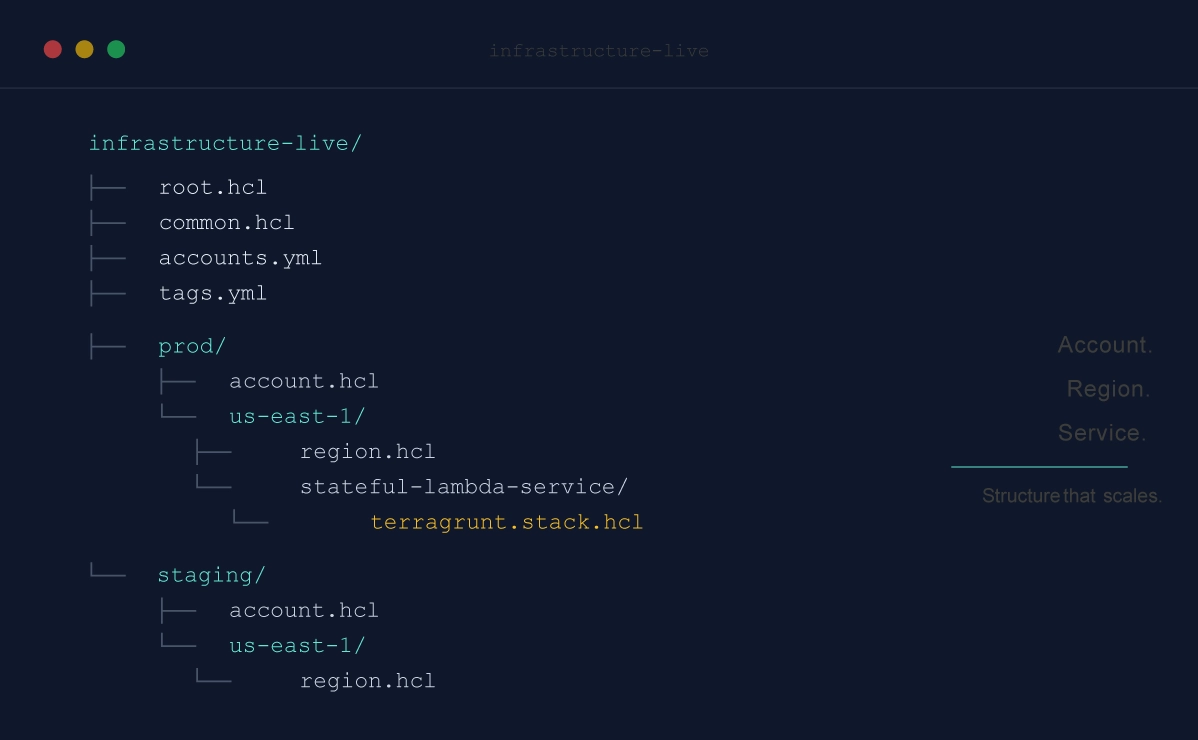
AI advances are making engineers way more productive, and leadership wants more AI adoption across the board. That includes infrastructure: writing Terraform, updating modules, deploying changes, fixing drift.
All of it.
But at the same time, nothing has changed about accountability. When production goes down, the DevOps engineer is still on the hook.
We’re starting to see that tension show up in public. Alexey Grigorev’s recent post about AI dropping his production database is one of the clearest examples.
So, what actually happened?
You might see his article’s subtitle (“A Terraform command executed by an AI agent wiped the production infrastructure behind the DataTalks.Club course platform”) and think: “Oh, this guy didn’t have guardrails set and he let an AI go too far.”
That’s not exactly what happened.
Alexey migrated to a new machine. His Terraform state lived on the old one. (See where this is going?)
He used an AI coding agent to help deploy changes. The agent ran `terraform plan`. Terraform was operating against the wrong state, which made real infrastructure look disposable. At first, Terraform behaved as if infrastructure needed to be created from scratch. But the real failure came later.
While trying to clean up duplicate resources, the AI agent unpacked and used an older Terraform archive, replacing the active state with one that contained the real production infrastructure. Alexey then allowed the agent to run `terraform destroy`, believing it was removing only temporary duplicates. Instead, it destroyed the actual production environment behind the DataTalks.Club course platform.
The deleted infrastructure included the database, VPC, ECS cluster, load balancers, and bastion host. The RDS deletion also removed automated backups because the delete request allowed that behavior.
Recovery took roughly 24 hours and required upgrading AWS support so the issue could be escalated. AWS ultimately found a snapshot that was not visible in the console and restored it.
This isn’t an isolated story
There’s a broader pattern here. Terraform works well when one person is running it from their laptop. The moment multiple people, environments, and systems are involved, the stakes change.
State becomes shared, access needs to be controlled, and changes need visibility. AI is pushing this transition faster.
Teams are no longer writing HCL by hand. AI can generate infrastructure definitions in seconds. It can suggest changes that look reasonable. It can walk through workflows step by step.
Yes, using AI to write HCL lowers the barrier to entry and makes life easier. However, it does not reduce the risk. In some cases (like this one), it increases the risk because more changes are happening, and at a faster rate.
