
This is part 3 of our journey to implementing a zero downtime update of our Kubernetes cluster. In part 2 of the series, we mitigated downtime from an unclean shutdown by leveraging lifecycle hooks to implement a graceful termination of our application pods. However, we also learned that the Pod potentially continues to receive traffic after the shutdown sequence is initiated. This means that the end clients may get error messages because they are routed to a pod that is no longer able to service traffic. Ideally, we would like the pods to stop receiving traffic immediately after they have been evicted. To mitigate this, we must first understand why this is happening.
A lot of the information in this post was learned from the book “Kubernetes in Action” by Marko Lukša. You can find an excerpt of the relevant section here. In addition to the material covered here, the book provides an excellent overview of best practices for running applications on Kubernetes and we highly recommend reading it.
Pod Shutdown Sequence
In the previous post, we covered the Pod eviction lifecycle. If you recall from the post, the first step in the eviction sequence is for the pod to be deleted, which starts a chain of events that ultimately results in the pod being removed from the system. However, what we didn’t talk about is how the pod gets deregistered from the Service so that it stops receiving traffic.
So what causes the pod to be removed from the Service ? To understand this, we need to drop one layer deeper into understanding what happens when a pod is removed from the cluster.
When a pod is removed from the cluster via the API, all that is happening is that the pod is marked for deletion in the metadata server. This sends a pod deletion notification to all relevant subsystems that then handle it:
- The
kubeletrunning the pod starts the shutdown sequence described in the previous post. - The
kube-proxydaemon running on all the nodes will remove the pod’s ip address fromiptables. - The endpoints controller will remove the pod from the list of valid endponts, in turn removing the pod from the
Service.
You don’t need to know the details of each system. The important point here is that there are multiple systems involved, potentially running on different nodes, with the sequences happening in parallel. Because of this, it is very likely that the pod runs the preStop hook and receives the TERM signal well before the pod is removed from all active lists. This is why the pod continues to receive traffic even after the shutdown sequence is initiated.
Mitigating the Problem
On the surface it may seem that what we want to do here is chain the sequence of events so that the pod isn’t shutdown until after it has been deregistered from all the relevant subsystems. However, this is hard to do in practice due to the distributed nature of the Kuberenetes system. What happens if one of the nodes experiences a network partition? Do you indefinitely wait for the propagation? What if that node comes back online? What if you have 1000s of nodes you have to wait for? 10s of thousands?
Unfortunately there isn’t a perfect solution here to prevent all outages. What we can do however, is to introduce a sufficient delay in the shutdown sequence to capture 99% of the cases. To do this, we introduce a sleep in the preStop hook that delays the shutdown sequence. Let’s look at how this works in our example.
We will need to update our config to introduce the delay as part of the preStop hook. In “Kubernetes in Action”, Lukša recommends 5–10 seconds, so here we will use 5 seconds:
lifecycle:
preStop:
exec:
command: [
"sh", "-c",
# Introduce a delay to the shutdown sequence to wait for the
# pod eviction event to propagate. Then, gracefully shutdown
# nginx.
"sleep 5 && /usr/sbin/nginx -s quit",
]
Now let’s walk through what happens during the shutdown sequence in our example. Like in the previous post, we will start with kubectl drain , which will evict the pods on the nodes. This will send a delete pod event that notifies the kubelet and the Endpoint Controller (which manages the Service endpoints) simultaneously. Here, we assume the preStop hook starts before the controller removes the pod.
At this point the preStop hook starts, which will delay the shutdown sequence by 5 seconds. During this time, the Endpoint Controller will remove the pod:
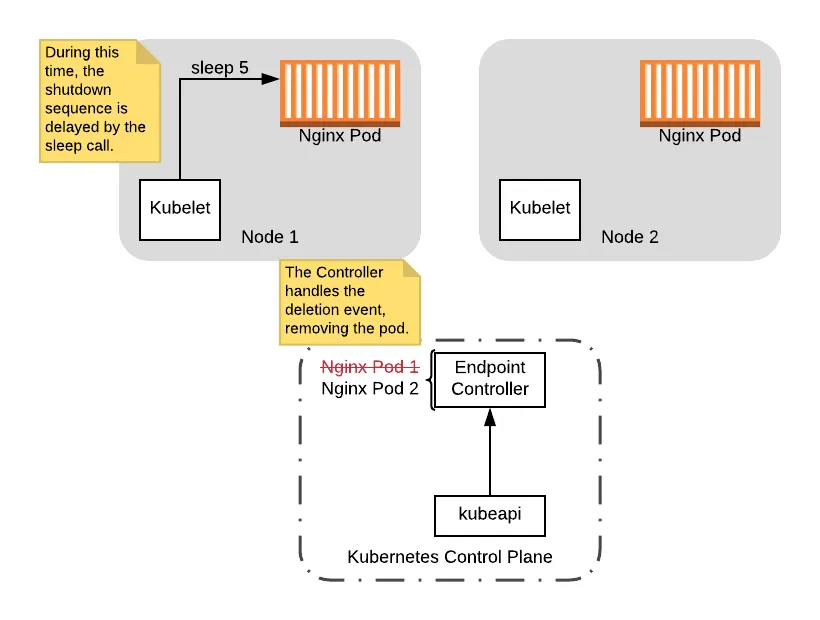
Note that during this delay, the pod is still up so even if it receives connections, the pod is still able to handle the connections. Additionally, if any clients try to connect after the pod is removed from the controller, they will not be routed to the pod being shutdown. So in this scenario, assuming the Controller handles the event during the delay period, there will be no downtime.
