Part 5. How to Set Up Continuous Integration (CI) and Continuous Delivery (CD)
Update, June 25, 2024: This blog post series is now also available as a book called Fundamentals of DevOps and Software Delivery: A hands-on guide to deploying and managing software in production, published by O’Reilly Media!
This is Part 5 of the Fundamentals of DevOps and Software Delivery series. In Part 4, you learned several tools that help developers work together, including version control, build systems, and automated tests. But merely having a collection of tools is not enough. You also need to know how to put them together into an effective software delivery lifecycle (SDLC). Every company has its own SDLC, some of which work better than others.
For example, at LinkedIn, before Project Inversion (which you read about in the Preface), our SDLC was based on a release train model, where every two weeks, a "train" would leave the station with new code destined for production. At the time, teams did their work in isolated feature branches, and to get on the train, you needed to get your code into a release branch. Several weeks before a scheduled release, we would do integration, where we’d merge feature branches into a release branch, followed by deployment, where we’d roll out the release branch to production.
The integration process frequently ran into problems. As dozens of feature branches came crashing together, developers would find that they had been coding for months on top of incorrect assumptions. The API you were using in a dozen places had been removed; the module you had updated had been refactored in an incompatible way; the new feature you added no longer looked right because of a design change. Resolving these conflicts could take weeks.
The deployment process was also problematic. For each release, we would assemble a deployment plan, which was a wiki page that listed all the services to deploy, what order to deploy them, and what configuration they needed. The release team would go through the wiki, and deploy dozens of services and configuration changes, either by hand or with fragile scripts. As a result, deployments ran late into the night, and frequently caused bugs and outages.
Nowadays, after Project Inversion, any team at LinkedIn can deploy at any time, or even thousands of times per day. Two of the key practices that made this possible at LinkedIn, as well as the other companies you read about in The Impact Of World-Class Software Delivery, were the following:
Continuous integration (CI)
Continuous delivery (CD)
These two practices are the focus of this blog post. The following sections will dive into each of these practices, and along the way, you’ll work through examples that use GitHub Actions for CI and CD, including running Node.js and OpenTofu tests after every commit, using OIDC to automatically authenticate to AWS, and running tofu plan and tofu apply on pull requests to automatically deploy changes. Let’s get started by diving into CI.
Continuous Integration (CI)
Imagine you’re responsible for building the International Space Station (ISS), which consists of dozens of components, as shown in Figure 30.
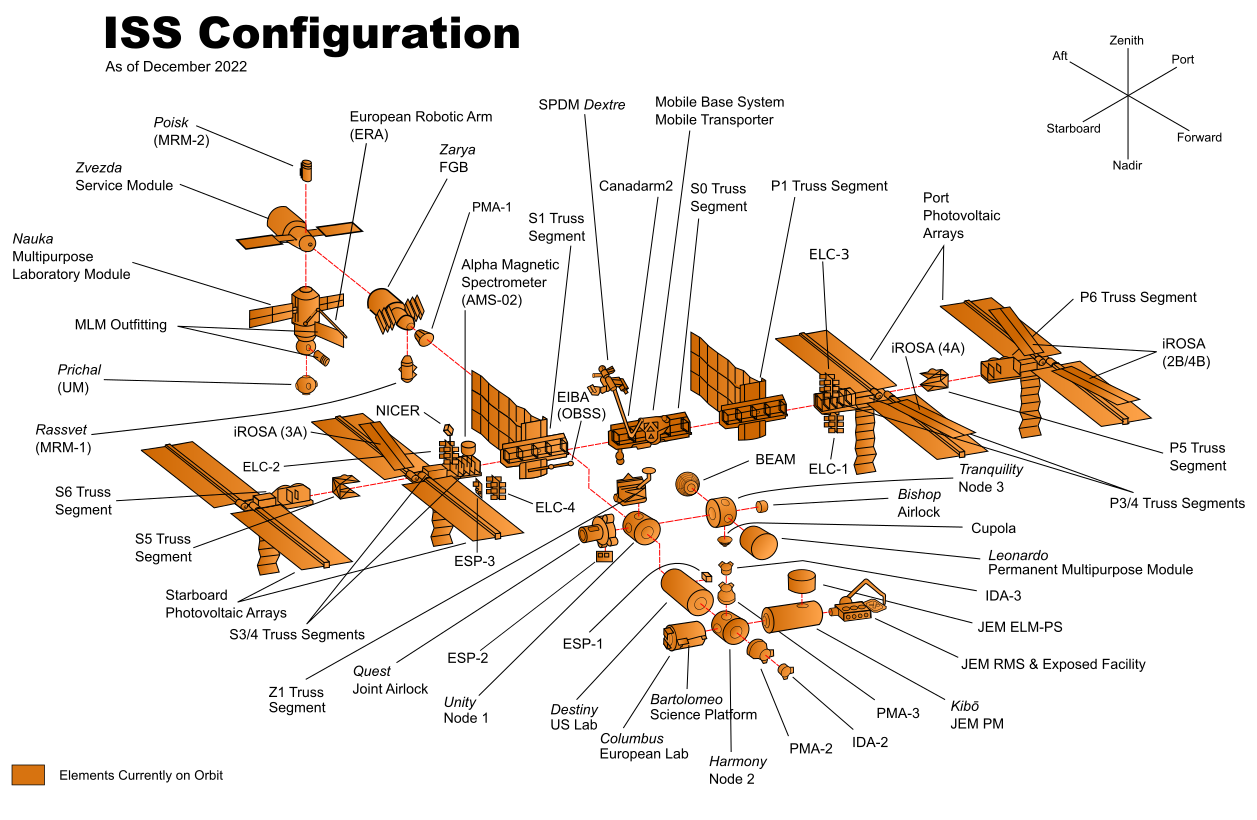
Each component will be assigned to a team from a different country, and it’s up to you to decide how to organize these teams. You have two options:
- Option 1
Come up with a design for all the components up front, and then have each team go off and work on their component in complete isolation until it’s finished. When all the teams are done, launch all the components into outer space, and try to put them together at the same time.
- Option 2
Come up with an initial design for all the components, and then have each team go off and start working. As they make progress, the teams regularly test each component with all the other components, and update the design if there are any problems. As components are completed, you launch them one at a time into outer space, and assemble them incrementally.
How do you think option #1 is going to work out? In all likelihood, attempting to assemble the entire ISS at the last minute will expose a number of problems. Team A thought team B would handle the wiring while team B thought team A would do it; all the teams used the metric system, except one; no one remembered to install a toilet. With everything built and floating in outer space, going back to fix things is going to be difficult.
Option 1 may sound ridiculous, but this is exactly the way in which many companies build software. As you saw with the LinkedIn example in the intro to this blog post, there are companies where developers work in isolated feature branches for weeks or months at a time and then, when a release rolls around, they try to merge all the feature branches together. This process is known as late integration, and it often leads to a painful integration process, where you spend weeks fighting with merge conflicts.
The ISS was actually built using a process that more closely resembled option #2[22], and in most cases, you should use this option as well. In the world of software, option #2 is referred to as continuous integration (CI), and the idea is to ensure that every developer on your team merges their work together on a regular basis, typically daily or multiple times per day. The key benefit of CI is that it exposes problems with your work earlier in the process, before you’ve gone too far in the wrong direction, and allows you to make improvements incrementally.
Key takeaway #1 Ensure all developers merge all their work together on a regular basis, typically daily or multiple times per day. |
The most common way to implement continuous integration is to use a trunk-based development model, where developers do all of their work on the same branch, typically main or master or trunk (depending on your VCS). I’ll refer to this branch as main in this blog post series. With trunk-based development, you no longer have long-lived feature branches. Instead, you create short-lived branches, that typically last from a few hours to a few days, and you open pull requests to get your branch merged back into main on a regular basis.
It may seem like having all developers work on a single branch couldn’t possibly scale, but the reality is that it might be the only way to scale. LinkedIn moved off of feature branches and onto trunk-based development as part of Project Inversion, which was essential for scaling the company from roughly 100 developers to over 1,000. Facebook uses trunk-based development for thousands of developers. Google uses trunk-based development for tens of thousands of developers, and has shown it can scale to 2+ billion lines of code, 86TB of source data, and around 40,000 commits per day.
If you’ve never used trunk-based development, it can be hard to imagine how it works. The same questions come up again and again:
Wouldn’t you have merge conflicts all the time?
Wouldn’t the build always be broken?
How do you make large changes (e.g., those that take months)?
In the next three sections, I’ll address each of these questions, showing the tools and techniques companies use to deal with them, and then walk you through an example of how to set up some of these continuous integration tools and techniques yourself.
Dealing with Merge Conflicts
The first question that newbies to trunk-based development usually ask is, won’t you be dealing with merge conflicts all the time? After all, with feature branches, each time you merge, you get days or weeks of conflicts to resolve, but at least you only have to deal with that once every few weeks or months. Whereas with trunk-based development, wouldn’t you have to fight with merge conflicts many times per day?
As it turns out, the reason that feature branches lead to painful merge conflicts is precisely because those feature branches are long-lived. If your branches are short-lived, the odds of merge conflicts are much lower. For example, imagine you have a repo with 10,000 files, and two developers working on changes in different branches. After one day, each developer has changed perhaps 10 files, so if they try to merge the branches back together, the chances that some of those 20 files overlap, out of 10,000, are pretty low. But if those developers worked in those branches for three months, and changed 500 files in each branch during that time, then the chances that some of those 1,000 files overlap and conflict are much higher.
Moreover, even if there are a merge conflicts, it’s easier to deal with them if you merge regularly. If you’re merging two branches that are just a day old, the conflicts will be relatively small, as you can’t change all that much code in just one day, and relatively easy to understand, as the code will still be fresh in your mind. On the other hand, if you’re merging code that is several months old, then the conflicts will be larger, as you can make a lot of changes in that time period, and harder to understand, as they may be related to changes you made months ago.
The most important thing to understand is this: when you have multiple developers working on a single codebase at the same time, merge conflicts are unavoidable, so the question isn’t how to avoid merge conflicts, but how to make those merge conflicts as painless to deal with as possible. And that’s one of many places in software delivery where Martin Fowler’s quote applies:
If it hurts, do it more often.
Frequency Reduces Difficulty
Merge conflicts hurt. The way to make it hurt less is to merge more often.
Preventing Breakages with Self-Testing Builds
The second question that newbies to trunk-based development often ask is, won’t you be dealing with breakages all the time? After all, with feature branches, each time you merge, it can take days or weeks to fix all the issues that come up and stabilize the release branch, but at least you only have to deal with that once every few weeks or months. Whereas with trunk-based development, wouldn’t you have to fight with breakages many times per day?
This is precisely where the automated testing practices you learned about in Part 4 come to the rescue. Companies that practice CI and trunk-based development configure a self-testing build that runs automated tests after every commit. Every time a developer opens a pull request to merge a branch into main, you automatically run tests against their branch, and show the test results directly in the pull request UI (you’ll see an example of how to set this up later in this post). That way, code that doesn’t pass your test suite doesn’t get merged to main in the first place. And if somehow some code does slip through that breaks main, then as soon as you detect it, the typical solution is to revert that commit automatically. This way, you get main back into working condition quickly, and the developer who merged in the broken code can redo their commit later, once they’ve fixed whatever caused the breakage.
The most common way to set up a self-testing build is to run a CI server, which is a piece of software that integrates with your version control system to run various automations, such as your automated tests, in response to new commits, branches, and so on. There are many CI servers out there (full list): some are designed for you to run on your own servers, such as Jenkins and TeamCity; some are designed to run in your Kubernetes clusters, such as Jenkins X and Tekton; and some are designed as managed services, such as CircleCi, GitLab, and GitHub Actions (note that some of these managed services also have offerings that you can host yourself, such as GitHub Enterprise Server). Jenkins, one of the oldest CI solutions (it launched under the name Hudson in 2005), used to be the most popular option, but these days, most teams are going with GitLab or GitHub Actions.
CI servers are such an integral part of continuous integration, that for many developers, the two terms are nearly synonymous. This is because a CI server and a good suite of automated tests completely changes how you deliver software:
Without continuous integration, your software is broken until somebody proves it works, usually during a testing or integration stage. With continuous integration, your software is proven to work (assuming a sufficiently comprehensive set of automated tests) with every new change—and you know the moment it breaks and can fix it immediately.
Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation (Addison-Wesley Professional).
Going from a default of broken to a default of working is a profound transformation. Instead of a multi-day merge process to prepare your code for release, your code is always in a releasable state—which means you can deploy whenever you want. To some extent, the role of a CI server is to act as a gatekeeper, protecting your code from any changes that jeopardize your ability to deploy at any time.
Key takeaway #2 Use a self-testing build after every commit to ensure your code is always in a working and deployable state. |
In The Impact Of World-Class Software Delivery, you saw that companies with world-class software delivery processes are able to deploy thousands of times per day. Continuous integration—including a CI server and thorough automated test suite—is one of the key ingredients that makes this possible; you’ll see some of the other ingredients throughout this post.
Making Large Changes
The third question that newbies to trunk-based development often ask is, how do you handle changes that take a long time to implement? CI sounds great for small changes, but if you’re working on something that will take weeks or months—e.g., major new features or refactors—how can you merge your incomplete work on a daily basis without breaking the build or releasing unfinished features to users?
There are two approaches that you can use to resolve this: branch by abstraction and feature toggles. These two techniques are the focus of the next two sections.
Key takeaway #3 Use branch by abstraction and feature toggles to make large-scale changes while still merging your work on a regular basis. |
Branch by abstraction
Branch by abstraction is a technique that allows you to make large-scale changes to your code incrementally, across many commits, with minimal risk of breaking the build or releasing unfinished work to users. For example, let’s say you have hundreds of modules in your codebase that use Library X, as shown in Figure 31:
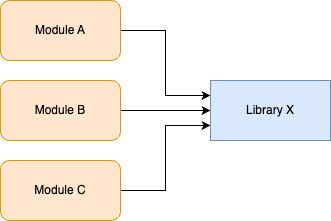
You want to replace Library X with Library Y, but this will require updating hundreds of modules, which could take months. If you do this work in a feature branch, by the time you merge it back, there’s a good chance you’ll have merge conflicts with many of the updated modules, and it’s possible new usages will have shown up in the meantime, so you’d have even more work to do.
