
This is part 4 of our journey to implementing a zero downtime update of our Kubernetes cluster. In the previous two posts (part 2 and part 3), we focused on how to gracefully shutdown the existing Pods in our cluster. We covered how to use preStop hooks to gracefully shutdown pods and why it is important to add delays in the sequence to wait for the deletion event to propagate through the cluster. This can handle terminating one pod, but does not prevent us from shutting down too many pods such that our service can’t function. In this post, we will use PodDisruptionBudgets or PDB for short to mitigate this risk.
PodDisruptionBudgets: Budgeting the Number of Faults to Tolerate
A pod disruption budget is an indicator of the number of disruptions that can be tolerated at a given time for a class of pods (a budget of faults). Whenever a disruption to the pods in a service is calculated to cause the service to drop below the budget, the operation is paused until it can maintain the budget. This means that the drain event could be temporarily halted while it waits for more pods to become available such that the budget isn’t crossed by evicting the pods.
To configure a pod disruption budget, we will create a PodDisruptionBudget resource that matches the pods in the service. For example, if we wanted to create a pod disruption budget where we always want at least 1 Nginx pod to be available for our example deployment, we will apply the following config:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: nginx
This indicates to Kubernetes that we want at least 1 pod that matches the label app: nginx to be available at any given time. Using this, we can induce Kubernetes to wait for the pod in one drain request to be replaced before evicting the pods in a second drain request.
Example
To illustrate how this works, let’s go back to our example. For the sake of simplicity, we will ignore any prestop hooks, readiness probes, and service requests in this example. We will also assume that we want to do a one to one replacement of the cluster nodes. This means that we will expand our cluster by doubling the number of nodes, with the new nodes running the new image.
So starting with our original cluster of two nodes:
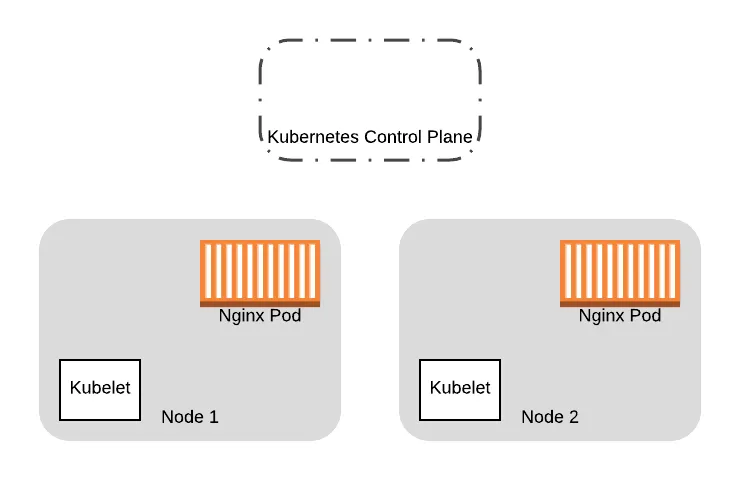
We provision two additional nodes here running the new VM images. We will eventually replace all the Pods on the old nodes on to the new ones:
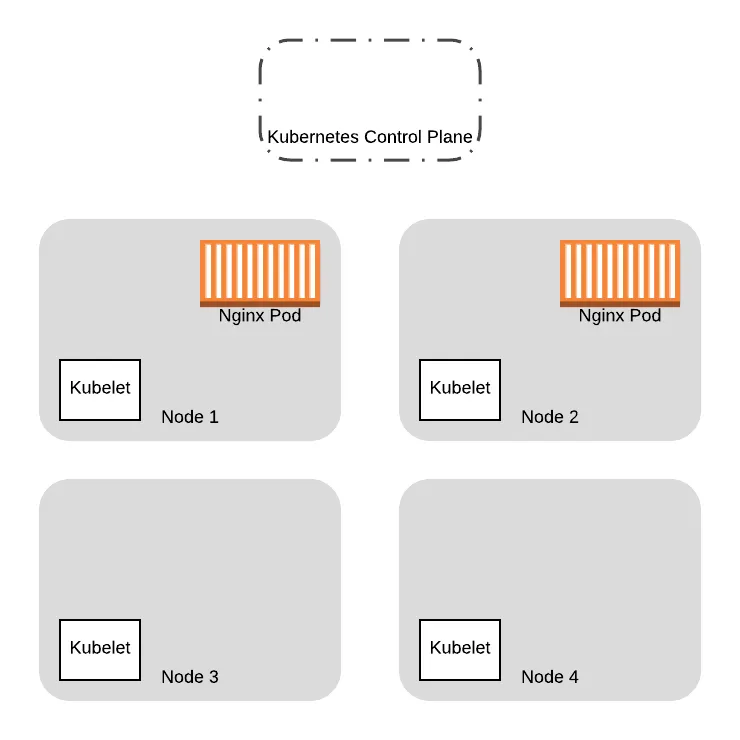
To replace the Pods, we will first need to drain the old nodes. In this example, let’s see what happens when we concurrently issue the drain command to both nodes that were running our Nginx pods. The drain request will be issued in two threads (in practice, this is just two terminal tabs), each managing the drain sequence for one of the nodes.
