you want synchronized (e.g. provisioning a new service, a new database the service depends on, and a caching layer for that database).
In these scenarios, you might decide to delay integration of updates into your infrastructure codebase to make sure that they happen gradually, and in a controlled fashion. You might decide to leave open a pull request to bump the version of the module that you’re using or change the inputs to select a different instance type, to merge in a different pull request for each environment to slowly propagate the change, and to roll back changes by reverting pull requests for a particular environment. You might also delay merging in pieces of the new project until all the pieces are ready, and are merged all at once.
A classic software engineering solution to need desire to delay integration like this is to introduce continuous integration with feature flags. Instead of waiting to integrate code into the same codebase, because the behavior of that code might not be desired, you can gate the change behind a feature flag to decouple deployment of the configuration and release.
For example, say you have the following configuration for a service backed by AWS Lambda:
include "root" {
path = find_in_parent_folders("root.hcl")
}
terraform {
source = "git::git@github.com:acme/terragrunt-infrastructure-modules-example.git//modules/lambda-service?ref=v1.0.0"
}
inputs = {
name = "lambda-service-unit-example"
runtime = "nodejs22.x"
handler = "index.handler"
}— And you want to upgrade the version of the module to `v2.0.0`, which includes the introduction of the `architectures` variable to control the hardware that the Lambda runs on (AWS charges less for ARM based Lambdas than x86 based ones).
include "root" {
path = find_in_parent_folders("root.hcl")
}
terraform {
source = "git::git@github.com:acme/terragrunt-infrastructure-modules-example.git//modules/lambda-service?ref=v2.0.0"
}
inputs = {
name = "lambda-service-unit-example"
runtime = "nodejs22.x"
handler = "index.handler"
architectures = ["arm64"]
}For the sake of this example, let’s say that you would *only* want to upgrade to `v2.0.0` to take advantage of this new configuration, and you would prefer to stay on `v1.0.0` otherwise.
How would you propagate that change? Would you create a pull request to bump the version to `v2.0.0`, then another to add `architectures = ["arm64"]` to every unit that needs the change? How would you coordinate that change? Maybe leave the pull request in draft for higher environments like production, but merge it in early in lower environments like dev? How do you make sure that your on-call team knows how to revert this change if something goes wrong? Link them to the pull requests where the changes were made and make sure they have someone that can approve the pull request to revert it (or give them the right to bypass pull request approval)? How does the rest of the team integrate with this code? If they’re working on infrastructure in the same codebase, do they just keep tabs on in-flight PRs? How do they know that what you’re doing isn’t going to conflict with their changes?
All of these considerations put pressure on developers to do the work that you could be codifying in your IaC. Let’s take a look at another approach that leverages built-in Terragrunt feature flags to address this challenge.
include "root" {
path = find_in_parent_folders("root.hcl")
}
feature "use_arm" {
default = false
}
locals {
version = feature.use_arm.value ? "v2.0.0" : "v1.0.0"
architectures = feature.use_arm.value ? ["arm64"] : ["x86_64"]
}
terraform {
source = "git::git@github.com:acme/terragrunt-infrastructure-modules-example.git//modules/lambda-service?ref=${local.version}"
}
inputs = {
name = "lambda-service-unit-example"
runtime = "nodejs22.x"
handler = "index.handler"
architectures = local.architectures
}With this approach, you have two main benefits:
1. Both configurations (with the new update, and without) are codified explicitly. It’s clear to someone interacting with this unit that there are multiple configurations to evaluate.
2. You can control the configuration switch at *runtime*, rather than requiring the configuration to be statically configured for all users in all environments.
You can deploy that same configuration to all environments, while initially having zero infrastructure changes, then release the configuration update using a feature flag toggle.
export TG_FEATURE="use_arm=true"Setting that environment variable before running Terragrunt will toggle usage of the new configuration, and you can control this via CI/CD pipelines, activate it during local development while testing things out, or even integrate it with an external feature flag service so that you can centrally control the value of feature flags for each infrastructure update. Everyone else in your team gets an accurate representation of the potential infrastructure configurations they have to interact with, and the ability to toggle features on/off to control the next IaC update that uses the feature flag.
You can also combine feature flags with other configurations like the [excludes](https://terragrunt.gruntwork.io/docs/features/runtime-control/#excludes) to programmatically enable/disable the ability to update units. This allows engineers to incrementally update infrastructure, even if multiple units need to be added or edited to form a new infrastructure stack. The new infrastructure can be excluded from the [Run Queue](https://terragrunt.gruntwork.io/docs/features/run-queue/) by default, and engineers can directly update units as necessary.
4. Robust Error Handling
Real-world infrastructure provisioning isn't always perfect. Transient network issues or APIs returning non-critical errors can disrupt workflows.