Instead of a feature branch, the idea with branch by abstraction is to keep working on main, but to introduce a new abstraction into the codebase. What type of abstraction you use depends on your programming language: it might be an interface, a protocol, a class, etc. The important thing is that (a) the abstraction initially uses Library X under the hood, so there is no change in behavior and (b) it creates a layer of indirection between your modules and Library X, as shown in Figure 32:
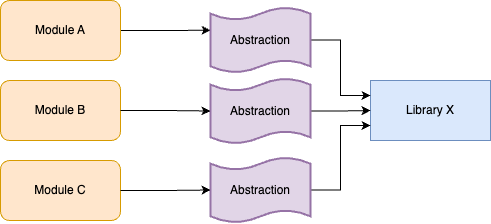
You can update your modules to use the abstraction incrementally, across many commits to main. There’s no hurry or risk of breakage, as under the hood, the abstraction is still using Library X. Eventually, all modules should be using the abstraction; you could even add a test that fails if anyone tries to use Library X directly.
At this point, you can start updating the abstraction to use Library Y instead of Library X for some use cases, as shown in Figure 33:
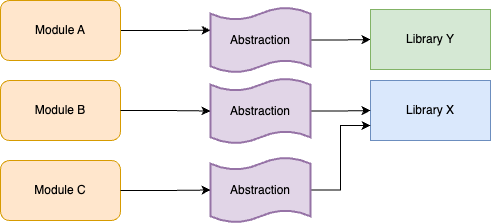
You can roll out this change incrementally, across many commits to main, integrating your work regularly to minimize merge conflicts. You could also update your abstraction code to ensure that any new usages of the abstraction get Library Y under the hood by default. Eventually, when you’re done updating all module usages, you can remove Library X entirely, as shown in Figure 34:
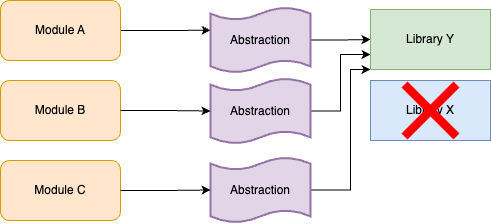
Branch by abstraction is a great technique for doing large-scale refactors. But what if you need to introduce totally new functionality? If that functionality takes weeks or months to implement, how can you merge it regularly into main without accidentally releasing unfinished features to users? This is when you turn to the second approach, feature toggles, as described next.
Feature toggles
The idea with feature toggles (AKA feature flags) is to wrap new functionality in conditionals that let you turn (toggle) those features on and off dynamically. For example, imagine that you wanted to take the Node.js sample app you’ve been using throughout this blog post series, and to update it to return a proper home page that is a little more interesting than the "Hello, World!" text. However, it’s going to take you several months to implement this new home page. Therefore, you add a conditional to your code as shown in Example 84:
app.get('/', (req, res) => {
if (lookupFeatureToggle(req, "HOME_PAGE_FLAVOR") === "v2") { (1)
res.send(newFancyHomepage()); (2)
} else {
res.send('Hello, World!'); (3)
}
});Here’s what this code does:
| 1 | Use the lookupFeatureToggle function to look up the value of the HOME_PAGE_FLAVOR feature toggle. |
| 2 | If feature toggle value is "v2," respond with the new home page. |
| 3 | If feature toggle value is anything else, respond with the original home page. |
So what does the lookupFeatureToggle function do? Typically, this function will check if the feature toggle is enabled by querying a dedicated feature toggle service, which is a service that stores the values of feature toggles (e.g., the HOME_PAGE_FLAVOR is set to v2) and provides a web UI or API that lets you quickly change the values without having to deploy new code. You can build your own feature toggle service, deploy an open source feature toggle service such as growthbook or Flagsmith], or you could use a managed feature toggle service such as Split or LaunchDarkly (full list).
It might not be obvious, but the humble if-statement, combined with a feature toggle check, unlocks a superpower: you can now commit and regularly merge code, even before it’s done. This is because of the following key property of feature toggles:
The default value for all feature toggles is off.
If you wrap new features in a feature toggle check, as long as the code is syntactically valid (which you can validate with simple automated tests), you can merge your new feature into main long before that feature is done, as by default, the new feature is off, so it will have no impact on other developers or your users. This is what allows you to develop large new features while still practicing continuous integration. What’s even more surprising is that this is only one of the superpowers you get with feature toggles; you’ll see a number of others later in this blog post.
Now that you understand the basics of continuous integration, let’s get a little practice setting up some of the technology that enables it: namely, a self-testing build.
Example: Run Automated Tests for Apps in GitHub Actions
Example Code As a reminder, you can find all the code examples in the blog post series’s sample code repo in GitHub. |
In Part 4, you added automated tests to the Node.js sample app. In this section, you’ll set up a CI server to run these tests automatically after every commit, and show the results in pull requests. Since you pushed your code to GitHub in Part 4, to avoid introducing even more tools, let’s use GitHub Actions as the CI server.
Head into the folder where you’ve been working on the code samples for this blog post series and make sure you’re on the main branch, with the latest code:
$ cd fundamentals-of-devops
$ git switch main
$ git pull origin mainNext, create a new ch5 folder for this blog post’s code examples, and copy into ch5 the sample-app folder from Part 4, where you had a Node.js app with automated tests:
$ mkdir -p ch5
$ cp -r ch4/sample-app ch5/sample-appWith that done, create a new folder called .github/workflows in the root of your repo:
$ mkdir -p .github/workflowsIn that folder, create app-tests.yml, with the contents shown in Example 85:
name: Sample App Tests
on: push (1)
jobs: (2)
sample_app_tests: (3)
name: "Run Tests Using Jest"
runs-on: ubuntu-latest (4)
steps:
- uses: actions/checkout@v2 (5)
- name: Install dependencies (6)
working-directory: ch5/sample-app
run: npm install
- name: Run tests (7)
working-directory: ch5/sample-app
run: npm testWith GitHub Actions, you use YAML to define workflows, which are configurable automated processes that run one or more jobs in response to certain triggers. Here’s what the preceding workflow does:
| 1 | The on block is where you define the triggers that will cause this workflow to run. The preceding code configures this workflow to run every time you do a git push to this repo. |
| 2 | The jobs block defines one or more jobs—automations—to run in this workflow. By default, jobs run sequentially, but you can also configure jobs that run concurrently, as well as creating dependencies and passing data between jobs. |
| 3 | This workflow defines just a single job, which runs the tests for the sample app. |
| 4 | Each job runs on a certain type of runner, which is how you configure the hardware (CPU, memory) and software (operating system and dependencies) to use for the build. The preceding code uses the ubuntu-latest runner, which gives you a GitHub-hosted server with the default hardware configuration (2 CPUs and 7GB of RAM, as of 2024) and a software configuration that has Ubuntu and commonly used software development tools pre-installed (including Node.js). |
| 5 | Each job consists of a series of steps that are executed sequentially. The first step in this job runs another workflow via the uses keyword. This is one of the best features of GitHub Actions: you can share and reuse workflows, including both public, open source workflows (which you can discover in the GitHub Actions Marketplace) and private, internal workflows within your own organization. The preceding code uses the public actions/checkout workflow to check out the code for your repo. |
| 6 | The second step in this job uses the run keyword, which you can use to run an arbitrary shell command, to execute npm install in the ch5/sample-app folder to install the app’s dependencies. |
| 7 | The third step in this job uses the run keyword to execute npm test, which runs the app’s automated tests. |
If all the steps succeed, the job will be marked as successful (green); if any step fails—e.g., npm test exits with a non-zero exit code because one of the tests fails—then the job will be marked as failed (red).
To try it out, first commit and push the sample app and workflow code to your repo:
$ git add ch5/sample-app .github/workflows/app-tests.yml
$ git commit -m "Add sample-app and workflow"
$ git push origin mainNext, create a new branch called test-workflow:
$ git switch -c test-workflowMake a change to the sample app to intentionally return some text other than "Hello, World!", as shown in Example 86:
res.send('Fundamentals of DevOps!');Commit and push these changes to the test-workflow branch:
$ git add ch5/sample-app/app.js
$ git commit -m "Change response text"
$ git push origin test-workflowAfter running git push, the log output will show you the GitHub URL to open a pull request. Open that URL in your browser, fill out a title and description, and click "Create pull request." You should get a page that looks something like Figure 35:
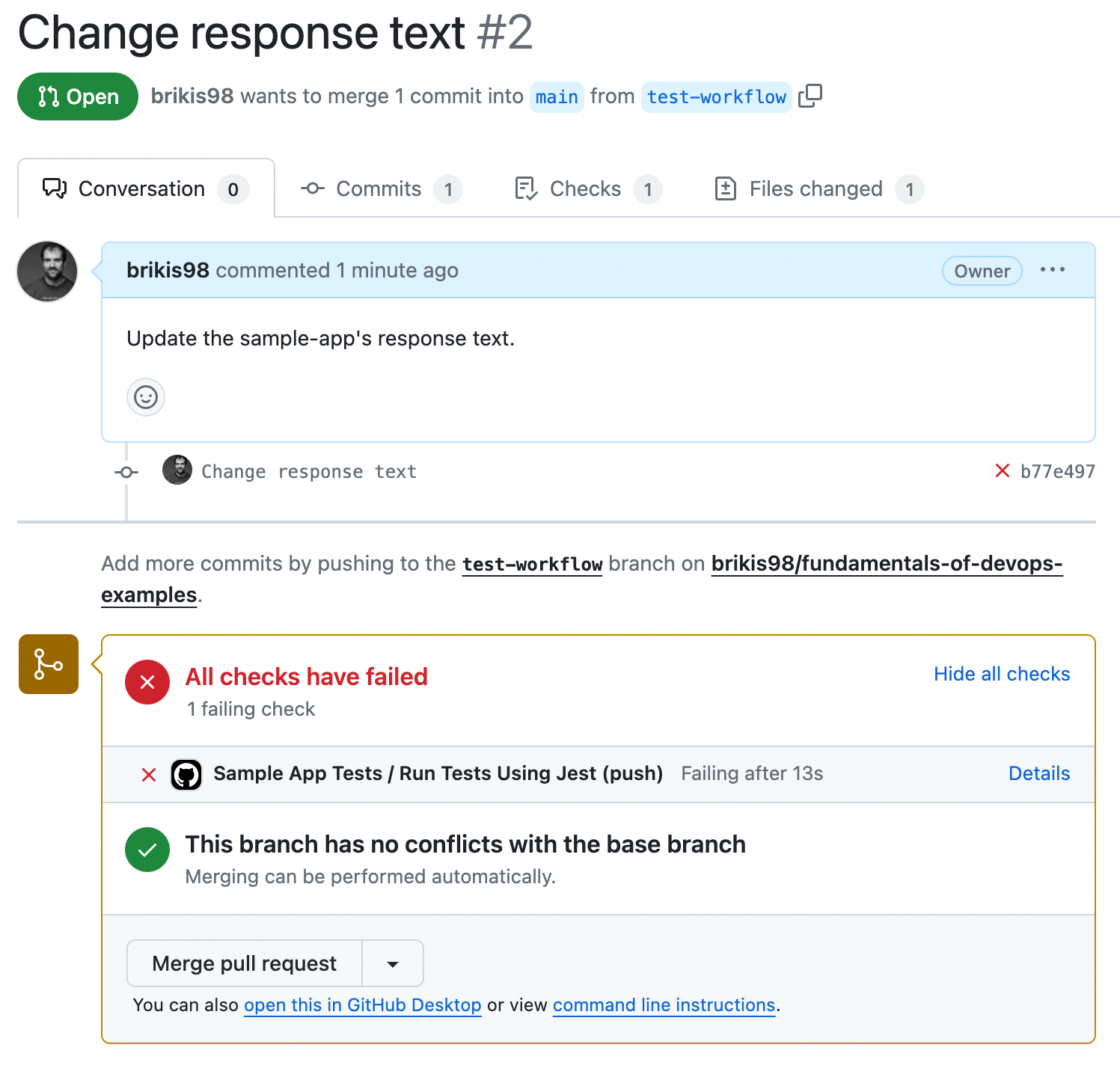
At the bottom of the pull request, you should see the "Sample App Tests" workflow has run, and, uh oh, looks like there’s an error. Click the Details link to the right of the workflow to see what went wrong. You should get a page that looks like Figure 36:
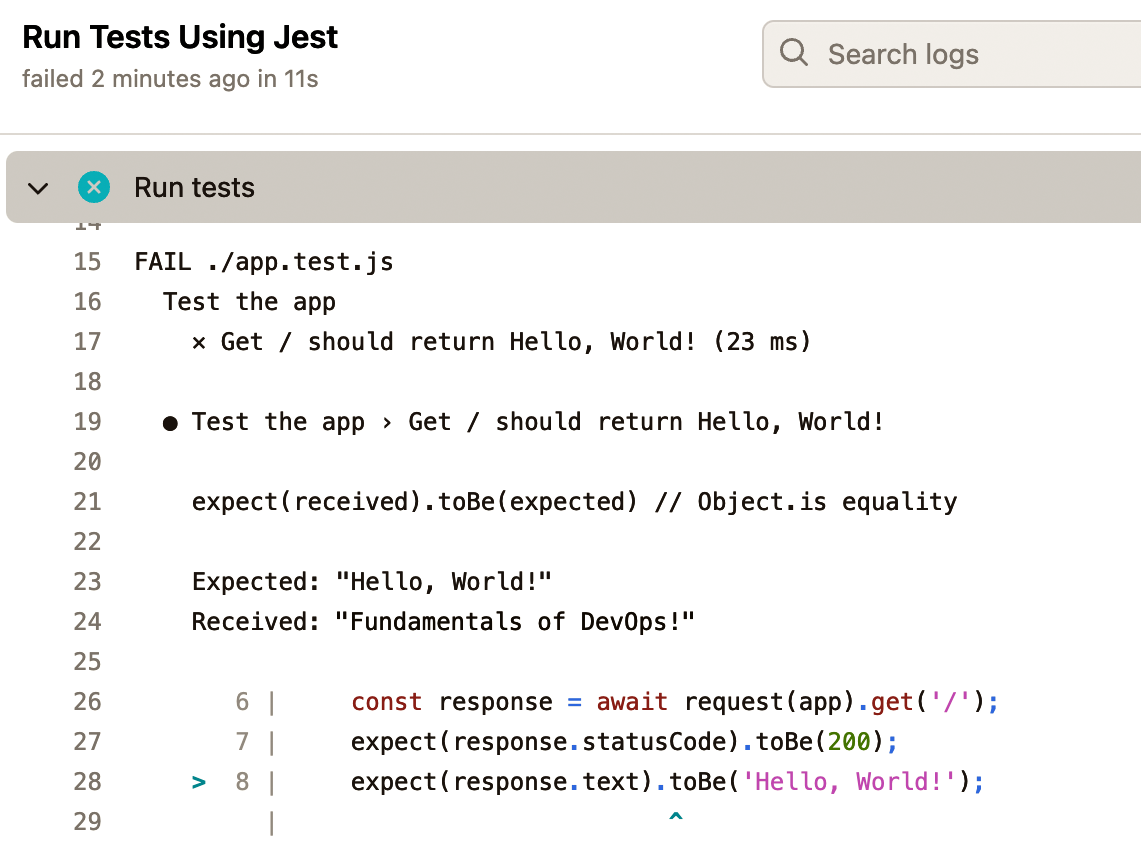
Aha! The automated test is still expecting the response text to be "Hello, World!" To fix this issue, update app.test.js to expect "Fundamentals of DevOps!" as a response, as shown in Example 87:
expect(response.text).toBe('Fundamentals of DevOps!');Commit and push these changes to the test-workflow branch:
$ git add ch5/sample-app/app.test.js
$ git commit -m "Update response text in test"
$ git push origin test-workflowThis will update your open PR, and automatically re-run your tests. After a few seconds, if you go back to your browser and look at the PR, you should see the tests passing, as shown in Figure 37:
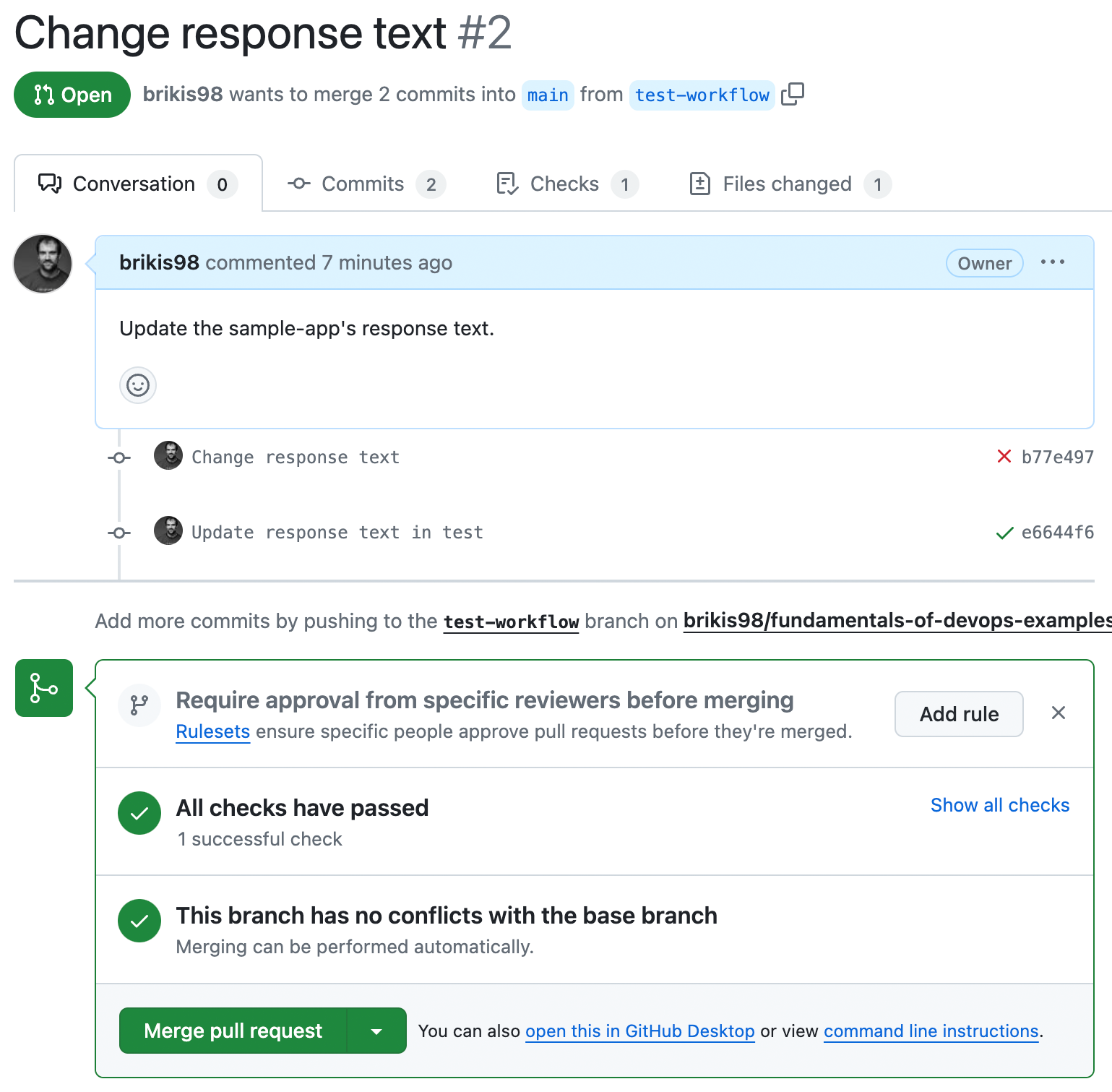
Congrats, you now have a self-testing build that will automatically run your app’s tests after every commit, and show you the results in every PR.
Get your hands dirty Here are a few exercises you can try at home to go deeper:
|
Merge the PR with the automated tests for the application code, and let’s move on to adding automated tests for the infrastructure code.
Machine User Credentials and Automatically-Provisioned Credentials
Now that you’ve seen how to configure a CI server to run the sample app’s automated tests, you may want to update the CI server to also run the infrastructure automated tests that you added for your OpenTofu code in Part 4. Since these tests deploy real resources into a real AWS account, you will need to give your CI server a way to authenticate to AWS.