Finally, to complete the picture, the preStop hook comes out of the sleep and shuts down the Nginx pod, removing the pod from the node:
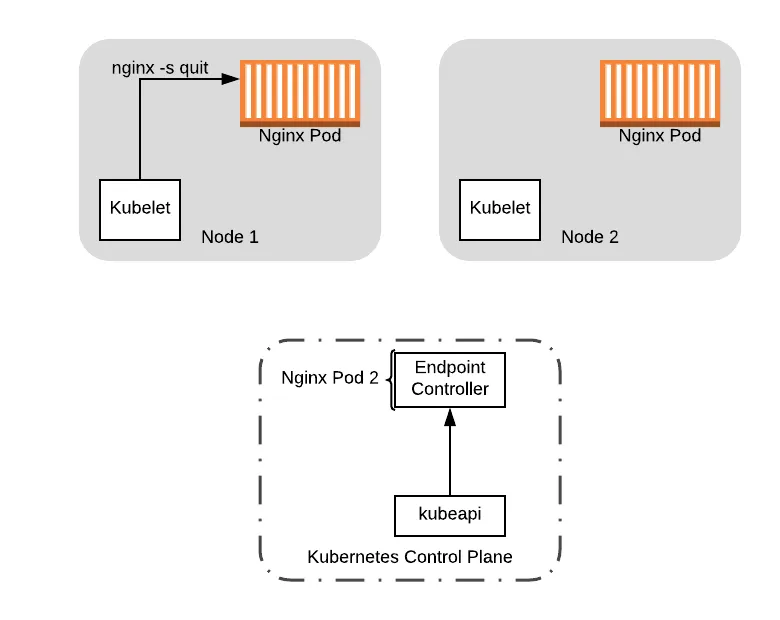
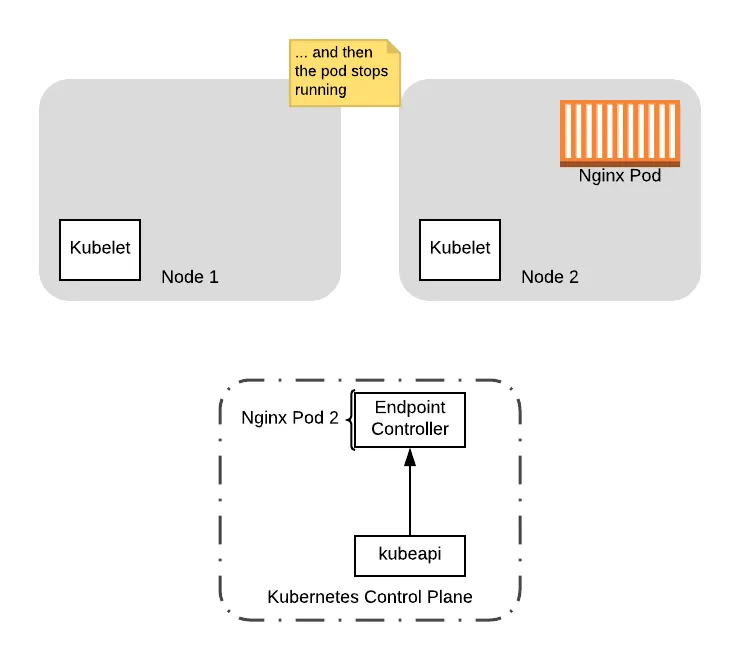
At this point, it is safe to do any upgrades on Node 1, including rebooting the node to load a new kernel version. We can also shutdown the node if we had launched a new node to house the workload that was already running on it (see the next section on PodDisruptionBudgets).
Recreating Pods
If you made it this far, you might be wondering how we recreate the Pods that were originally scheduled on the node. Now we know how to gracefully shutdown the Pods, but what if it is critical to get back to the original number of Pods running? This is where the Deployment resource comes into play.
The Deployment resource is called a controller, and it does the work of maintaining a specified desired state on the cluster. If you recall our resource config, we do not directly create Pods in the config. Instead, we use Deployment resources to automatically manage our Pods for us by providing it a template for how to create the Pods. This is what the template section is in our config:
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15
ports:
- containerPort: 80
This specifies that Pods in our Deployment should be created with the label app: nginx and one container running the nginx:1.15 image, exposing port 80 .
In addition to the Pod template, we also provide a spec to the Deployment resource specifying the number of replicas it should maintain:
spec:
replicas: 2
This notifies the controller that it should try to maintain 2 Pods running on the cluster. Anytime the number of running Pods drops, the controller will automatically create a new one to replace it. So in our case, the when we evict the Pod from the node during a drain operation, the Deployment controller automatically recreates it on one of the other available nodes.
Summary
In sum, with adequate delays in the preStop hooks and graceful termination, we can now shutdown our pods gracefully on a single node. And with Deployment resources, we can automatically recreate the shut down Pods. But what if we want to replace all the nodes in the cluster at once?
If we naively drain all the nodes, we could end up with downtime because the service load balancer may end up with no pods available. Worse, for a stateful system, we may wipe out our quorum, causing extended downtime as the new pods come up and have to go through leader election waiting for a quorum of nodes to come back up.
If we instead try to drain nodes one at a time, we could end up with new Pods being launched on the remaining old nodes. This risks a situation where we might end up with all our Pod replicas running on one of the old nodes, so that when we get to drain that one, we still lose all our Pod replicas.
To handle this situation, Kubernetes offers a feature called PodDisruptionBudgets, which indicate tolerance for the number of pods that can be shutdown at any given point in time. In the next and final part of our series, we will cover how we can use this to control the number of drain events that can happen concurrently despite our naive approach to issue a drain call for all nodes in parallel.
To get a fully implemented version of zero downtime Kubernetes cluster updates on AWS and more, check out Gruntwork.io.



- No-nonsense DevOps insights
- Expert guidance
- Latest trends on IaC, automation, and DevOps
- Real-world best practices



