
This is part 2 of our journey to implementing a zero downtime update of our Kubernetes cluster. In part 1 of the series, we laid out the problem and the challenges of naively draining our nodes in the cluster. In this post, we will cover how to tackle one of those problems: gracefully shutting down the Pods.
Pod Eviction Lifecycle
By default, kubectl drain will evict pods in a way to honor the pod lifecycle.
What this means in practice is that it will respect the following flow:
-
drainwill issue a request to delete the pods on the target node to the control plane. This will subsequently notify thekubeleton the target node to start shutting down the pods. -
The
kubeleton the node will invoke thepreStophook in the pod. -
Once the
preStophook completes, thekubeleton the node will issue theTERMsignal to the running application in the containers of the pod. -
The
kubeleton the node will wait for up to the grace period (specified on the pod, or passed in from the command line; defaults to 30 seconds) for the containers to shut down, before forcibly killing the process (withSIGKILL). Note that this grace period includes the time to execute thepreStophook.
Based on this flow, you can leverage preStop hooks and signal handling in your
application pods to gracefully shutdown your application so that it can "clean up" before it is
ultimately terminated. For example, if you have a worker process streaming tasks from a queue, you
can have your application trap the TERM signal to indicate that the application
should stop accepting new work, and stop running after all current work has finished. Or, if you
are running an application which can't be modified to trap the TERM signal (a
third party app for example), then you can use the preStop hook to implement
the custom API that the service provides for graceful shut down of the application.
In our example, Nginx does not gracefully handle the TERM signal by default,