This is a somewhat tricky problem. When a human being needs to authenticate to a machine, you can rely on that human memorizing some sort of secret, such as a password. But what do you do when a machine, such as a CI server, needs to authenticate to another machine? How can that machine "memorize" some sort of secret without leaking that secret to everyone else?
The first thing to know is that you should never use a real user’s credentials to solve this problem. That is, do not use your own AWS user credentials, or your own GitHub personal access token, or any type of credentials from any human being in a CI server or other types of automation. Here’s why:
- Departures
Typically, when someone leaves a company, you revoke all their access. If you were using their credentials for automation, then that automation will break.
- Permissions
The permissions that a human needs are typically different from a machine.
- Audit logs
Most systems maintain an audit log that records who performed what actions, which is useful for debugging and investigating security incidents. However, if a single user account is shared by both a human and automation, it’ll be hard to tell who did what in the audit log.
- Management
You typically want multiple developers at your company to be able to manage the automations you set up. If you use a developer’s user account for those automations, then the other developers won’t be able to access that user account to update the credentials or permissions.
So if you can’t use the credentials of a real user, what do you do? These days, there are two main options: machine user credentials and automatically-provisioned credentials. These are the topics of the next two sections.
Key takeaway #4 Use machine user credentials or automatically-provisioned credentials to authenticate from a CI server or other automations. |
Machine user credentials
One way to allow automated tools to authenticate is to create a dedicated machine user, which is a user account that is only used for automation (not by any human user). You create the user, generate credentials for them (e.g., access keys), and copy those credentials into whatever tool you’re using (e.g., into GitHub).
Machine users have a number of advantages: they never depart your company; you can assign them just the permissions they need; no human ever logs in as a machine user, so they only show up in audit logs when used in your automations; and you can share access to a single machine user account across your team by using a secrets management tool (a topic you’ll learn more about in Part 8).
However, machine users also have two major drawbacks. First, you have to copy their credentials around manually, which is tedious and error-prone. Second, the credentials you’re copying are typically long-lived credentials, so if these credentials are ever leaked, there is an extended window of time during which they could be exploited.
With some tools, machine users are the best you can do, but these days, some systems support automatically-provisioned credentials, as described in the next section.
Automatically-provisioned credentials
A second way to allow automated tools to authenticate is to use automatically-provisioned credentials, which are credentials the system can generate automatically, without any need for you to manually create machine users or copy/paste credentials. This requires that the system you’re authenticating from (e.g. a CI server) and the system you’re authenticating to (e.g., AWS) have an integration between them that supports automatically-provisioned credentials.
You’ve seen one form of automatically-provisioned credentials already earlier in this blog post series: IAM roles. Some of the resources you’ve deployed in AWS, such as the EKS cluster in Part 3, used IAM roles to authenticate and make API calls within your AWS account (e.g., to deploy EC2 instances as EKS worker nodes). You didn’t have to manually manage credentials to make this work. Instead, AWS automatically provisioned credentials that the EKS cluster could use.
With IAM roles, the thing you’re authenticating from and the thing you’re authenticating to are both AWS, but there are also systems that support automatically-provisioned credentials across different companies and services. One of the most common is Open ID Connect (OIDC), which is an open protocol for authentication. Not all services support OIDC, but in the cases where it is supported, it’s usually a more secure choice than machine user credentials, as OIDC gives you not only automatically-provisioned credentials (so no manual copy/paste), but also short-lived credentials that expire after a configurable period of time (e.g., one hour).
Conveniently for us, AWS supports OIDC authentication with GitHub. To set it up, you configure your AWS account to trust an identity provider (IdP), such as GitHub, whose identity AWS can verify cryptographically, and then you grant that provider permissions to assume specific IAM roles, subject to certain conditions, such as limiting which repos and branches can assume that IAM role (learn more about GitHub OIDC here). Since OIDC is a more secure option than machine user credentials, let’s try it out in the next section.
Example: Configure OIDC with AWS and GitHub Actions
Let’s set up an OIDC provider and IAM roles so that the automated tests you wrote for the lambda-sample OpenTofu module in Part 4 can authenticate to AWS from GitHub Actions. The first step is to configure GitHub as an OIDC provider, which you can do using an OpenTofu module called github-aws-oidc that lives in the blog post series’s sample code repo in the ch5/tofu/modules/github-aws-oidc folder.
Switch back to the main branch, pull down the latest changes (i.e., the PR you just merged), and create a new branch called opentofu-tests:
$ git switch main
$ git pull origin main
$ git switch -c opentofu-testsNext, create a new folder for a root module called ci-cd-permissions:
$ mkdir -p ch5/tofu/live/ci-cd-permissions
$ cd ch5/tofu/live/ci-cd-permissionsIn the that folder, create main.tf with the contents shown in Example 88:
provider "aws" {
region = "us-east-2"
}
module "oidc_provider" {
source = "brikis98/devops/book//modules/github-aws-oidc"
version = "1.0.0"
provider_url = "https://token.actions.githubusercontent.com" (1)
}This code sets the following parameters:
| 1 | provider_url: The URL of the IdP, which the preceding code sets to the URL GitHub uses for OIDC. |
In addition to the OIDC provider, you also need to create an IAM role that you can assume from GitHub Actions (using OIDC) for testing. The blog post series’s sample code repo has a module for that too: it’s called gh-actions-iam-roles, it lives in the ch5/tofu/modules/gh-actions-iam-roles folder, and it knows how to create several IAM roles for CI/CD with GitHub Actions. Example 89 shows how to update your ci-cd-permissions module to make use of the gh-actions-iam-roles module:
module "oidc_provider" {
# ... (other params omitted) ...
}
module "iam_roles" {
source = "brikis98/devops/book//modules/gh-actions-iam-roles"
version = "1.0.0"
name = "lambda-sample" (1)
oidc_provider_arn = module.oidc_provider.oidc_provider_arn (2)
enable_iam_role_for_testing = true (3)
# TODO: fill in your own repo name here!
github_repo = "brikis98/fundamentals-of-devops-examples" (4)
lambda_base_name = "lambda-sample" (5)
}This code configures the following parameters:
| 1 | name: The base name for the IAM roles and all other resources created by this module. The preceding code sets this to "lambda-sample," so the IAM role for testing will be called "lambda-sample-tests." |
| 2 | oidc_provider_arn: Specify the OIDC provider that the IAM roles created by this module will add to their trust policy, which will allow that provider to assume these IAM roles. The preceding code sets this to the OIDC provider you just created using the github-aws-oidc module. |
| 3 | enable_iam_role_for_testing: If set to true, create the IAM role for automated testing. You’ll see the other IAM roles this module can create a little later. |
| 4 | github_repo: The GitHub repo that will be allowed to assume the IAM roles using OIDC. You will need to fill in your own GitHub repo name here. Under the hood, the gh-actions-iam-roles module sets conditions in the trust policies of each IAM role to specify which repos and branches in GitHub are allowed to assume that IAM role. For the testing IAM role, all branches in the specified repo will be allowed to assume the IAM role. |
| 5 | lambda_base_name: The base name you use for the lambda-sample module and all the resources it creates. This should be the same value you use for the name parameter in that module. This is necessary so the gh-actions-iam-roles module can create IAM roles that only have permissions to manage the lambda-sample resources, and no other resources. |
You should also create a file called outputs.tf that outputs the testing IAM role ARN, as shown in Example 90:
ci-cd-permissions module (ch5/tofu/live/ci-cd-permissions/outputs.tf)output "lambda_test_role_arn" {
description = "The ARN of the IAM role for testing"
value = module.iam_roles.lambda_test_role_arn
}Deploy this module as usual, authenticating to AWS, and running init and apply:
$ tofu init
$ tofu applyAfter apply completes, you should see an output variable:
Outputs: lambda_test_role_arn = "arn:aws:iam::111111111111:role/lambda-tests"
Take note of the lambda_test_role_arn output value, as you’ll need it soon. With the OIDC provider and IAM role in place, you can now run the automated tests for your infrastructure code.
Example: Run Automated Tests for Infrastructure in GitHub Actions
To run the automated tests for your infrastructure code in GitHub Actions, you first need the infrastructure code itself. Copy over the lambda-sample module that had automated tests from Part 4:
$ cd fundamentals-of-devops
$ cp -r ch4/tofu/live/lambda-sample ch5/tofu/liveNow you have the code to test, but you should make some changes to it before running those tests in a CI environment. In a CI environment, you may have many tests running concurrently, which is a good thing, as it can help reduce test times. However, the lambda-sample module currently hard-codes the names of all of its resources (e.g., it hard-codes the name of the Lambda function and the IAM role), so if several developers are running that test concurrently in CI, you’ll get errors due to name conflicts.
To fix this issue, the first step is to add a variables.tf file to the lambda-sample module with the contents shown in Example 91:
lambda-sample module (ch5/tofu/live/lambda-sample/variables.tf)variable "name" {
description = "The base name for the function and all other resources"
type = string
default = "lambda-sample"
}This defines a name variable which you can use to namespace all the resources created by this module. The default value is "lambda-sample," which is exactly the value the module used before, so the default behavior doesn’t change, but by exposing this input variable, you’ll be able to override the value at test time.