Note that up to this point we were simplifying the examples by assuming that the drain command immediately issues an eviction request. In reality, the drain operation involves tainting nodes (with the NoSchedule taint) first so that new pods won’t be scheduled on the nodes. For this example, we will look at the two phases individually.
So to start, the two threads managing the drain sequence will taint the nodes so that new pods won’t be scheduled:
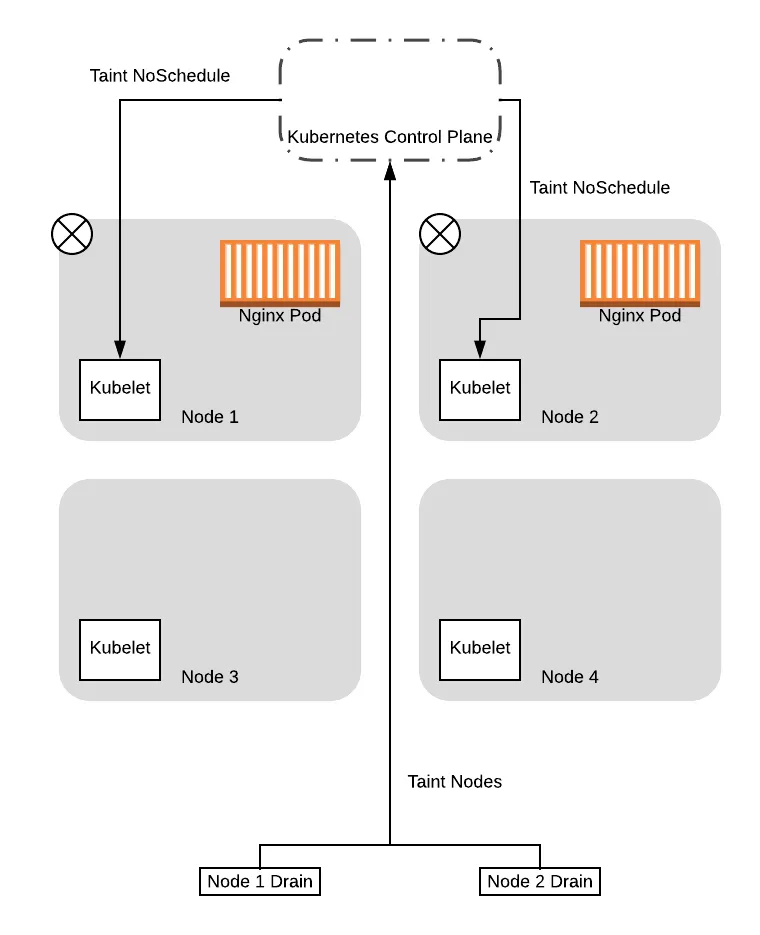
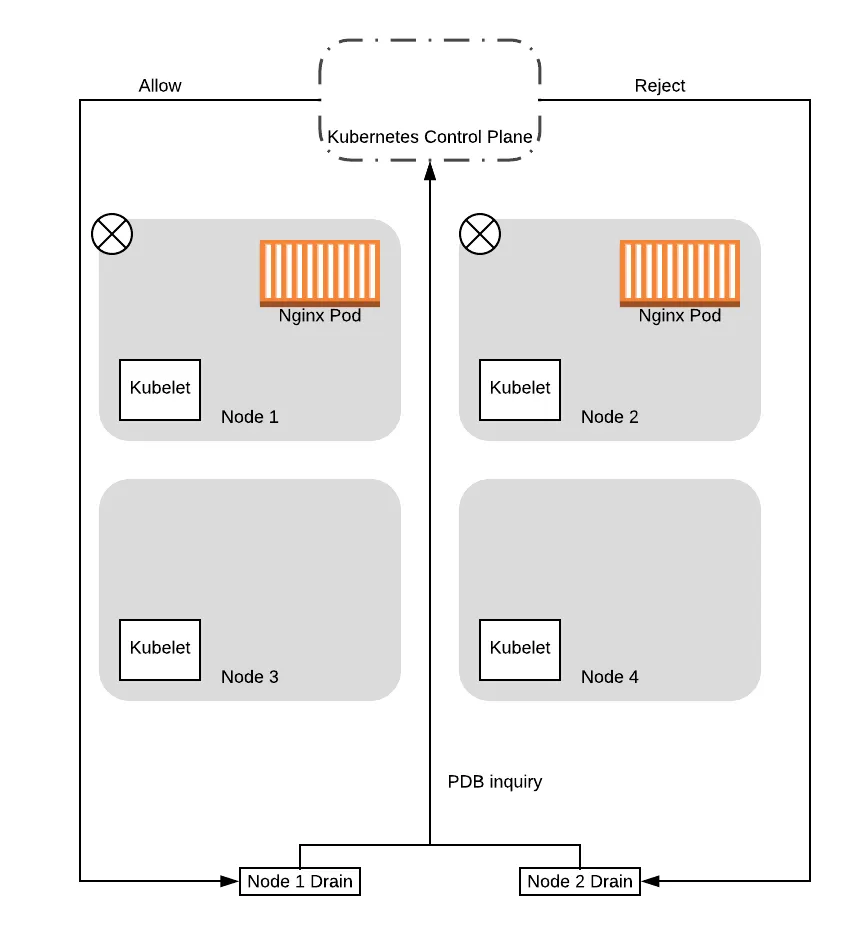
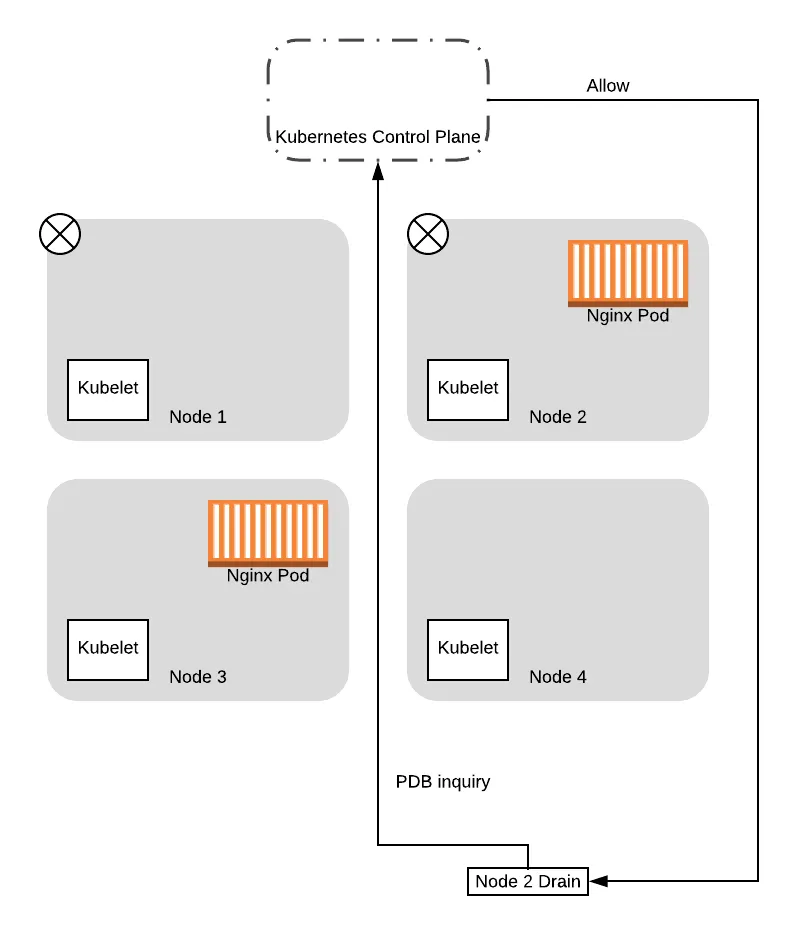
After the tainting completes, the drain threads will start evicting the pods on the nodes. As part of this, the drain thread will query the control plane to see if the eviction will cause the service to drop below the configured Pod Disruption Budget (PDB).