Terragrunt provides a dedicated `error` configuration block to intelligently ignore or retry expected, transient, or unimportant errors during IaC operations.
errors {
# Retry block for transient errors
retry "transient_errors" {
retryable_errors = [".*Error: transient network issue.*"]
max_attempts = 3
sleep_interval_sec = 5
}
# Ignore block for known safe-to-ignore errors
ignore "known_safe_errors" {
ignorable_errors = [
".*Error: safe warning.*",
"!.*Error: do not ignore.*"
]
message = "Ignoring safe warning errors"
signals = {
alert_team = false
}
}
}For more complex error recovery scenarios, Terragrunt allows defining `error` hooks to execute custom logic when failures occur.
error_hook "error_hook" {
commands = ["apply"]
execute = ["echo", "Recovering from known error"]
on_errors = [
".*Known problematic error.*",
]
}This allows teams to integrate infrastructure updates more reliably, even when dealing with flaky underlying systems, preventing minor hiccups from blocking progress.
5. Controlled Side-Effects for Codified Practices
Sometimes, IaC operations need to interact with the outside world beyond provider APIs (e.g., packaging application code, fetching data).
Terragrunt's lifecycle hooks (`before_hook`, `after_hook`) and the `run_cmd` function allow Terragrunt to execute arbitrary commands or scripts as part of a run.
terraform {
source = "git::git@github.com:acme/terragrunt-infrastructure-modules-example.git//modules/lambda-service?ref=v1.0.0"
before_hook "package" {
commands = ["plan", "apply"]
execute = ["${get_terragrunt_dir()}/scripts/package.sh"]
}
after_hook "smoke_test" {
commands = ["apply"]
execute = ["${get_terragrunt_dir()}/scripts/smoke-test.sh"]
}
}
inputs = {
s3_object_version = run_cmd("--terragrunt-quiet", "${get_terragrunt_dir()}/scripts/get-lambda-handler-from-s3.sh")
}This keeps core OpenTofu/Terraform modules focused on defining generic infrastructure patterns, making them more reusable. Implementation-specific details or preparatory steps can be handled cleanly within the Terragrunt configuration layer, offering a powerful combination of flexibility and stability.
6. Dynamic and Flexible Authentication
Authenticating IaC tools consistently across local developer machines and CI/CD environments is a common headache. Should everyone use the same AWS profile names? Does OIDC in CI/CD hamper local development? How are permissions managed?
Terragrunt provides sophisticated options for handling authentication, simplifying these challenges. Because infrastructure is managed in smaller, isolated units (thanks to segmented state), permissions can often be granted with greater granularity (least privilege).
Terragrunt also makes it easier to define how authentication should happen in different contexts (local vs. remote) directly within your configuration.
Gruntwork Pipelines enhances this further. While preserving your ability to use various local authentication methods (profiles, environment variables, etc.), Pipelines dynamically authenticates in CI/CD using secure methods like OIDC for temporary credentials. It automatically requests short-lived, least-privilege credentials scoped specifically to the environments and actions needed (e.g., read-only for plans, read-write for applies). As part of our commercial offering, Gruntwork helps customers configure the necessary cloud provider roles (like AWS IAM Roles and OIDC Providers) correctly, ensuring security while maintaining developer flexibility.
7. Streamlined Developer Self-Service
Empowering development teams to provision infrastructure themselves safely is a key goal for many platform teams.
Terragrunt provides catalog and scaffold commands that leverage the pattern isolation discussed earlier. Platform teams can curate a catalog of pre-approved infrastructure patterns.
Developers (even those less experienced with IaC) can use a simple Terminal User Interface (TUI) provided by `terragrunt catalog` to browse available patterns and use `terragrunt scaffold` to generate desired Terragrunt configuration files based on simple inputs. This accelerates onboarding and reduces the burden on the platform team, all while maintaining high-quality standards encouraged by platform teams.

Customers using the Gruntwork Infrastructure as Code Library gain immediate access to hundreds of production-ready, battle-tested modules that integrate seamlessly with the Terragrunt catalog.
Conclusion: Scaling Collaboration with Confidence
Terragrunt embodies this philosophy, providing tangible features that directly address the collaboration bottlenecks encountered when managing growing infrastructure with IaC. By isolating components, segmenting state, and offering flexible workflows, Terragrunt minimizes the blast radius of changes and allows engineers to work together effectively and safely.
We believe Terragrunt is the best tool for managing IaC at scale, and we're constantly working to make it even better.
If you're navigating these challenges, we encourage you to:
- Join the Community: Engage with other users and the Gruntwork team on the Terragrunt Discord. It's a great place to ask questions and share your IaC experience with others.
- Explore Professional Support: If you'd like expert guidance, CI/CD automation with Gruntwork Pipelines, access to our extensive IaC Library, or to learn about our other offerings, reach out to us at sales@gruntwork.io. We're happy to provide a demo tailored to your needs and show you how the Gruntwork platform can accelerate your infrastructure journey. Helping platform teams excel is what we do.



- No-nonsense DevOps insights
- Expert guidance
- Latest trends on IaC, automation, and DevOps
- Real-world best practices


.png)