Next, update main.tf to use var.name instead of any hard-coded names, as shown in Example 92:
lambda-sample module to use the name input variable instead of hard-coded names (ch5/tofu/live/lambda-sample/main.tf)module "function" {
# ... (other params omitted) ...
name = var.name
}Now you can create a new workflow called infra-tests.yml in .github/workflows, with the contents shown in Example 93:
name: Infrastructure Tests
on: push
jobs:
opentofu_test:
name: "Run OpenTofu tests"
runs-on: ubuntu-latest
permissions: (1)
id-token: write
contents: read
steps:
- uses: actions/checkout@v2
- uses: aws-actions/configure-aws-credentials@v3 (2)
with:
# TODO: fill in your IAM role ARN!
role-to-assume: arn:aws:iam::111111111111:role/lambda-sample-tests (3)
role-session-name: tests-${{ github.run_number }}-${{ github.actor }} (4)
aws-region: us-east-2
- uses: opentofu/setup-opentofu@v1 (5)
- name: Tofu Test
env:
TF_VAR_name: lambda-sample-${{ github.run_id }} (6)
working-directory: ch5/tofu/live/lambda-sample
run: | (7)
tofu init -backend=false -input=false
tofu test -verboseThis workflow, which runs on push, defines one job, which runs OpenTofu tests:
| 1 | By default, every GitHub Actions job gets contents: read permissions in your repo, which allows that job to check out the code in the repo. In order to use OIDC, you need to add the id-token: write permissions. This will allow the workflow to issue an OIDC token for authenticating to AWS in (2). |
| 2 | Authenticate to AWS using OIDC. This calls the AssumeRoleWithWebIdentity API to exchange the OIDC token for temporary AWS credentials. |
| 3 | The IAM role to assume. Make sure to fill in the IAM role ARN from the lambda_test_role_arn output in the previous section. |
| 4 | The name to use for the session when assuming the IAM role. This shows up in audit logging, so the preceding code includes useful information in the session name, such the run number (which is different each time you run the tests) and which GitHub user triggered the workflow. |
| 5 | Install OpenTofu. |
| 6 | Set the name input variable to a value that will be unique for each test run, which allows you to run tests concurrently. |
| 7 | Kick off the tests by running tofu init and tofu test. Note that the init command sets backend=false to skip backend initialization. Later in this post, you’ll start using backends with the lambda-sample module, which is useful for deployment, but not something you need to enable at test time. |
Add, commit, and push all the changes to the opentofu-tests branch, and then open a pull request. You should see something similar to Figure 38:
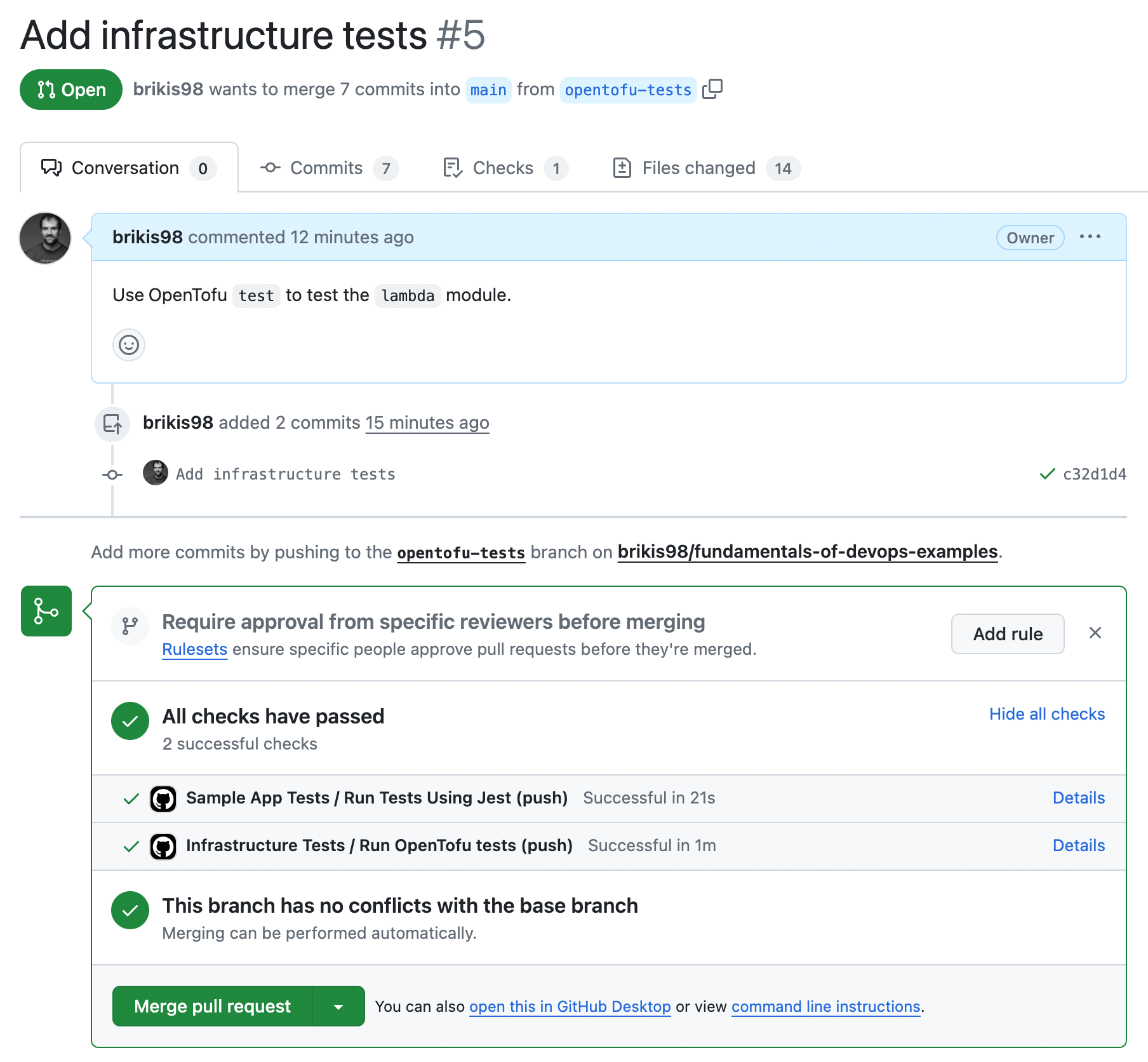
Congrats, you should now have both automated tests for your app code and for your infrastructure code running, as you can see at the bottom of the PR! After a minute or two, if everything is configured correctly, and the tests are passing, merge the PR.
Get your hands dirty Here’s an exercise you can try at home to go deeper:
|
You now have a self-testing build that runs your application and infrastructure tests after every commit. If you keep growing your test suite, and all your developers regularly integrate their work, your code will always be in a deployable state. But how do you actually deploy it? That’s the topic of the next section.
Continuous Delivery (CD)
Continuous delivery (CD) is a software development practice where you ensure that you can deploy to production at any time in a manner that is fast, reliable, and sustainable. You could choose to deploy daily, several times a day, thousands of times per day, or even after every single commit that passes the automated tests; this last approach is known as continuous deployment. The key with CD is not how often you deploy, but to ensure that the frequency of deployment is purely a business decision—not something limited by your technology.
Key takeaway #5 Ensure you can deploy to production at any time in a manner that is fast, reliable, and sustainable. |
If you’re used to a painful deploy process that happens only once every few weeks or months, then deploying many times per day may sound like a nightmare, and deploying thousands of times per day may sound impossible. But this is yet another place where, if it hurts, you need to do it more often.
To make it possible to deploy more often—and more importantly, to make it possible to deploy any time you want—you typically need to fulfill two requirements:
The code is always in a deployable state: You saw in the previous section that this is the key benefit of practicing CI. If everyone is integrating their work regularly, and you have a self-testing build with a sufficient suite of tests, then your code will always be ready to deploy.
The deployment process is sufficiently automated: To practice CD, your deployments must be fast, reliable, and sustainable. You can’t meet those requirements with a deployment process that involves many manual steps, so CD requires automating your deployment process.
This section focuses on item (2), automating the deployment process. Managing your infrastructure as code, using the tools in Part 2, gets you a large part of the way there. To get the rest of the way there, you need to automate the process around using IaC. This includes implementing deployment strategies and a deployment pipeline, as discussed in the next two sections.
Deployment Strategies
There are many deployment strategies that you can use to roll out changes: some involve downtime, while others do not; some are easy to implement, while others are more complicated; some only work with stateless apps, which are apps that don’t need to persist any of the data that they store on their local hard drives (e.g., most web frontend apps are stateless), while others also work with stateful apps, which are apps that store data on their local hard disks that needs to be persisted across deployments (e.g., any sort of database or distributed data system).
The next several sections will go over two types of deployment strategies, which I’ll refer to as core deployment strategies and add-on deployment strategies. Core deployment strategies are the main strategies you use to deploy your code. Add-on deployment strategies are strategies that can only be used in conjunction with a core deployment strategy. Let’s start with the core deployment strategies.
Core deployment strategies
The following is a list of the most common strategies for deploying apps:
- Downtime deployment
This is the most basic deployment strategy, where you take downtime to roll out changes, as shown in Figure 39:
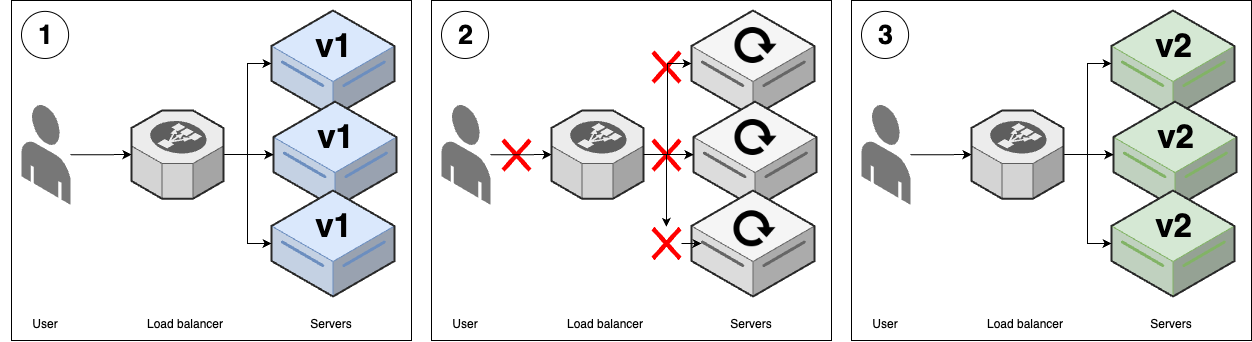 Figure 39. Downtime deployment
Figure 39. Downtime deploymentYou start with several replicas of v1 of your app.
You take all the v1 nodes down to update them to v2. While the update is happening, your users get an outage.
Once the deployment is completed, you have v2 running everywhere, and your users are able to use the app again.
- Rolling deployment without replacement
This is the deployment strategy you saw in Part 3, where you roll out new versions of your app onto new servers, and once the new versions of the app start to pass health checks, you remove the old versions, as shown in Figure 40:
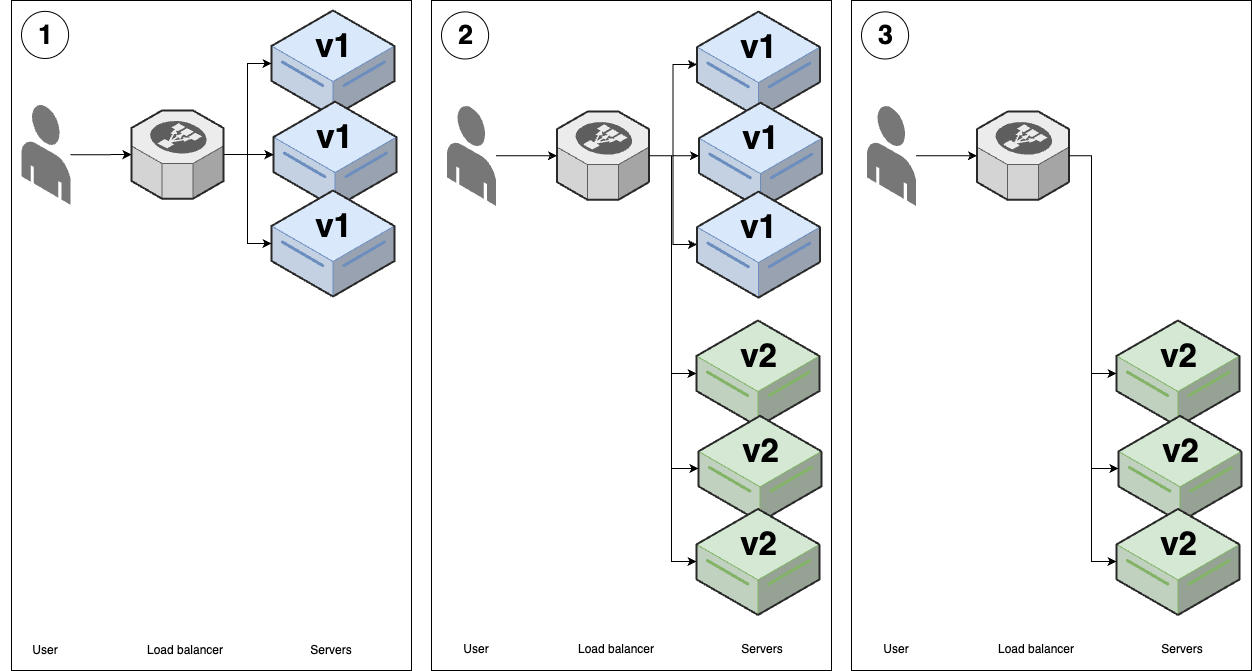 Figure 40. Rolling deployment without replacement
Figure 40. Rolling deployment without replacementYou start with several replicas of v1 of your app.
You start deploying v2 of your app onto new servers. Once the v2 apps come up and start passing health checks, the load balancer will send traffic to them, so for some period of time, users may see both v1 and v2 of your app.
As the v2 apps start passing health checks, you gradually undeploy the v1 apps, until you end up with just v2 running.
- Rolling deployment with replacement
This is identical to the previous strategy, except you remove the old version of the app before booting up the new version, as shown in Figure 41. This is especially useful for stateful apps, so Figure 41 shows how the deployment affects not only servers, but also their hard-drives.