causing existing requests being serviced to fail. Therefore, we will instead rely on a
preStop hook to gracefully stop Nginx. We will modify our resource to add a
lifecycle clause to the container spec. The lifecycle clause
looks like this:
With this config, the shutdown sequence will issue the command
/usr/sbin/nginx -s quit before sending SIGTERM to the Nginx
process in the container. Note that since the command will gracefully stop the Nginx process and
the pod, the TERM signal essentially becomes a noop.
This should be nested under the Nginx container spec. When we include this, the full config for
the Deployment looks as follows:
Continuous Traffic After Shutdown
The graceful shutdown of the Pod ensures Nginx is stopped in a way to service the existing traffic before shutting down. However, you may observe that despite best intentions, the Nginx container continues to receive traffic after shutting down, causing downtime in your service.
To see how this can be problematic, let’s walk through an example with our sample deployment. For the sake of this example, we will assume that the node had received traffic from a client. This will spawn a worker thread in the application to service the request. We will indicate this thread with the circle on the pod container.
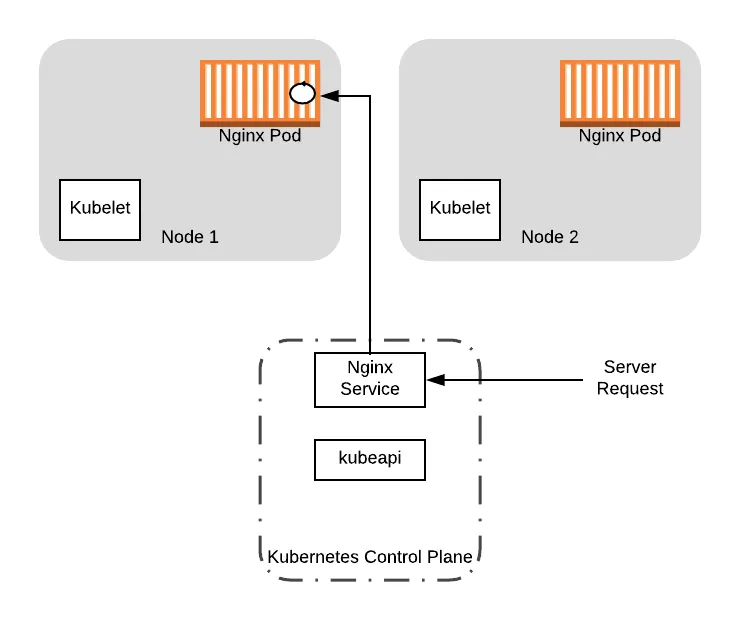
Suppose that at this point, a cluster operator decides to perform maintenance on Node 1. As part
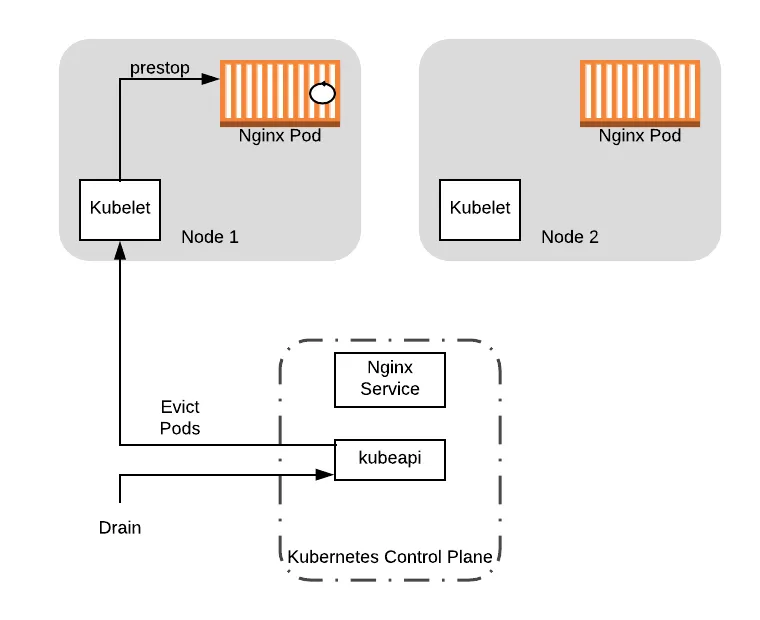
of this, the operator runs the command kubectl drain node-1 , causing the
kubelet process on the node to execute the preStop hook,
starting a graceful shutdown of the Nginx process:
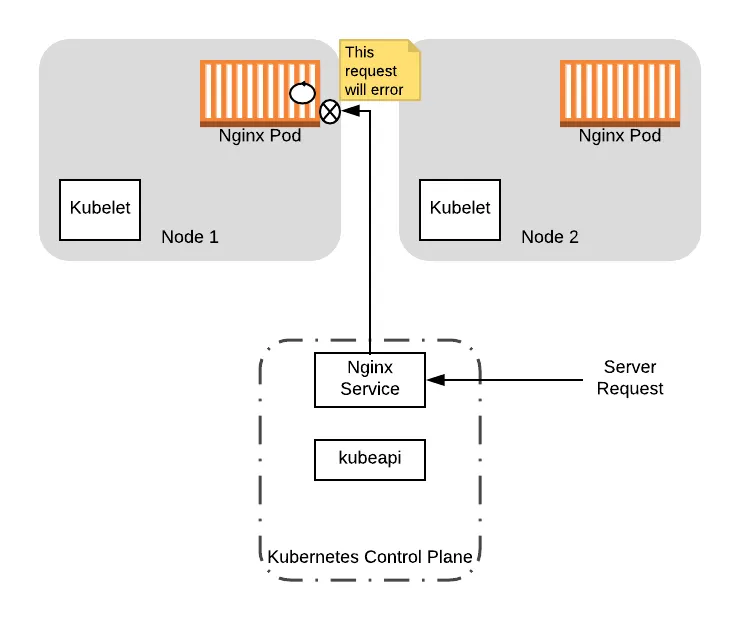
Because nginx is still servicing the original request, it does not immediately terminate. However, when nginx starts a graceful shutdown, it errors and rejects additional traffic that comes to it.