The all-too-common reasons why Alexey’s workflow broke down
Alexey’s post maps to a common set of Terraform practices.
- Local state: State lived on one machine, which made the workflow fragile from the start. After Alexey switched machines, state handling became confused, and later a newer Terraform setup overwrote the active state. That is what turned a messy cleanup into a production deletion.
- State integrity: The problem was not just where Terraform state lived. It was also that the state could be replaced or misapplied during an ad hoc workflow. Once the wrong state was in play, Terraform treated real production resources as fair game.
- Direct CLI execution: Commands were run from a terminal. `plan` and `apply` happened in the same context. If something looked wrong, the only safeguard was the person running the command.
- Unrestricted credentials: The process had full access to production resources. There was no separation between planning and execution. Any command could modify or delete infrastructure.
- No review path: There was no enforced checkpoint between planning, cleanup, and destructive execution. Once the agent was allowed to act directly in a live environment, there was no workflow-level control to stop a bad assumption from becoming a production incident.
- No resource protections: The database had no deletion protection. Backups were tied to the lifecycle of the instance. When the instance was deleted, so were the backups.
None of this is unusual. Many Terraform setups begin this way because it works great for small teams and setups.
- Local state during early development
- Direct CLI usage for speed
- Shared credentials across environments
- Informal review processes
- Production safeguards added later
Unfortunately, it grows fragile as systems grow. AI accelerates that growth, performing more changes, more often, with less friction.
Where AI actually fits and where it doesn’t
We love that AI is changing how infrastructure teams operate and mature. You can generate working Terraform without needing to do a deep-dive on it. AI will give you valid output and you can move forward with your work.
The flipside: it can erase or bork your systems. With great power comes great responsibility, right?
One of the biggest differences between AI-assisted infrastructure work and AI-assisted application development is state. Infrastructure tools operate against long-lived systems, shared environments, and resources that already exist.
The world has already decided to use AI as often as possible. We just need to balance speed with stronger controls. When infrastructure state is wrong, stale, or easy to overwrite, AI can turn a small misunderstanding into a destructive change very quickly.
Risks aside, AI is incredibly useful in Terraform workflows. It can generate modules, suggest changes, debug issues, and speed up repetitive tasks. All of that is valuable. But risk shows up when execution is unconstrained.
If an AI agent can run apply or destroy directly, then every weakness in the workflow becomes more dangerous. The solution is not to remove AI. Rather, it’s to change where and how execution happens.
A better model for Terraform execution
The pattern that saves you from the kinds of issues Alexey faced are well-known and understood.
- State is remote and shared
State lives in versioned entities like an S3 buckets with locking. Every environment points to the same source of truth. - Plans run in CI
Changes trigger terraform plan in a controlled environment. Output is captured and visible. - Changes are reviewed in pull requests
Plan output is attached to a PR. Teammates can see what will change before anything runs. - Applies happen after merge
Infrastructure changes execute in pipelines, not from a local terminal. - Credentials are scoped
Planning uses read-only access. Apply uses write access. Access is ephemeral. - Destructive actions are explicit
Destroying infrastructure requires a code change that is reviewed. - Critical resources are protected
Databases and core systems have deletion protection and independent backups.
This is the model Gruntwork Pipelines is designed to enforce alongside Terragrunt-based infrastructure workflows and a battle tested, production grade, Gruntwork Infrastructure as Code Library. Plans run on pull requests. Applies run after merge. Execution happens in CI rather than from an engineer’s laptop. Credentials are short-lived, and all changes are surfaced before they are applied.
AI can still participate in this workflow. It just doesn’t control execution.
Mapping the incident to what exists today
Alexey implemented several fixes after the incident:
- Remote state in S3
- Deletion protection on RDS
- More careful review of changes
- Changes to how AI is used
These are solid, well-known patterns. (Good job, Alexey!) A more structured Terragrunt plus CI/CD workflow would have reduced this risk substantially. For example:
- Remote state can be defined once and reused everywhere
- Pipelines enforce plan and apply separation
- Credentials are segmented by environment and phase
- Drift detection surfaces mismatches
- RDS modules create a final snapshot on deletion
- Backup Vault and Backup Plan support independent recovery
- `prevent_destroy` blocks accidental deletes
These controls exist so teams do not have to discover them during an incident.
Don’t dismiss AI in your HCL — use it safely
Alexey’s post is valuable because it shows that this was not a story about AI suddenly going rogue. It was a story about brittle state handling, ad hoc execution, broad permissions, and no workflow boundary between suggestion and production change. AI was part of the chain. The operating model is what determined the blast radius.
If you’re using Terraform today, it’s worth checking a few things:
- Where your state lives
- Who can run `apply` or `destroy`
- What happens between plan and execution
- How visible destructive changes are
- What protections exist for critical resources
- Whether your backups actually work
If those answers depend on individual discipline, the system is fragile. If those answers are enforced by the workflow, the system is resilient. AI will continue to be part of infrastructure work.
The teams that benefit from it are the ones that control execution, require visibility, and treat production changes with the weight they deserve.



- No-nonsense DevOps insights
- Expert guidance
- Latest trends on IaC, automation, and DevOps
- Real-world best practices