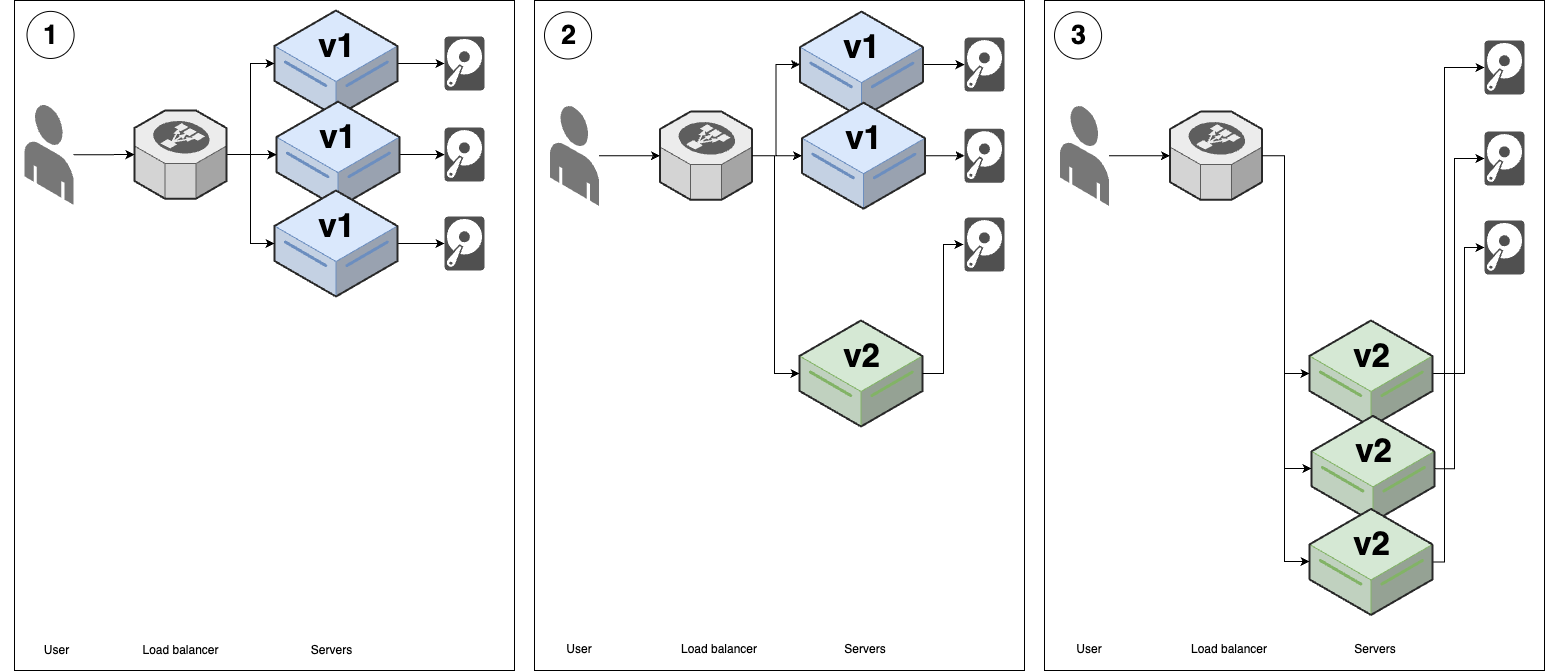 Figure 41. Rolling deployment with replacement
Figure 41. Rolling deployment with replacementYou start with several replicas of v1 of your app, each with a hard-drive attached.
You shut down a v1 replica, and then start a v2 replica with the v1 replica’s hard-drive. You can do this with mutable infrastructure, where you modify the server running v1 in-place to run v2, or with immutable infrastructure, where you boot up a new server to run v2, and move the hard-drive (typically a network-attached hard drive, as you’ll learn in Part 9) over from the v1 server.
You repeat the process in (2) until all v1 replicas are replaced with v2.
- Blue-green deployment
In this strategy, you bring up the new (green) version of your app, wait for it to be fully ready, and then instantaneously switch all traffic from the old version (blue) to the new version (green), as shown in Figure 42:
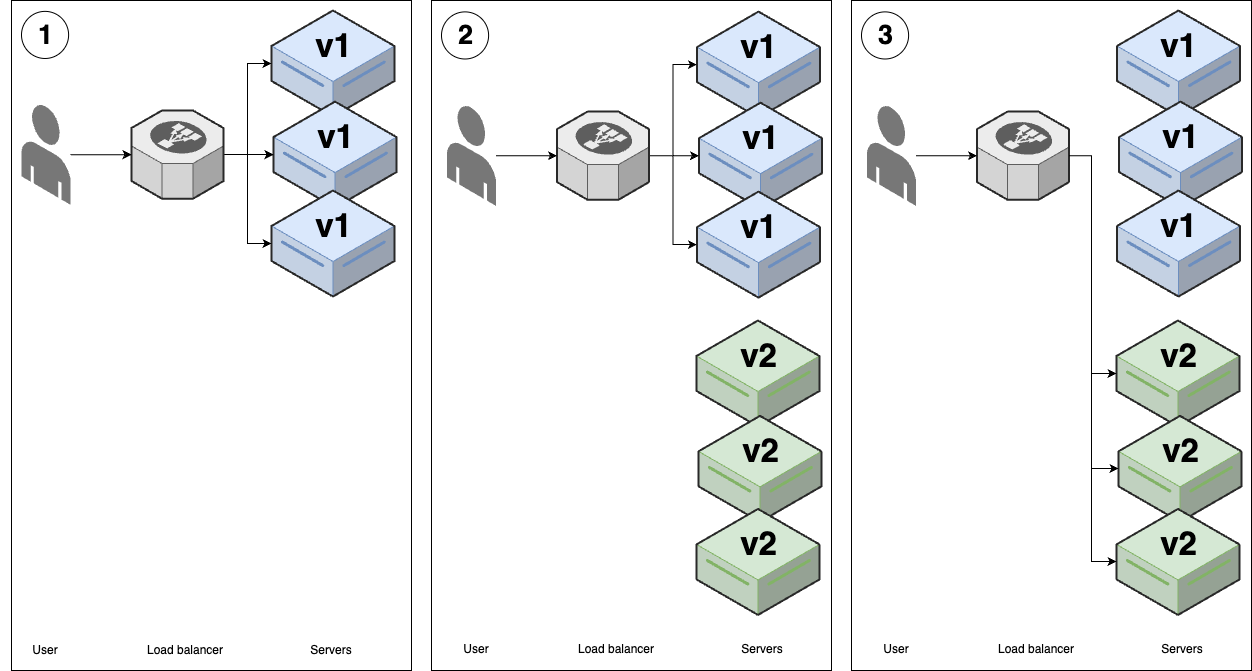 Figure 42. Blue-green deployment
Figure 42. Blue-green deploymentYou start with several replicas of v1 of your app (blue).
You start deploying v2 of your app (green) onto new servers. The v2 apps start to go through health checks in the load balancer, but the load balancer does not yet send any traffic to them.
When all the v2 replicas are passing health checks, you do an instantaneous switchover, moving all traffic from v1 (blue) to v2 (green). At that point, you undeploy all the v1 servers, leaving just v2 (alternatively, you may choose to keep the v1 servers around for a period of time in case you need to do a rollback).
Now that you’ve seen the core deployment strategies, how do they compare?
Comparing core deployment strategies
You can compare the core deployment strategies across the following dimensions:
- User experience
During a deployment, do users experience an outage? Do users alternately see the old and new versions of your app (a jarring user experience that can cause bugs), or do they instantaneously switch from the old version to the new?
- Works with stateless apps
Can you use this strategy to deploy stateless apps?
- Works with stateful apps
Can you use this strategy to deploy stateful apps?
- Resource overhead
Does this strategy increase resource usage (e.g., extra servers)?
- Orchestration support
Is this strategy widely supported by orchestration tools?
Table 9 shows how the deployment strategies compare along these dimensions:
| Downtime deployment | Rolling without replacement | Rolling with replacement | Blue-green | |
|---|---|---|---|---|
User experience |
|
|
|
|
Stateless apps |
|
|
|
|
Stateful apps |
|
|
|
|
Resource overhead |
|
|
|
|
Orchestration support |
|
|
|
|
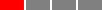



For deploying stateless apps, blue-green deployments usually offer the best user experience. However, not all orchestration tools support this strategy, and not all companies can afford to double their resource usage for every deployment (especially if you’re on-prem), so in those cases, rolling deployments without replacement are your best bet. For deploying stateful apps, where each replica has a unique set of data on its local hard-drive that needs to be persisted across the deployment (e.g., distributed data stores such as Consul, Elasticsearch, and ZooKeeper), rolling deployments with replacement is typically the way to go. As for downtime deployments, the only time I’d use them is if you need to do a data migration, as taking a brief downtime during a deployment can sometimes make a data migration 10x cheaper and less error-prone (compared to trying to do it with no downtime, which requires complicated processes such as double writes).
All the deployment strategies you’ve seen so far can be used standalone. Let’s now turn our attention to strategies that are meant to be combined with other strategies.
Add-on deployment strategies
The following is a list of the most common strategies you can combine with the core deployment strategies to make your deployments safer and more effective (note, these are not mutually exclusive; you can, and often do, use multiple add-ons together):
- Canary deployment
The name "canary" comes from the proverbial "canary in the coal mine," which is a bird that coal miners would take into mines with them, as canaries are more sensitive to poisonous gasses than humans, so if the canary starts reacting poorly, it’s an early warning signal that you need to get out immediately. The idea with canary deployments is similar: you initially deploy just a single replica of your new code, and if that replica shows any problems, you roll back the deployment before it can cause more damage, as shown in Figure 43.
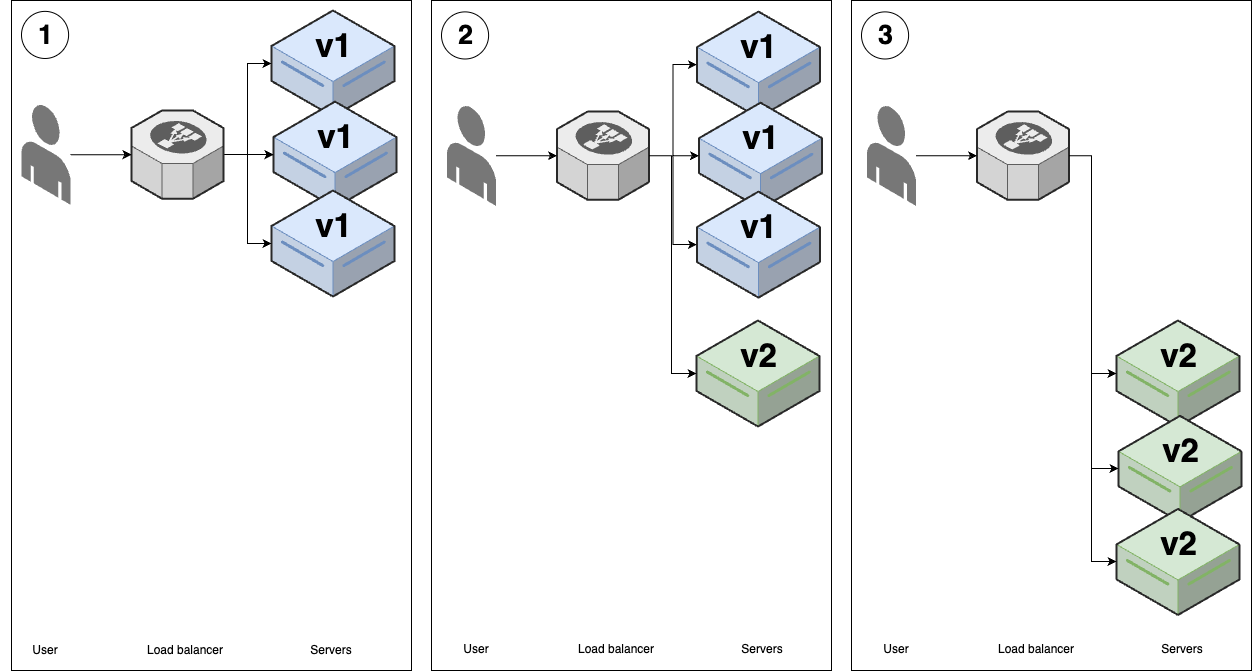 Figure 43. Canary deployment
Figure 43. Canary deploymentYou start with several replicas of v1 of your app running.
You deploy a single replica of v2, called the canary server, and send traffic to it. You then compare the canary server to the v1 replicas (the control). If you see any differences—e.g., the canary has higher error rates or higher memory usage than the control—this gives you an early warning that the deployment has problems, and you can roll it back before it does too much damage.
If you can’t find any undesired differences between the canary and the control, then you can roll out v2 fully using one of the other strategies, such as rolling deployment.
- Feature toggle deployment
You saw feature toggles earlier in this blog post as a technique for being able to merge code into
mainregularly, even while making large-scale changes. Feature toggles can also have a profound impact on how you deploy software, as you’ll see shortly. Figure 43 shows how feature toggle deployments work: Figure 44. Feature toggle deployment
Figure 44. Feature toggle deploymentYou start with several replicas of v1 of your app running.
You deploy v2 of your app using one of the other strategies, such as rolling deployment, but with a key difference: any new features in the new version are wrapped in a feature toggle, and off by default. Therefore, even though v2 is deployed, users won’t see any difference.
After the deployment is done, you can then release the new features in v2 using your feature toggle service, and only then will users see new functionality.