Note that the control plane will serialize the requests, processing one PDB inquiry at a time. As such, in this case, the control plane will respond to one of the requests with a success, while failing the other. This is because the first request is based on 2 pods being available. Allowing this request would drop the number of pods available to 1, which means the budget is maintained. When it allows the request to proceed, one of the pods is then evicted, thereby becoming unavailable. At that point, when the second request is processed, the control plane will reject it because allowing that request would drop the number of available pods down to 0, dropping below our configured budget.
Given that, in this example we will assume that node 1 was the one that got the successful response. In this case, the drain thread for node 1 will proceed to evict the pods, while the drain thread for node 2 will wait and try again later:
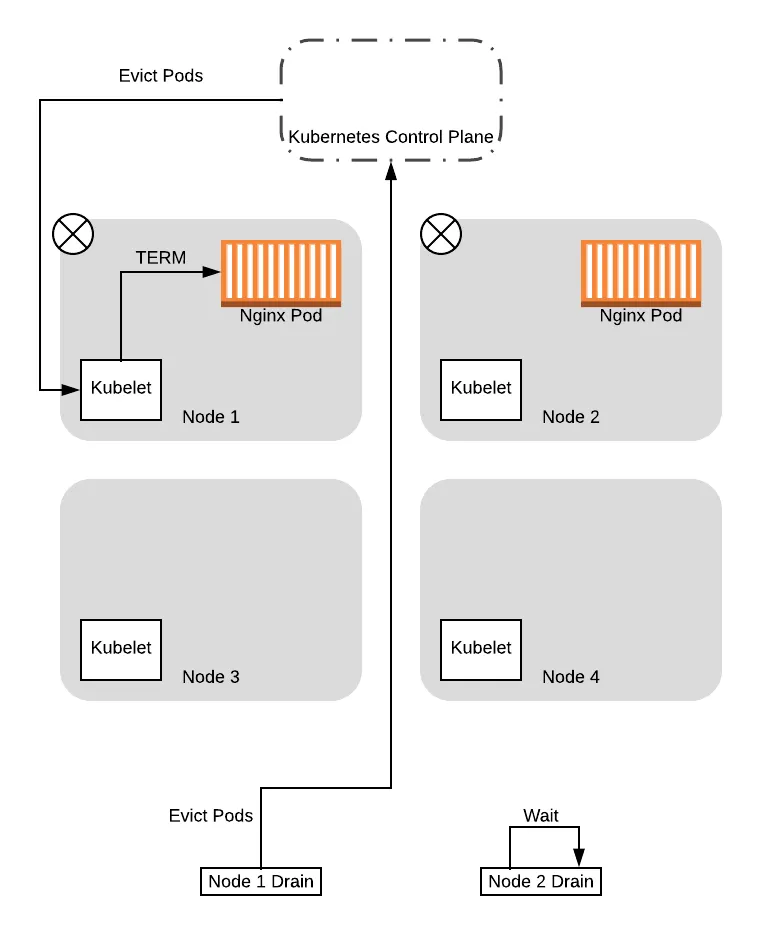
When the pod in node 1 is evicted, it is immediately recreated in one of the available nodes by the Deployment controller. In this case, since our old nodes are tainted with the NoSchedule taint, the scheduler will choose one of the new nodes:
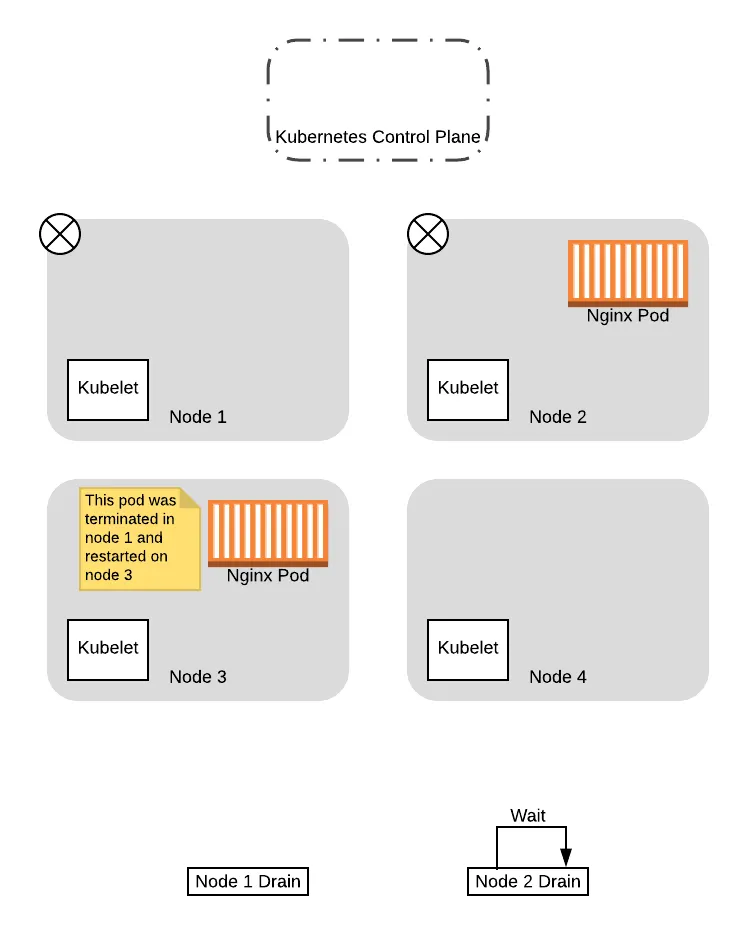
At this point, now that the pod has been replaced successfully on the new node and the original node is drained, the thread for draining node 1 completes.
From this point on, when the drain thread for node 2 tries again to query the control plane about the PDB again, it will succeed. This is because there is a pod running that is not in consideration for eviction, so allowing the drain thread for node 2 to progress further won’t drop the number of available pods down below the budget. So the thread progresses to evict the pods and eventually completes the eviction process:
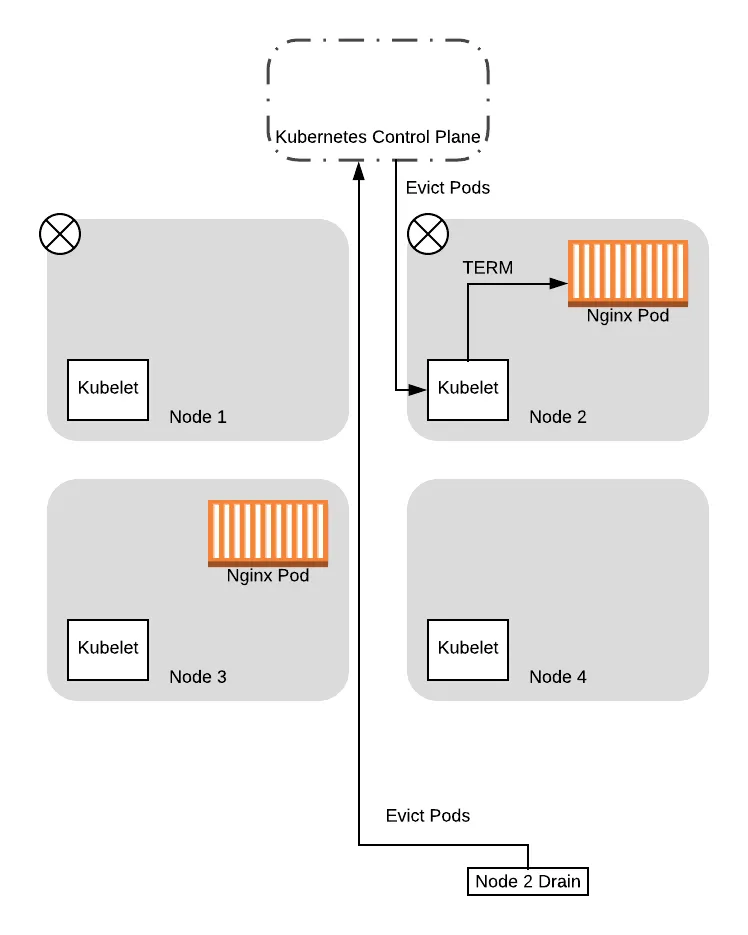
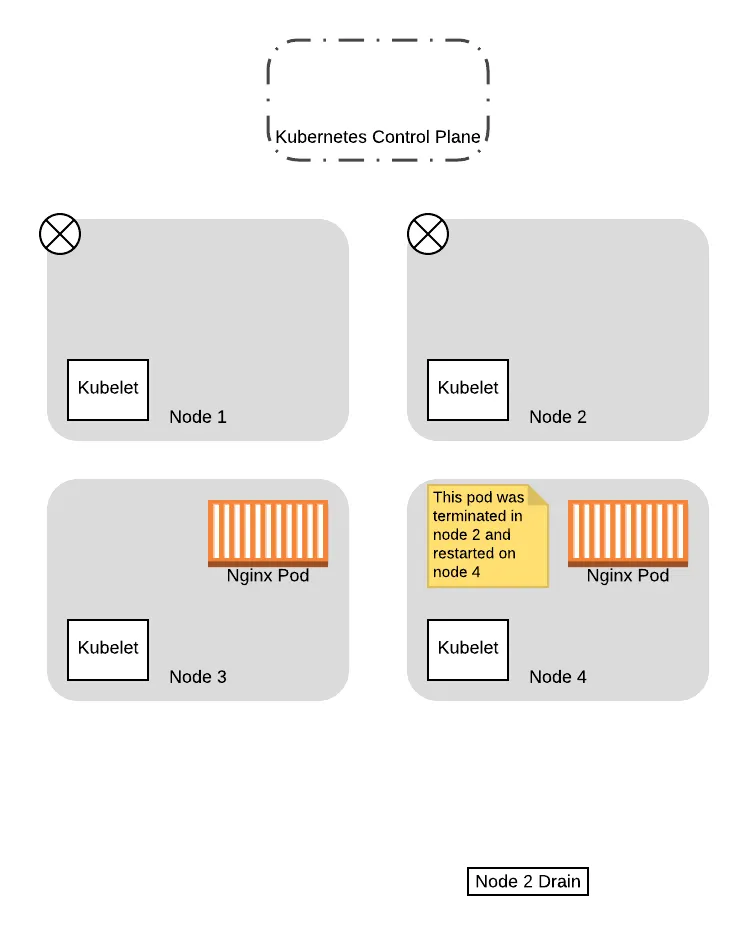
With that, we have successfully migrated both pods to the new nodes, without ever having a situation where we have no pods to service the application. Moreover, we did not need to have any coordination logic between the two threads, as Kubernetes handled all that for us based on the config we provided!
Summary
So to tie all that together, in this blog post series we covered:
- How to use lifecycle hooks to implement the ability to gracefully shutdown our applications so that they are not abruptly terminated.
- How pods are removed from the system and why it is necessary to introduce delays in the shutdown sequence.
- How to specify pod disruption budgets to ensure that we always have a certain number of pods available to continuously service a functioning application in the face of disruption.
When these features are all used together, we are able to achieve our goal of a zero downtime rollout of instance updates!
But don’t just take my word for it! Go ahead and take this configuration out for a spin. You can even write automated tests using terratest, by leveraging the functions in the k8s module, and the ability to continuously check an endpoint. After all, one of the important lessons we learned from writing 300k lines of infrastructure code is that infrastructure code without automated tests is broken.
To get a fully implemented version of zero downtime Kubernetes cluster updates on AWS and more, check out Gruntwork.io.



- No-nonsense DevOps insights
- Expert guidance
- Latest trends on IaC, automation, and DevOps
- Real-world best practices