At this point, suppose a new server request comes into our service. Since the pod is still registered with the service, the pod can still receive the traffic. If it does, this will return an error because the nginx server is shutting down:
To complete the sequence, eventually nginx will finish processing the original request, which will terminate the pod and the node will finish draining:
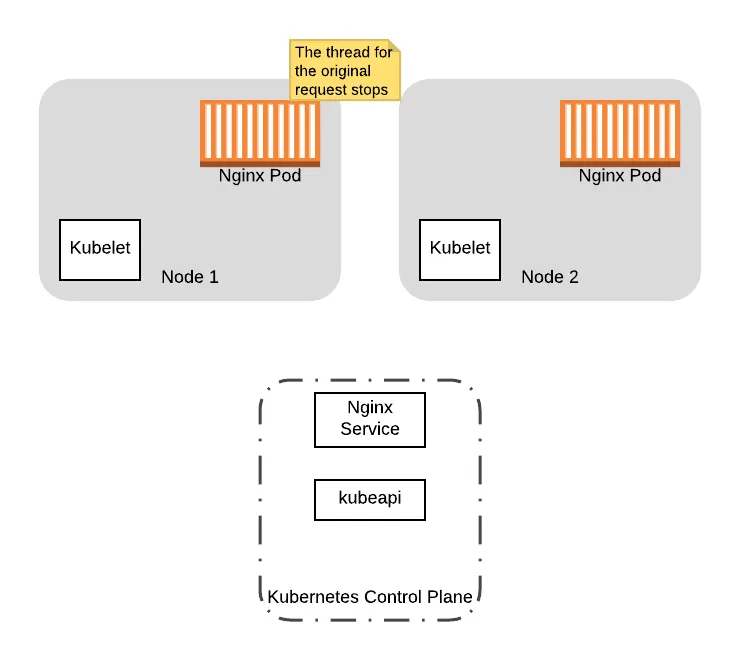
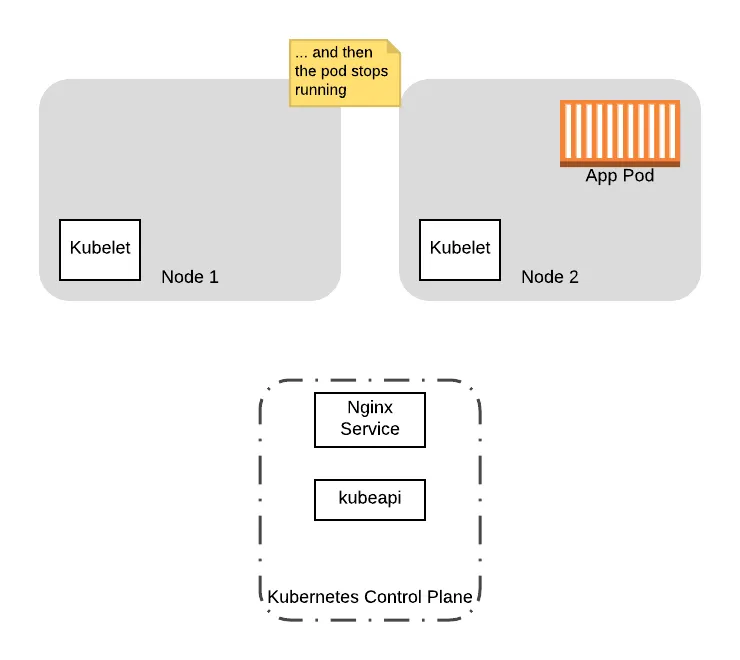
In this example, when the application pod receives the traffic after the shutdown sequence is initiate, the first client will receive a response from the server. However, the second client receives an error, which will be perceived downtime.
So why does this happen? And how do you mitigate potential downtime for clients that end up
connecting to the server during a shutdown sequence? In
the next part of our series, we will cover the pod eviction lifecylce in more details and describe how you can introduce a
delay in the preStop hook to mitigate the effects of continuous traffic from
the Service .
To get a fully implemented version of zero downtime Kubernetes cluster updates on AWS and more, check out Gruntwork.io.



- No-nonsense DevOps insights
- Expert guidance
- Latest trends on IaC, automation, and DevOps
- Real-world best practices