- Promotion deployment
The idea with promotion deployments (AKA promotion workflows) is to deploy your code across multiple environments (a topic you’ll learn about in Part 6), starting with pre-production environments (e.g., dev, stage), and ending up in your production environment, with the hope that you can catch issues in the pre-production environments before they affect production, as shown in Figure 45:
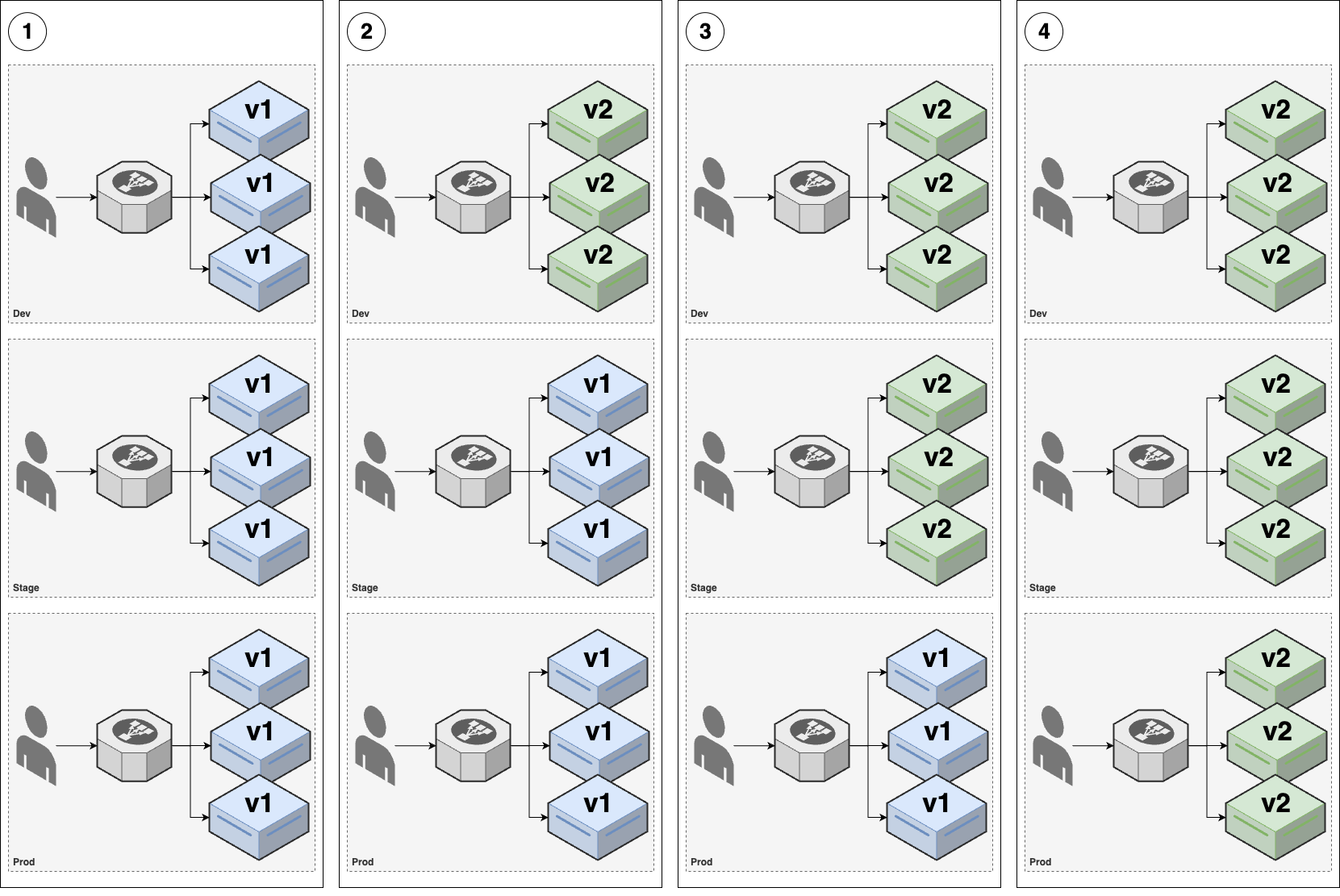 Figure 45. Promotion deployment
Figure 45. Promotion deploymentLet’s say you have three environments: dev, stage, and prod. Initially, v1 of your app is running in all three of those environments.
You use one of the other deployment strategies (e.g., rolling deployment) to deploy v2 to dev, and do a round of testing.
If everything works well in dev, you deploy exactly the same v2 code—also known as promoting v2—to stage, and do another round of testing.
If everything works well in stage, you finally promote v2 to prod.
Now that you’ve seen all the add-on deployment strategies, how do they compare?
Comparing add-on deployment strategies
Canary deployments offer one way to reduce the blast radius if a deployment goes wrong. One of the reasons the companies you read about in The Impact Of World-Class Software Delivery have a lower change failure rate is that they use canary deployments to catch issues early, before they escalate into major outages.
Feature toggles reduce the blast radius even further. In fact, feature toggles are such a powerful tool, that I often describe them as a "superpower" for DevOps. The following are just a few of the superpowers you get from using feature toggles:
- Separate deployment from release
Without feature toggles, every time you deploy new code (e.g., roll out a new Docker image into a Kubernetes cluster), you also automatically release every single new feature in that code, all at once. With feature toggles, the deployment and release steps are now separate, which makes deployments considerably less risky. This is another one of the key ingredients that makes it possible for world-class companies to deploy thousands of times per day.
- Resolve issues without deploying new code
Not only do feature toggles allow you to release features separately from deploying new code, but they also allow you to unrelease features without code changes. That is, if you enable a feature toggle, and you discover a serious bug, you can disable that feature toggle to turn the feature off. Alternatively, if the feature is working correctly, but you can’t handle the amount of load, you can disable the feature toggle for a subset of users, until the load is more manageable. In other words, feature toggles allow you to offer a reduced level of service (a form of graceful degradation), which is usually preferable to a complete outage, and they give you a way to resolve issues that is much faster than having to write and deploy new code. It’s one of the big reasons world-class companies can recover from downtime 2293x faster.
- Ramp new features
A remarkable benefit of separating deployment from release is that it allows you to ramp features gradually, rather than them being on for all users at once. For example, at LinkedIn, one of the changes from Project Inversion was to require all new features to be wrapped in feature toggles, and to ramp them up gradually; Facebook, Google, and many other companies use similar processes. Every new feature starts off disabled by default, and when it’s ready for testing, we’d first turn it on only for employees, so that we could test it internally; if you work at companies like LinkedIn, Facebook, or Google, your experience of those products can be very different from that of the general public. Once things are looking good in internal testing, we could then ramp the feature up, turning it on for, say, a random 1% of users. We’d then observe those users, looking at their error rates to make sure there were no problems. If everything looked OK, we’d ramp the feature to 10% of users, then 50%, and eventually 100%. If we hit issues at any point, we could pause the ramp, or ramp back down.
- A/B test features
Feature toggles also give you the ability to do A/B testing, where you can compare how different versions of your product perform against each other. This allows you to use data to inform product decisions, a concept known as data-driven product development, which you’ll learn more about in Part 10.
The ability to separate deployment from release, carefully ramp new features, and quickly shut off features that are causing issues is such a huge advantage in agility, that once you get past a certain scale as a company, you should consider wrapping all new features in feature toggles. To be fair, feature toggles have some drawbacks, too. To use feature toggles, you have to run and maintain an extra feature toggle service, or pay for one from a 3rd party. Moreover, as you add more if-statements with feature toggle lookups, you get more forks in your code, which makes the code harder to maintain and test. If you’re going to use feature toggles, you’ll need to create the discipline (and automation) to ensure that you systematically remove if-statements for feature toggles that are unlikely to change again (e.g., feature toggles more than 1 year old). But this is a small price to pay for the superpowers you gain. The first time you’re paged at 3 AM, and you’re able to resolve the issue in minutes by shutting off a feature toggle, and going back to sleep, you’ll see what I mean.
Promotion workflows are also worth adopting at most companies, as they give you multiple chances to catch errors before those errors make it to prod. Moreover, whereas just about all the deployment strategies you’ve seen so far only work for deploying application code (i.e., apps written in Java, Ruby, Python, JavaScript, etc.), promotion workflows can also be used to deploy infrastructure code (i.e., OpenTofu, Pulumi, CloudFormation). With infrastructure code, deployments are fairly binary: either you make an infrastructure change, or you don’t; either you create (or delete!) that database, or you don’t. There’s no gradual rollout, no feature toggles, no canaries, etc. That makes infrastructure deployments harder and riskier. To mitigate these risks, you typically rely on promotion workflows, so you can try out the deployments in pre-production environments, and you also review execution plans (e.g., tofu plan output) before deploying. You’ll see an example of this later in this blog post.
Now that you’ve seen all the basic deployment strategies, let’s turn our attention to how to implement these strategies as code, in the form of deployment pipelines.
Deployment Pipelines
A deployment pipeline is the process you use to go from an idea to live code that affects your users. It consists of all the steps you must go through on the way to release. Deployment pipelines are different at every company, as they are effectively capturing your company’s processes, policies, and requirements as code, but most pipelines include the following:
- Commit
How do you get code into version control? PRs? Trunk-based development?
- Build
What compilation and build steps do you need? How do you package the code?
- Test
What automated tests do you run against the code? What manual tests?
- Review
What review processes do you use? Who approves merges and deployments?
- Deploy
How do you get code into production? How do you release new functionality?
Typically, you run a deployment pipeline on a deployment server, and not a developer’s computer (you’ll see later in this blog post why). One option is to use the same server you use for CI, such as the ones you saw earlier in the post (e.g., GitHub Actions, CircleCi, GitLab). Another option is to use deployment servers that are designed for a specific technology: for example, for OpenTofu and Terraform, you might use the HashiCorp Cloud Platform, Gruntwork Pipelines or env0 (full list), and for Kubernetes, you may use Argo CD or Flux (full list).
You also need to pick a language for defining your pipeline as code. The most common option is to use the workflow definition language that comes with your CI server: e.g., GitHub Actions workflows are defined in YAML. Other options include defining workflows in scripting languages (e.g., Ruby, Python, Bash), your build system’s language (e.g., NPM, Maven, Make), and, a relatively recent option is to use a tool designed for defining workflows that can run across a variety of platforms, including on your own computer (for easier testing), such as Dagger or Common Workflow Language (full list). In many cases, a deployment pipeline will use multiple languages and tools together.
Even once you’ve picked out a deployment server and a language, there are still many different ways to define a pipeline. Arguably the most popular approach these days is GitOps, which is a set of tools and processes built around Git that implement the following principles:[25]
- Declarative
GitOps systems define their state declaratively. That means you separate the configuration, which defines your desired end state, from the implementation, which includes all the scripts, API calls, etc. used to achieve the end state. In practice, this usually means that you manage all your infrastructure as code with declarative tools such as OpenTofu (as you saw in Part 2) and you manage your apps as code with tools such as Kubernetes (as you saw in Part 3).
- Versioned and Immutable
The desired state is stored in a way that enforces immutability, versioning, and retains a complete version history. In practice, this usually means storing all your code in Git.
- Pulled Automatically
Software agents automatically pull the desired state declarations from the source. In practice, this means that everything the pipeline does is based on code pulled from Git; no one-off scripts or manual actions are allowed. This ensures that your desired state and the full history of changes is always tracked in Git. It also ensures the pipeline can run at any time, which is critical for the next item.
- Continuously Reconciled
Software agents continuously observe actual system state and attempt to apply the desired state. That means any time you have a divergence from the desired state (known as drift), either because the desired state changed (e.g., you pushed new code) or because the state of the real-world systems has changed (e.g., a server crashed), the pipeline takes action to reconcile the differences. Many pipelines that describe themselves as GitOps don’t achieve this principle fully, as they only handle the former type of change (i.e., they only run in response to changes in Git, such as a commit). The pipelines that handle both types of changes are typically built on systems with reconciliation loops, such as Kubernetes and the various continuous delivery tools built on top of Kubernetes (e.g., Argo CD and Flux), and certain continuous delivery tools for IaC that support drift detection (e.g., Terraform Cloud, Env0, and Gruntwork Pipelines).
The best way to understand a GitOps pipeline is to see an example, which is the focus of the next several sections. After that, you’ll learn about deployment pipeline patterns that I recommend for most companies.
Example: configure an automated GitOps pipeline in GitHub Actions
To avoid introducing too many new tools, let’s stick to using GitHub Actions as the deployment server and GitHub Actions YAML workflows as the primary language for defining a basic GitOps pipeline. The goal is to implement the following pipeline for the lambda-sample module:
- Commit code to a branch
The first step is to make some code changes in a branch.
- Open a pull request
Once the changes are ready to review, you open a PR.
- Run automated tests for the pull request
The deployment server runs automated tests against the open PR, including compiling the code, static analysis, unit tests, integration tests, and so on.
- Generate an execution plan for the pull request
The deployment server runs
tofu planto generate an execution plan for the PR.- Review and merge the pull request
Your team members review the PR, test results, and execution plan, and if everything looks good, merge the PR in.
- Run automations deployment for the request
Finally, your deployment server runs the automated deployment steps, which may include another round of automated testing, followed by running
tofu applyto deploy the changes.
Watch out for snakes: this is a simplified pipeline The pipeline described here is missing important aspects of a real-world GitOps pipeline, including:[26]
|
You already implemented most of this pipeline as part of setting up automated tests in the CI section. The only items remaining are the following:
When you open a PR, run
planon thelambda-samplemodule.When you merge a PR, run
applyon thelambda-samplemodule.
To add these items, you need to do the following steps:
Use a backend for OpenTofu state.
Add IAM roles for infrastructure deployments in GitHub Actions.
Define a pipeline for infrastructure deployments.
The following three sections will cover each of these steps.
Example: use a backend for OpenTofu state
In Part 2, you learned that, by default, OpenTofu uses the local backend to store OpenTofu state in .tfstate files on your local hard drive. For personal projects, this works just fine, but for professional projects with a team, you need a way to manage state that supports collaboration, locking, encryption, and multiple environments. This is where the other backends supported by OpenTofu come into play, such as Amazon Storage Service (S3), Azure Storage, and Google Cloud Storage (GCS). For the purposes of this blog post series, we will use S3 as a backend.
An understanding of S3 as an OpenTofu backend is required to proceed! The next few sections require that you have a basic understanding of OpenTofu backends, and in particular, the S3 backend. If these items are new to you, check out the How to manage state and environments with OpenTofu tutorial on this blog post series’s website to learn how to create an S3 bucket and DynamoDB table for state storage and how to configure OpenTofu to use them as a backend. |
To configure the lambda-sample module to use S3 as a backend, create an S3 bucket and DynamoDB table, and then add a backend.tf file to the lambda-sample module with the contents shown in Example 94:
terraform {
backend "s3" {
# TODO: fill in your own bucket name here!
bucket = "fundamentals-of-devops-tofu-state" (1)
key = "ch5/tofu/live/lambda-sample/terraform.tfstate" (2)
region = "us-east-2" (3)
encrypt = true (4)
# TODO: fill in your own DynamoDB table name here!
dynamodb_table = "fundamentals-of-devops-tofu-state" (5)
}
}Here’s what this code does:
| 1 | The S3 bucket to use as a backend. Fill in your own S3 bucket’s name here. |
| 2 | The filepath within the S3 bucket where the state file should be written. |
| 3 | The AWS region where you created your S3 bucket. |
| 4 | Enable server-side encryption in the S3 bucket. |
| 5 | The DynamoDB table to use for locking. Fill in your own table’s name here. |
Run tofu init in the lambda-sample module to configure it to use the new backend:
$ tofu init
Initializing the backend...
Do you want to copy existing state to the new backend?
Pre-existing state was found while migrating the previous "local" backend
to the newly configured "s3" backend. No existing state was found in the
newly configured "s3" backend. Do you want to copy this state to the new
"s3" backend? Enter "yes" to copy and "no" to start with an empty state.
Enter a value:OpenTofu will automatically detect that you already have a state file locally and prompt you to copy it to the new S3 backend. If you type yes and hit ENTER, you should see the following:
Successfully configured the backend "s3"! OpenTofu will automatically use this backend unless the backend configuration changes.
With this backend enabled, OpenTofu will automatically pull the latest state from this S3 bucket before running a command and automatically push the latest state to the S3 bucket after running a command, and it’ll use DynamoDB for locking. Commit your changes to the lambda-sample module and push them to main.
Now that you have a backend set up, you can move onto the next step, which is setting up IAM roles that will allow you to do deployments from GitHub Actions.
Example: add IAM roles for infrastructure deployments in GitHub Actions
Earlier in this blog post, you configured an OIDC provider to give GitHub Actions access to your AWS account for running automated tests. Now you need a way to give GitHub Actions access to your AWS account for deployments. Normally, you would deploy to a separate environment (separate AWS account) from where you run automated tests, so you’d need to configure a new OIDC provider in that environment. However, to keep things simple in this post, let’s use the same AWS account, and therefore the same OIDC provider, for both deployment and testing (you’ll learn how to set up additional environments in Part 6). Note that you still need to create new IAM roles for the following reasons:
The permissions you need for tests are different from those for deployment.
The permissions for deployment should be managed via two separate IAM roles: one for
planand one forapply. That’s because you wantplanto run on any branch before a PR has merged, and therefore, potentially before anyone has had a chance to review the changes, so theplanIAM role should be limited to read-only permissions: enough to see theplanoutput, but not enough to make any changes. On the other hand, theapplyIAM role is only used after a PR has been reviewed and merged tomain, so it’s safe to grant it write permissions.
Open up main.tf in the ci-cd-permissions module and add the code shown in Example 95 to enable creating IAM roles for both plan and apply:
ci-cd-permissions module to enable IAM roles for plan and apply (ch5/tofu/live/ci-cd-permissions/main.tf)
module "iam_roles" {
# ... (other params omitted) ...
enable_iam_role_for_plan = true (1)
enable_iam_role_for_apply = true (2)
# TODO: fill in your own bucket and table name here!
tofu_state_bucket = "fundamentals-of-devops-tofu-state" (3)
tofu_state_dynamodb_table = "fundamentals-of-devops-tofu-state" (4)
}This code does the following:
| 1 | Enable the IAM role for plan. This IAM role will get read-only permissions. The OIDC provider will be allowed to assume this role from any branch. |
| 2 | Enable the IAM role for apply. This IAM role will get both read and write permissions. The OIDC provider will only be allowed to assume this role from the main branch. This ensures that only merged PRs can be deployed. |
| 3 | Configure which S3 bucket to use for OpenTofu state. Make sure to fill in your own S3 bucket’s name here. The plan role will get read-only access to this bucket; the apply role will get read and write access. |
| 4 | Configure which DynamoDB table to use for OpenTofu state. Make sure to fill in your own DynamoDB table’s name here. The plan role will get read-only access to this table; the apply role will get read and write access. |
Next, update outputs.tf with new output variables, as shown in Example 96:
output "lambda_deploy_plan_role_arn" {
description = "The ARN of the IAM role for plan"
value = module.iam_roles.lambda_deploy_plan_role_arn
}
output "lambda_deploy_apply_role_arn" {
description = "The ARN of the IAM role for apply"
value = module.iam_roles.lambda_deploy_apply_role_arn
}Run apply to create the new IAM roles, and take note of the lambda_deploy_plan_role_arn and lambda_deploy_apply_role_arn outputs, which will contain the ARNs of those IAM roles. You’ll need these ARNs shortly.
Get your hands dirty Here are a few exercises you can try at home to go deeper:
|
Commit your changes to the ci-cd-permissions module and push them to main. You’re now finally ready to define the deployment pipeline itself.
Example: define a pipeline for infrastructure deployments
With all the prerequisites out of the way, you can finally implement a deployment pipeline for the lambda-sample module that will do the following:
When you open a PR, run
planon thelambda-samplemodule.When you merge a PR, run
applyon thelambda-samplemodule.
Let’s first create a workflow for the plan portion. Create a new file called .github/workflows/tofu-plan.yml with the contents shown in Example 97:
name: Tofu Plan
on:
pull_request: (1)
branches: ["main"]
paths: ["ch5/tofu/live/lambda-sample/**"]
jobs:
plan:
name: "Tofu Plan"
runs-on: ubuntu-latest
permissions:
pull-requests: write (2)
id-token: write
contents: read
steps:
- uses: actions/checkout@v2
- uses: aws-actions/configure-aws-credentials@v3
with:
# TODO: fill in your IAM role ARN!
role-to-assume: arn:aws:iam::111111111111:role/lambda-sample-plan (3)
role-session-name: plan-${{ github.run_number }}-${{ github.actor }}
aws-region: us-east-2
- uses: opentofu/setup-opentofu@v1
- name: tofu plan (4)
id: plan
working-directory: ch5/tofu/live/lambda-sample
run: |
tofu init -no-color -input=false
tofu plan -no-color -input=false -lock=false
- uses: peter-evans/create-or-update-comment@v4 (5)
if: always()
env:
RESULT_EMOJI: ${{ steps.plan.outcome == 'success' && '✅' || '⚠️' }}
with:
issue-number: ${{ github.event.pull_request.number }}
body: |
## ${{ env.RESULT_EMOJI }} `tofu plan` output
```${{ steps.plan.outputs.stdout }}```This workflow has a few things you haven’t seen before:
| 1 | Instead of running on push, this workflow runs on pull requests. More specifically, only on pull requests against the main branch that have modifications to the ch5/tofu/live/lambda-sample folder. |
| 2 | Add the pull-request: write permission, which is used in (5). |
| 3 | Assume the plan IAM role. Make sure to fill in your own IAM role ARN here from the lambda_deploy_plan_role_arn output variable. |
| 4 | Run tofu init and tofu plan, passing a few flags to ensure the commands run well in a CI environment: i.e., disable terminal colors and interactive prompts. There’s also a flag to disable locking, as you don’t need that for plan. |
| 5 | Post a comment on the pull request that contains the plan output. The comment is formatted in Markdown and includes both the plan output, and an emoji to help you see at a glance if the plan command ran successfully. |
Next, create a workflow for the apply portion in a new file called .github/workflows/tofu-apply.yml, with the contents shown in Example 98:
name: Tofu Apply
on:
push: (1)
branches: ["main"]
paths: ["ch5/tofu/live/lambda-sample/**"]
jobs:
apply:
name: "Tofu Apply"
runs-on: ubuntu-latest
permissions:
pull-requests: write
id-token: write
contents: read
steps:
- uses: actions/checkout@v2
- uses: aws-actions/configure-aws-credentials@v3
with:
# TODO: fill in your IAM role ARN!
role-to-assume: arn:aws:iam::111111111111:role/lambda-sample-apply (2)
role-session-name: apply-${{ github.run_number }}-${{ github.actor }}
aws-region: us-east-2
- uses: opentofu/setup-opentofu@v1
- name: tofu apply (3)
id: apply
working-directory: ch5/tofu/live/lambda-sample
run: |
tofu init -no-color -input=false
tofu apply -no-color -input=false -lock-timeout=60m -auto-approve
- uses: jwalton/gh-find-current-pr@master (4)
id: find_pr
with:
state: all
- uses: peter-evans/create-or-update-comment@v4 (5)
if: steps.find_pr.outputs.number
env:
RESULT_EMOJI: ${{ steps.apply.outcome == 'success' && '✅' || '⚠️' }}
with:
issue-number: ${{ steps.find_pr.outputs.number }}
body: |
## ${{ env.RESULT_EMOJI }} `tofu apply` output
```${{ steps.apply.outputs.stdout }}```This workflow is similar the one for plan, but with a few key differences:
| 1 | Run only on pushes to the main branch. |
| 2 | Assume the apply IAM role. Make sure to fill in your own IAM role ARN here from the lambda_deploy_apply_role_arn output variable. |
| 3 | Run tofu init and tofu apply, again passing a few flags to ensure the commands run well in a CI environment. Note also the use of the -lock-timeout=60m to ensure this command will wait up to 60 minutes if someone else has a lock (such as a concurrent apply being run by a previous merge). |
| 4 | If this push came from a pull request, use an open source GitHub Action to find the ID of that PR so that you can add the output of apply as a comment in (5). |
| 5 | If (4) found a PR, post a comment to that PR with the apply output. |
Commit these new workflow files directly to the main branch and then push them to GitHub:
$ git add .github/workflows
$ git commit -m "Add plan and apply workflows"
$ git push origin mainNow, let’s give this deployment pipeline a shot. First, create a new branch called deployment-pipeline-test:
$ git switch -c deployment-pipeline-testMake a change to the lambda-sample module, such as changing the text it returns, as shown in Example 99:
exports.handler = (event, context, callback) => {
callback(null, {statusCode: 200, body: "Fundamentals of DevOps!"});
};Make sure to also make the corresponding update to the assertion in the automated test in deploy.tftest.hcl, as shown in Example 100:
assert {
condition = data.http.test_endpoint.response_body == "Fundamentals of DevOps!"
error_message = "Unexpected body: ${data.http.test_endpoint.response_body}"
}Commit both of these changes, push them to the deployment-pipeline-test branch, open a pull request, and you should see a page that looks like Figure 46:
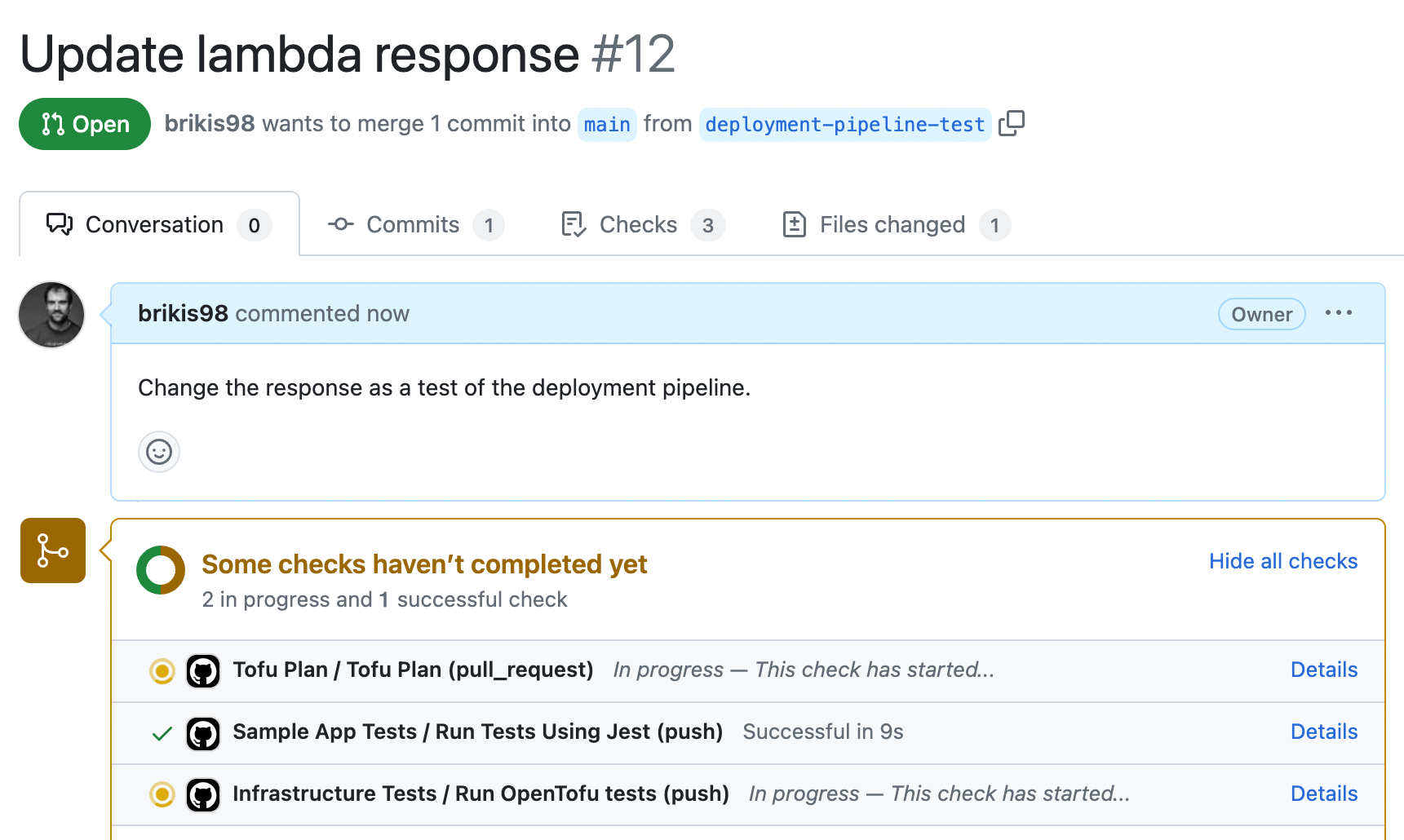
You should see three things running in your pipeline:
Automated tests for the sample app.
tofu testfor your infrastructure code.tofu planon thelambda-samplemodule.
When everything has finished, the PR should automatically be updated with a comment that shows the plan output, as shown in Figure 47:
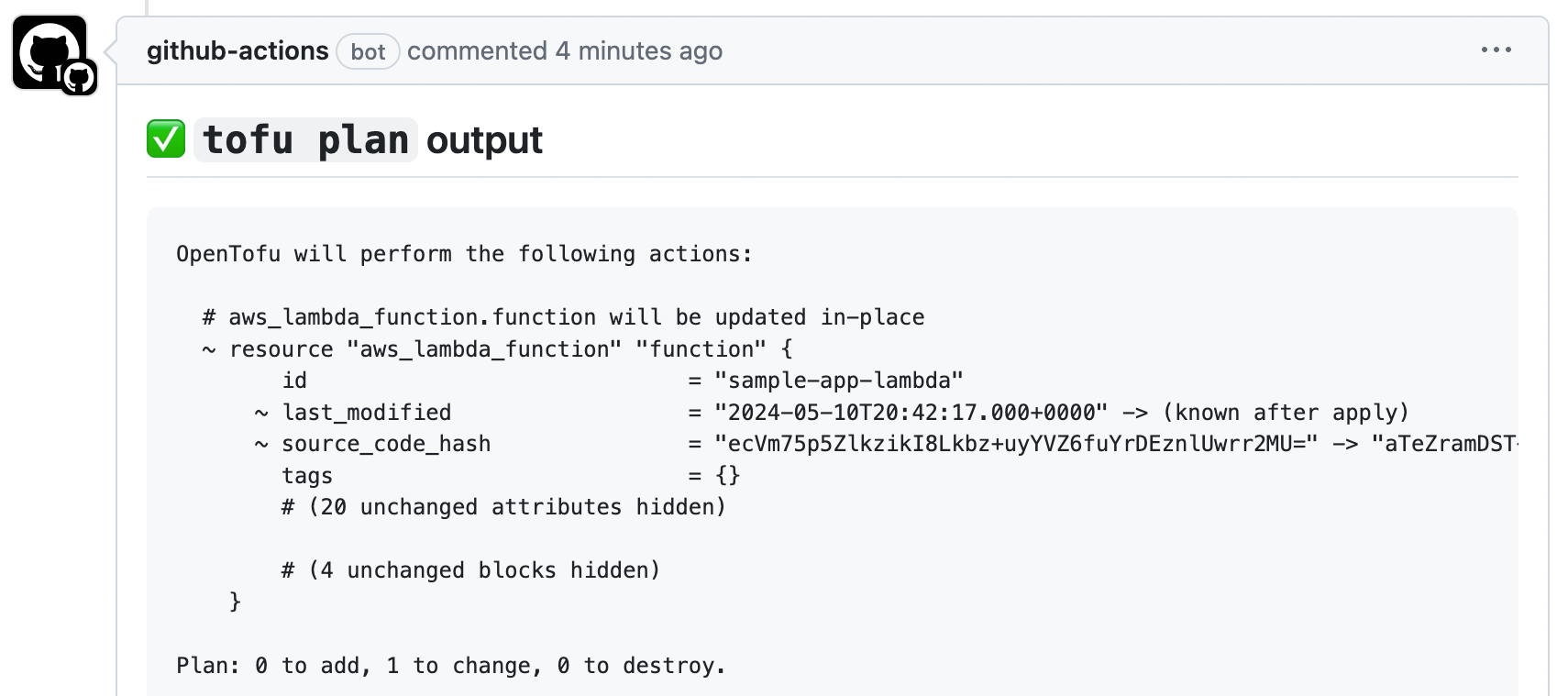
plan output to open PRsNow you can review the code changes, test results, and plan output, and if everything looks good, merge the PR. This will kick off the apply workflow, and after a minute or two, it should post a comment with the apply output, as shown in Figure 48:
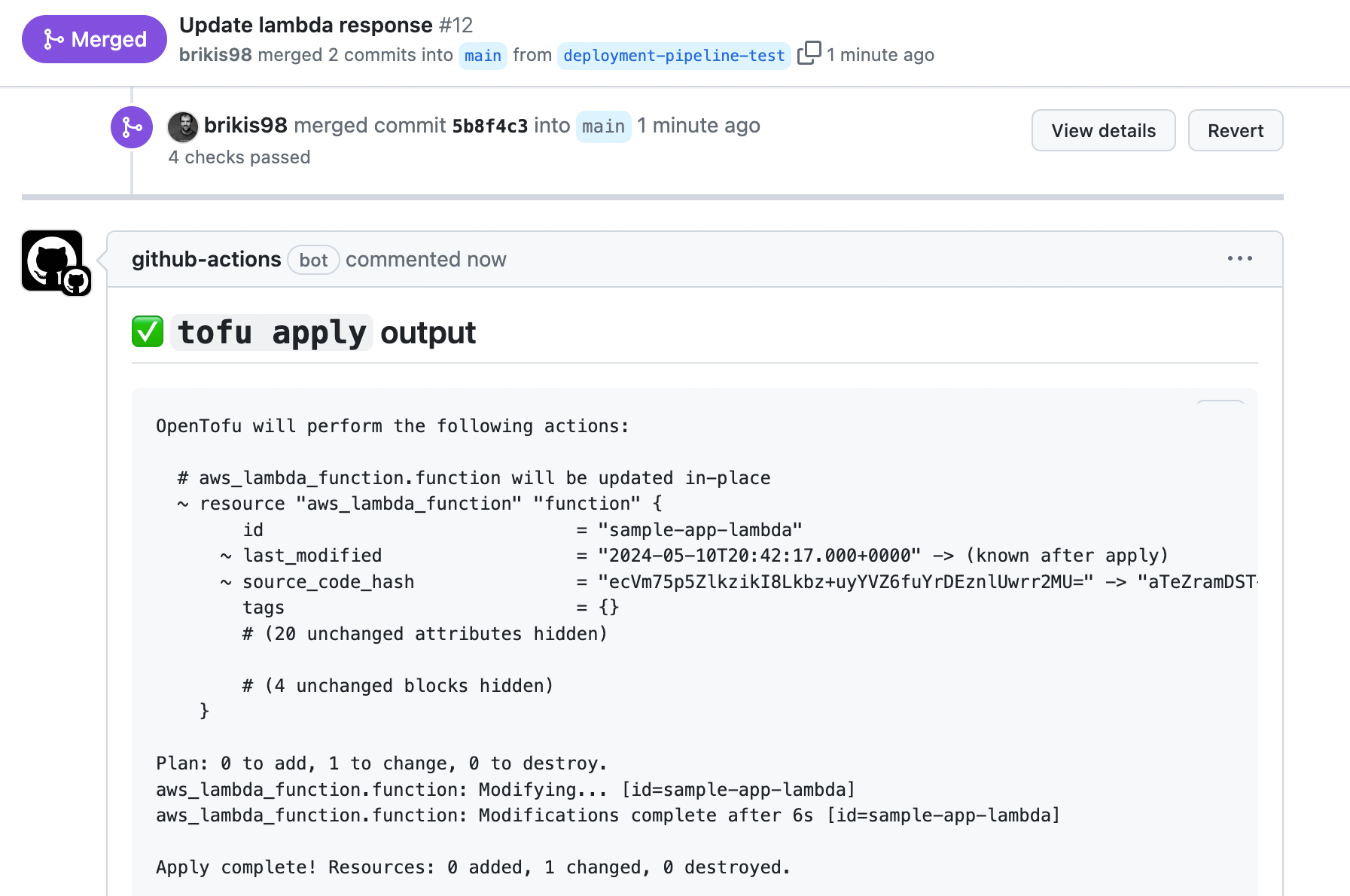
apply output to merged PRsCongrats, you now have a basic deployment pipeline in place for your lambda-sample module! It runs tests, it runs plan, and it runs apply. When you’re done testing, to clean everything up, run tofu destroy in the lambda-sample and ci-cd-permissions folders, and either delete the workflow YAML files in the .github/workflows folder, or disable those workflows in the GitHub UI.
Get your hands dirty Here are a few exercises you can try at home to go deeper:
|
Now that you’ve seen the basics of deployment pipelines, and an example of how to implement one, let’s go through some recommendations for how to make your pipelines more effective.
Deployment Pipeline Recommendations
A deployment pipeline can either be an asset that allows your whole company to move faster, or a pile of spaghetti code that is brittle, confusing, and slows everyone down. There are three patterns I recommend to most companies that may help you create pipelines of the former type:
Automate all the steps that can be automated
Deploy only from a deployment server
Protect the deployment server
The following sections will take a brief look at each of these.
Automate all the steps that can be automated
It’s only continuous delivery if it is fast, reliable, and sustainable. It’s unlikely you can achieve these three properties if your deployment process relies on a bunch of manual steps. We lowly humans usually aren’t that fast, we make mistakes all the time, and we get tired and frustrated from doing the same tedious process over and over again. On the other hand, these three properties are exactly where computers shine: they can do things quickly, without mistakes, and without complaining. Therefore, let computers do what computers do best, and automate every step that can be automated (i.e., just about everything other than writing and reviewing code).
Note that I really do mean every step. The goal is to get as close to a "push button" deploy as possible. There is a surprisingly big gap between a pipeline that is mostly automated, but still requires a few manual steps here and there, and one that is fully automated. If your pipeline relies on even a few manual steps, it can dramatically reduce the effectiveness of your ability to deliver software. Something magical happens when you get to full automation. It’s only when the whole pipeline runs from pushing a single button, that you get a CD pipeline that is fast, reliable, and sustainable; that you have environments that are truly reproducible; that you can achieve results like the companies mentioned in The Impact Of World-Class Software Delivery, who are able to deploy thousands of times per day.
Deploy only from a deployment server
Not only should most of your deployment pipeline be automated, but in most cases, all of that automation should only run on a dedicated deployment server and not any developer’s computer. There are three reasons for this:
- Full automation
As discussed in the previous section, it’s not continuous delivery if it’s not fast, reliable, and sustainable, and it won’t be fast, reliable, and sustainable if it relies on a developer doing something manually on their computer. Forcing the pipeline to run on a dedicated deployment server ensures that you really are automating all the things that can be automated.
- Repeatability
If developers run deployments from their own computers, you’ll run into problems due to differences in how their computers are configured: different operating systems, different dependency versions (e.g., different versions of OpenTofu or Node.js installed locally), different configurations, and differences in what’s actually being deployed (e.g., the developer accidentally deploys a change that wasn’t committed to version control). You can eliminate all of these issues by deploying everything from a dedicated deployment server that provides a consistent, repeatable environment.
- Permissions management
Instead of giving developers permissions to deploy, you can give solely the deployment server those permissions (especially for the production environment). It’s easier to enforce good security practices for a single server than for numerous developers with production access.
Protect the deployment server
To be able to do automated deployments from a server, you have to give the server access to sensitive permissions, such as AWS credentials. In fact, to deploy arbitrary infrastructure changes—e.g., to be able to run tofu apply on arbitrary OpenTofu modules—you need arbitrary permissions, which is just a fun way of saying "admin permissions." That means deployment servers (a) provide access to powerful, sensitive permissions, (b) are accessible to every developer in your company, and (c) are designed to execute arbitrary code. That is a terrifying combination from a security perspective, and it’s why deployment servers are tempting targets for hackers.
Here are a few things you can do to protect your deployment server:
- Lock down your deployment server
Make it accessible solely over HTTPs, require all users to be authenticated, ensure all actions are logged, and so on. If possible, only allow the deployment servers to be accessed from your company’s offices or over a VPN connection (you’ll learn more about networking in Part 7).
- Lock down your version control system
Since deployment servers typically execute workflows and code in your version control system, if an attacker can slip malicious code into one of your repos, they can bypass most other protections. Therefore, it’s critical that you protect your VCS, as described in Section 4.1.3.5.
- Enforce an approval workflow
Configure your deployment pipeline to require that every deployment is approved by at least one person other than whoever requested the deployment in the first place. This ensures that if one developer account is compromised, you always have a second set of eyes to catch malicious code.
- Limit permissions before approval/merge
A common workflow is to run
planwhen you open a PR andapplyafter the PR has been merged. In this workflow, you need to ensure theplanstep only has access to read permissions, while theapplystep has access to both read and write permissions. If you use the same set of permissions for both, then a malicious actor could open a PR that immediately uses the write permissions to make whatever changes they want, bypassing all review and approval workflows.- Don’t give the deployment server long-lived credentials
Whenever possible, use automatically-managed, short-lived credentials (e.g., OIDC) instead of manually-managed, long-lived credentials (e.g., machine user access keys). That way, if a malicious actor manages to get access to those credentials, you’re limiting the window of time during which they can use them.
- Limit the permissions of each pipeline
Instead of a single deployment pipeline that deploys arbitrary code, and therefore needs arbitrary (admin) permissions, create multiple pipelines, each of which is designed for specific tasks. You might partition your pipelines based on the type of task (e.g., deploying apps, databases, networking) or by team (e.g., search team, analytics team, networking team), and the idea is to grant each pipeline the minimal set of permissions it needs for that set of tasks. This limits the damage an attacker can do from compromising any single pipeline.
- Limit what the pipeline can do with its permissions
In addition to limiting the permissions you grant to each pipeline, you can also limit what developers can do with those permissions. For example, you might not want developers to be able to execute arbitrary code in pipelines that have access to powerful permissions, so you can add checks (e.g., using tools like OPA) that developers only run specific commands (e.g.,
tofu apply), on code from specific repos, specific branches, and specific folders. You should also lock down the workflow definitions themselves, so only a trusted set of admins can update them, and only with PR approval from at least one other admin (see GitHub’s push rulesets for a way to lock down who can edit specific file paths).
Creating reliable deployment pipelines is a lot of work. This shouldn’t be too surprising, as what you’re effectively trying to do is to capture your company’s processes, rules, and culture in the form of Bash scripts and YAML workflow files. That isn’t easy. But it’s worth it. Think of it this way: your infrastructure code and your CI / CD pipeline are essentially your company’s custom API for shipping software. Get the API right, and as you saw in The Impact Of World-Class Software Delivery, you can accelerate your company by a factor of 10x, 100x, or more.
Conclusion
In this blog post, you made great strides in automating your entire SDLC through the use of CI/CD, allowing your team to work and collaborate as per the 5 key takeaways from this blog post:
Ensure all developers merge all their work together on a regular basis, typically daily or multiple times per day.
Use a self-testing build after every commit to ensure your code is always in a working and deployable state.
Use branch by abstraction and feature toggles to make large-scale changes while still merging your work on a regular basis.
Use machine user credentials or automatically-provisioned credentials to authenticate from a CI server or other automations.
Ensure you can deploy to production at any time in a manner that is fast, reliable, and sustainable.
One of the surprising realizations of real-world systems is that agility requires safety. With cars, speed limits are determined not by the limits of engines—many cars can go over 100 mph—but by the safety mechanisms we have (e.g., brakes, bumpers, seat belts). The same is true with software delivery. The limit of how fast you can build software is usually not determined by how fast a developer can build new features, but by how quickly you can get those features to your users without causing bugs, outages, security incidents, and other problems.
This is why CI/CD is all about putting safety mechanisms in place, such as automated tests, code reviews, and feature toggles, so that you can release software faster without putting your product and users at risk. The more you can limit the risk—the safer you can make it for developers to release features—the faster you can go. This is why virtually all the companies you heard about in The Impact Of World-Class Software Delivery use CI/CD.
As your company grows, you’re going to start to hitting new bottlenecks that limit your ability to go fast. Some of these bottlenecks will be from forces outside your company: more users, more load, more requirements. Some of these bottlenecks will be from forces within your company: more products, more teams, more developers. To be able to handle these new demands, you will need to learn how to work with multiple environments and multiple teams, which is the focus of Part 6.
Update, June 25, 2024: This blog post series is now also available as a book called Fundamentals of DevOps and Software Delivery: A hands-on guide to deploying and managing software in production, published by O’Reilly Media!

{kind=link}